cdf
累積分布関数
構文
説明
y = cdf(___,'upper') は、極端に上裾にある確率をより正確に計算するアルゴリズムを使用して cdf の補数を返します。'upper' は、前の構文のどの入力引数にも従うことができます。
例
分布名 'Normal' と分布パラメーターを指定して、正規分布の cdf 値を計算します。
cdf を計算する値が含まれている入力ベクトル x を定義します。
x = [-2,-1,0,1,2];
平均 が 1、標準偏差 が 5 に等しい正規分布の cdf 値を計算します。
mu = 1;
sigma = 5;
y = cdf('Normal',x,mu,sigma)y = 1×5
0.2743 0.3446 0.4207 0.5000 0.5793
y の各値は、入力ベクトル x の値に対応しています。たとえば、"x" 値が 1 の場合、対応する cdf 値 "y" は 0.5000 です。
正規分布オブジェクトを作成し、そのオブジェクトを使用して正規分布の cdf 値を計算します。
平均 が 1、標準偏差 が 5 に等しい正規分布オブジェクトを作成します。
mu = 1; sigma = 5; pd = makedist('Normal','mu',mu,'sigma',sigma);
cdf を計算する値が含まれている入力ベクトル x を定義します。
x = [-2,-1,0,1,2];
"x" の値における正規分布の cdf 値を計算します。
y = cdf(pd,x)
y = 1×5
0.2743 0.3446 0.4207 0.5000 0.5793
y の各値は、入力ベクトル x の値に対応しています。たとえば、"x" 値が 1 の場合、対応する cdf 値 "y" は 0.5000 です。
レート パラメーター が 2 に等しいポアソン分布オブジェクトを作成します。
lambda = 2; pd = makedist('Poisson','lambda',lambda);
cdf を計算する値が含まれている入力ベクトル x を定義します。
x = [0,1,2,3,4];
x の値におけるポアソン分布の cdf 値を計算します。
y = cdf(pd,x)
y = 1×5
0.1353 0.4060 0.6767 0.8571 0.9473
y の各値は、入力ベクトル x の値に対応しています。たとえば、x 値が 3 の場合、対応する cdf 値 y は 0.8571 です。
また、確率分布オブジェクトを作成せずに同じ cdf 値を計算することもできます。関数 cdf を使用し、レート パラメーター について同じ値を使用してポアソン分布を指定します。
y2 = cdf('Poisson',x,lambda)y2 = 1×5
0.1353 0.4060 0.6767 0.8571 0.9473
cdf の値は、確率分布オブジェクトを使用して計算した値と同じです。
標準正規分布オブジェクトを作成します。
pd = makedist('Normal')pd =
NormalDistribution
Normal distribution
mu = 0
sigma = 1
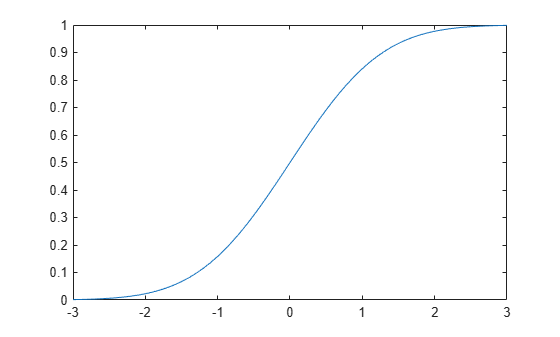
x 値を指定し、累積分布関数を計算します。
x = -3:.1:3; p = cdf(pd,x);
標準正規分布の累積分布関数をプロットします。
plot(x,p)
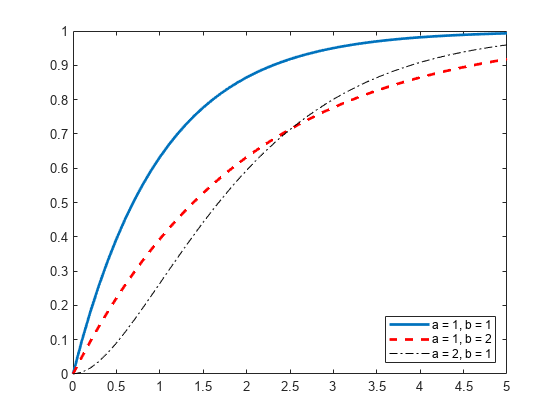
3 つのガンマ分布オブジェクトを作成します。1 つ目では、既定のパラメーター値を使用します。2 つ目では、a = 1 と b = 2 を指定します。3 つ目では、a = 2 と b = 1 を指定します。
pd_gamma = makedist('Gamma')pd_gamma =
GammaDistribution
Gamma distribution
a = 1
b = 1
pd_12 = makedist('Gamma','a',1,'b',2)
pd_12 =
GammaDistribution
Gamma distribution
a = 1
b = 2
pd_21 = makedist('Gamma','a',2,'b',1)
pd_21 =
GammaDistribution
Gamma distribution
a = 2
b = 1
x 値を指定し、各分布の累積分布関数を計算します。
x = 0:.1:5; cdf_gamma = cdf(pd_gamma,x); cdf_12 = cdf(pd_12,x); cdf_21 = cdf(pd_21,x);
形状パラメーター a および b に異なる値を指定する場合は、プロットを作成してガンマ分布の累積分布関数の変化を可視化します。
figure; J = plot(x,cdf_gamma); hold on; K = plot(x,cdf_12,'r--'); L = plot(x,cdf_21,'k-.'); set(J,'LineWidth',2); set(K,'LineWidth',2); legend([J K L],'a = 1, b = 1','a = 1, b = 2','a = 2, b = 1','Location','southeast'); hold off;
0.1 および 0.9 という累積確率でパレート分布の裾を 分布に当てはめます。
t = trnd(3,100,1); obj = paretotails(t,0.1,0.9); [p,q] = boundary(obj)
p = 2×1
0.1000
0.9000
q = 2×1
-1.8487
2.0766
q の値での累積分布関数を計算します。
cdf(obj,q)
ans = 2×1
0.1000
0.9000
入力引数
出力引数
代替機能
cdfは、名前nameによって指定された分布、または確率分布オブジェクトpdのいずれも受け入れる汎用関数です。正規分布の場合はnormcdf、二項分布の場合はbinocdfなど、分布特有の関数を使用する方が高速です。分布特有の関数の一覧については、サポートされている分布を参照してください。確率分布の累積分布関数 (cdf) または確率密度関数 (pdf) のプロットを対話的に作成するには、確率分布関数ツールを使用します。