icdf
逆累積分布関数
構文
説明
例
分布名 'Normal' と分布パラメーターを指定して、正規分布の icdf 値を計算します。
入力ベクトル p を定義して、icdf を計算する確率値を格納します。
p = [0.1,0.25,0.5,0.75,0.9];
平均 が 1、標準偏差 が 5 に等しい正規分布の icdf 値を計算します。
mu = 1;
sigma = 5;
y = icdf('Normal',p,mu,sigma)y = 1×5
-5.4078 -2.3724 1.0000 4.3724 7.4078
y の各値は、入力ベクトル x の値に対応しています。たとえば、"x" 値が 1 の場合、対応する icdf 値 "y" は 7.4078 です。
正規分布オブジェクトを作成し、そのオブジェクトを使用して正規分布の icdf 値を計算します。
平均 が 1、標準偏差 が 5 に等しい正規分布オブジェクトを作成します。
mu = 1; sigma = 5; pd = makedist('Normal','mu',mu,'sigma',sigma);
入力ベクトル p を定義して、icdf を計算する確率値を格納します。
p = [0.1,0.25,0.5,0.75,0.9];
"p" の値における正規分布の icdf 値を計算します。
x = icdf(pd,p)
x = 1×5
-5.4078 -2.3724 1.0000 4.3724 7.4078
"x" の各値は、入力ベクトル "p" の値に対応しています。たとえば、"p" の値が 0.9 である場合、対応する icdf 値 "x" は 7.4078 です。
レート パラメーター が 2 に等しいポアソン分布オブジェクトを作成します。
lambda = 2; pd = makedist('Poisson','lambda',lambda);
入力ベクトル p を定義して、icdf を計算する確率値を格納します。
p = [0.1,0.25,0.5,0.75,0.9];
p の値におけるポアソン分布の icdf 値を計算します。
x = icdf(pd,p)
x = 1×5
0 1 2 3 4
x の各値は、入力ベクトル p の値に対応しています。たとえば、p の値が 0.9 である場合、対応する icdf 値 x は 4 です。
また、確率分布オブジェクトを作成せずに同じ icdf 値を計算することもできます。関数 icdf を使用し、レート パラメーター について同じ値を使用してポアソン分布を指定します。
x2 = icdf('Poisson',p,lambda)x2 = 1×5
0 1 2 3 4
icdf の値は、確率分散オブジェクトを使用して計算した値と同じです。
標準正規分布オブジェクトを作成します。
pd = makedist('Normal')pd =
NormalDistribution
Normal distribution
mu = 0
sigma = 1
上限および下限の 2.5% の値を計算して、標準正規分布をもつ検定統計量の有意水準 5% における棄却限界値を判定します。
x = icdf(pd,[.025,.975])
x = 1×2
-1.9600 1.9600
累積分布関数をプロットして棄却限界を塗りつぶします。
p = normspec(x,0,1,'outside')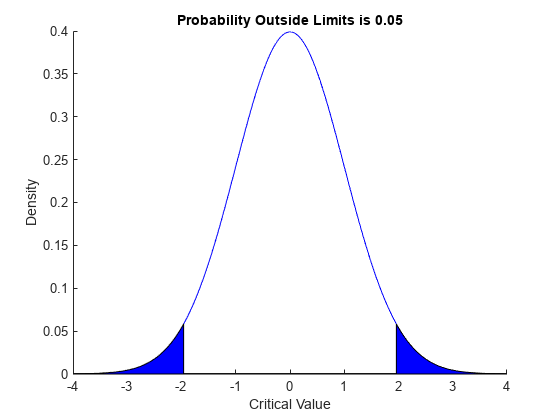
p = 0.0500
入力引数
出力引数
代替機能
icdf は、名前 name によって指定された分布、または確率分布オブジェクト pd のいずれも受け入れる汎用関数です。正規分布の場合は norminv、二項分布の場合は binoinv など、分布特有の関数を使用する方が高速です。分布特有の関数の一覧については、サポートされている分布を参照してください。
拡張機能
バージョン履歴
R2006a より前に導入