負の二項分布
定義
負の二項分布確率密度関数は、次のとおりです。
ここで、x ≥ 0 であり、q = 1 – p です。x が整数でない場合、確率 y はゼロです。
"r" が整数でない場合、確率密度関数の定義の二項係数は等価な式で置き換えられます。
背景
最も簡単な形 (r が整数の場合) では、負の二項分布は、同じ試行を繰り返す場合の独立試行において、指定した回数の成功が起こるまでの失敗数 x をモデル化します。そのパラメーターは、一回の試行での成功の確率 p と成功の回数 r です。負の二項分布は、特に r = 1 の場合に、幾何分布 になります。幾何分布は、最初の成功までの失敗の数をモデル化します。
より一般には、r は負の整数値をとれます。この形式の負の二項分布には、繰り返しの試行という解釈がありません。しかし、ポアソン分布 のように、計数データのモデリングに便利です。負の二項分布は、ポアソン分布よりも一般的であるのは、負の二項分布は、その平均よりも分散が大きくなるため、ポアソン分布の仮定を満たさない計数データに適する可能性があるためです。極限において、r が増加して無限大に近づくにつれ、負の二項分布はポアソン分布に近づきます。
パラメーター
負の二項分布は、次のパラメーターを使用します。
| パラメーター | 説明 | サポート |
|---|---|---|
| r | 成功回数 | |
| p | 成功確率 |
負の二項分布のパラメーター
負の二項分布のパラメーターを調べます。
混雑したハイウェイでの自動車事故数のデータを収集し、1 日あたりの事故発生回数のモデル化を考えているとします。これらは計数データであり、自動車数は非常に多くても、特定の自動車に関する事故の確率は小さいため、ポアソン分布の使用を考えるかもしれません。しかし、事故が起こる確率は、天候や交通量が変化すると日によって変化する可能性があるため、ポアソン分布に必要な仮定は満たされていません。特に、この種の計数データの分散は、平均を大きく上回ることがあります。下記のデータは、この効果を表しています。すなわち、たいていの日は事故は少ないかまったくなく、多数になる日がわずかにあります。
accident = [2 3 4 2 3 1 12 8 14 31 23 1 10 7 0]; m = mean(accident)
m = 8.0667
v = var(accident)
v = 79.3524
負の二項分布は、ポアソン分布よりも一般的であり、ポアソン分布が適切でない場合に、計数データに便利な場合もあります。関数nbinfitは、負の二項分布のパラメーターの最尤推定と信頼区間を返します。データ accident の当てはめの結果を確認します。
[phat,pci] = nbinfit(accident)
phat = 1×2
1.0060 0.1109
pci = 2×2
0.2152 0.0171
1.7968 0.2046
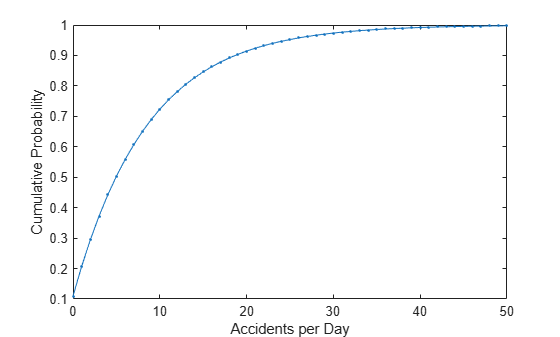
この場合、個々のパラメーターに物理的な解釈を与えることは難しいです。しかし、推定パラメーターは、毎日の事故数のモデルで使うこともできます。たとえば、推定される累積確率関数のプロットは、ある日に事故が起こらないという可能性は 10% と推定できる一方で、20 あるいはより多くの事故が起こる可能性もおよそ 10% あるということを示します。
plot(0:50,nbincdf(0:50,phat(1),phat(2)),".-"); xlabel("Accidents per Day") ylabel("Cumulative Probability")
例
負の二項分布の確率密度関数の計算とプロット
望ましい成功回数のパラメーター r について、4 つの異なる値を使用して確率密度関数を計算し、プロットします。使用する値は .1、1、3、6 です。ケースごとに、成功の確率 p は .5 です。
x = 0:10; plot(x,nbinpdf(x,.1,.5),'s-', ... x,nbinpdf(x,1,.5),'o-', ... x,nbinpdf(x,3,.5),'d-', ... x,nbinpdf(x,6,.5),'^-'); legend({'r = .1' 'r = 1' 'r = 3' 'r = 6'}) xlabel('x') ylabel('f(x|r,p)')
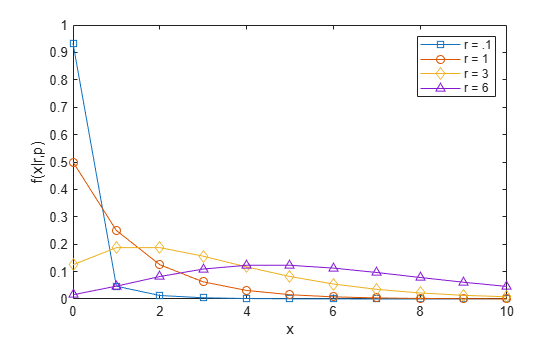
プロットから、負の二項分布はかなり歪んだ形状からほぼ対称な形状まで、r の値に応じてさまざまに変化する可能性があることがわかります。