mle
最尤推定
説明
phat = mle(data,Name=Value)
たとえば、次の名前と値の引数 Distribution、pdf、logpdf、nloglf のうちの 1 つを使用して、分布タイプを指定できます。
組み込み分布の MLE を計算するには、
Distributionを使用して、分布タイプを指定します。たとえば、Distribution="Beta"カスタム分布の MLE を計算するには、
pdf、logpdf、またはnloglfを使用して分布を定義し、Startを使用して初期パラメーター値を指定します。
例
名前と値の引数 Distribution を使用して指定した組み込み分布の MLE を計算します。
標本データを読み込みます。
load carbig変数 MPG には、さまざまな自動車モデルのガロンあたりの走行マイル数が含まれます。
MPG データのヒストグラムを描画します。
histogram(MPG)

分布はやや右に歪んでいます。正規分布などの対称分布は適切な当てはめにならない場合があります。
MPG データのブール型 XII 分布のパラメーターを推定します。
phat = mle(MPG,Distribution="burr")phat = 1×3
34.6447 3.7898 3.5722
スケール パラメーター α の MLE は 34.6447 です。ブール型 XII 分布の 2 つの形状パラメーター および の推定値は、それぞれ 3.7898 および 3.5722 です。
試行回数 = 20 および成功確率 = 0.75 の二項分布から 100 個のランダムな観測値を生成します。
rng("default") % For reproducibility data = binornd(20,0.75,100,1);
シミュレーションを実行した標本データを使用して成功確率と 99% の信頼限界を推定します。二項分布の試行回数 (NTrials) を指定する必要があります。
[phat,pci] = mle(data,Distribution="binomial",NTrials=20, ... Alpha=0.01)
phat = 0.7615
pci = 2×1
0.7361
0.7856
成功確率の推定値は 0.7615 であり、99% 信頼区間の下限と上限はそれぞれ 0.7361 と 0.7856 です。この区間は、データのシミュレーションの実行に使用される真の値に対応します。
自由度が 8、非心度パラメーターが 3 の非心カイ二乗分布から、サイズが 1000 の標本データを生成します。
rng default % for reproducibility x = ncx2rnd(8,3,1000,1);
標本データから非心カイ二乗分布のパラメーターを推定します。名前と値の引数 Distribution は、非心カイ二乗分布をサポートしていません。そのため、名前と値の引数 pdf と ncx2pdf 関数を使用して、カスタムの非心カイ二乗確率密度関数 (pdf) を定義する必要があります。カスタム分布には初期パラメーター値 (名前と値の引数 Start) も指定する必要があります。
[phat,pci] = mle(x,pdf=@(x,v,d)ncx2pdf(x,v,d),Start=[1,1])
phat = 1×2
8.1052 2.6693
pci = 2×2
7.1121 1.6025
9.0983 3.7362
自由度の推定値は 8.1052、非心度パラメーターの推定値は 2.6693 です。自由度の 95% の信頼区間は (7.1120,9.0983)、非心度パラメーターの区間は (1.6025,3.7362) です。この信頼区間には、真のパラメーター値 8 および 3 が含まれています。
標本データを読み込みます。
load readmissiontimesこのデータには、100 人の患者の再入院時間を示す ReadmissionTime が含まれています。このデータは、シミュレーションされたものです。
スケール パラメーター lambda と形状パラメーター k をもつワイブル分布のカスタム対数確率密度関数 (pdf) を定義します。
custlogpdf = @(data,lambda,k) ...
log(k)-k*log(lambda)+(k-1)*log(data)-(data/lambda).^k;カスタム分布のパラメーターを推定し、初期パラメーター値 (名前と値の引数 Start) を指定します。
phat = mle(ReadmissionTime,logpdf=custlogpdf,Start=[1,0.75])
phat = 1×2
7.5727 1.4540
カスタム分布のスケール パラメーターと形状パラメーターはそれぞれ 7.5727 と 1.4540 です。
標本データを読み込みます。
load readmissiontimesこのデータには、100 人の患者の再入院時間を示す ReadmissionTime が含まれています。このデータは、シミュレーションされたものです。
パラメーター lambda をもつポアソン分布のカスタムな負の対数尤度関数を定義します。ここで 1/lambda は分布の平均値です。カスタム関数で打ち切り情報の logical ベクトルおよびデータ頻度の整数ベクトルを使用しない場合でも、これらの値を受け入れる関数を定義する必要があります。
function y = custnloglf(lambda,data,~,~) y = -length(data)*log(lambda)+sum(lambda*data,"omitnan"); end
カスタム分布のパラメーターを推定し、初期パラメーター値 (名前と値の引数 Start) を指定します。
phat = mle(ReadmissionTime,nloglf=@custnloglf,Start=0.05)
phat = 0.1462
自由度が 10、非心度パラメーターが 5 の非心カイ二乗分布から、サイズが 1000 の標本データを生成します。
rng("default") % For reproducibility x = ncx2rnd(10,5,1000,1);
非心度パラメーターは値 5 に固定されるとします。標本データから非心カイ二乗分布の自由度を推定します。これを行うため、名前と値の引数 pdf を使用して、カスタムの非心カイ二乗 pdf を定義します。
[phat,pci] = mle(x,pdf=@(x,v)ncx2pdf(x,v,5),Start=1)
phat = 9.9307
pci = 2×1
9.5626
10.2989
非心度パラメーターの推定値は 9.9307 であり、95% 信頼区間の下限と上限は 9.5626 と 10.2989 です。この信頼区間には、真のパラメーター値 10 が含まれています。
データのスケールに適合させるためスケール パラメーターをカイ二乗分布に追加し、分布を当てはめます。
自由度が 5 のカイ二乗分布からサイズが 1000 の標本データを生成し、100 という係数でデータをスケーリングします。
rng default % For reproducibility x = 100*chi2rnd(5,1000,1);
自由度とスケーリング係数を推定します。これを行うため、名前と値の引数 pdf を使用してカスタムなカイ二乗確率密度関数を定義します。密度関数では、データを でスケーリングするために係数 が必要です。
[phat,pci] = mle(x,pdf=@(x,v,s)chi2pdf(x/s,v)/s,Start=[1,200])
phat = 1×2
5.1079 99.1681
pci = 2×2
4.6862 90.1215
5.5297 108.2146
自由度の推定値は 5.1079、スケールの推定値は 99.1681 です。自由度の 95% の信頼区間は (4.6862,5.5279)、スケール パラメーターの区間は (90.1215,108.2146) です。この信頼区間には、真のパラメーター値 5 および 100 が含まれています。
標本データを読み込みます。
load readmissiontimes;このデータには、100 人の患者の再入院時間を示す ReadmissionTime が含まれています。列ベクトル Censored には各患者の打ち切り情報が含まれ、1 は右側打ち切り観測を示し、0 は正確な再入院時間が観測されることを示します。このデータは、シミュレーションされたものです。
パラメーター lambda をもつ指数分布のカスタムな確率密度関数 (pdf) および累積分布関数 (cdf) を定義します。ここで 1/lambda は分布の平均値です。分布を打ち切られたデータ セットに当てはめるには、pdf および cdf の両方を関数 mle に渡す必要があります。
custpdf = @(data,lambda) lambda*exp(-lambda*data); custcdf = @(data,lambda) 1-exp(-lambda*data);
打ち切れらた標本データのカスタム分布のパラメーター lambda を推定します。カスタム分布の初期パラメーター値 (名前と値の引数 Start) を指定します。
phat = mle(ReadmissionTime,pdf=custpdf,cdf=custcdf, ...
Start=0.05,Censoring=Censored)phat = 0.1096
二重打ち切り生存データを生成し、このデータの組み込み分布の MLE を計算します。次に、MLE を使用して確率分布オブジェクトを作成します。
バーンバウム・サンダース分布から故障時間を生成します。
rng("default") % For reproducibility failuretime = random("BirnbaumSaunders",0.3,1,[100,1]);
分析は時間 0.1 から開始し、時間 0.9 で終了すると仮定します。この仮定は、0.1 より小さい故障時間は左側打ち切りされ、0.9 より大きい故障時間は右側打ち切りされることを意味します。
各要素が failuretime の対応する観測の打ち切りステータスを示すベクトルを作成します。–1、1、および 0 を使用して、それぞれ左側打ち切り観測値、右側打ち切り観測値、完全に観測された観測値を示します。
L = 0.1; U = 0.9; left_censored = (failuretime<L); right_censored = (failuretime>U); c = right_censored - left_censored;
二重打ち切りデータの MLE を計算します。名前と値の引数 Censoring を使用して打ち切り情報を指定します。
phat = mle(failuretime,Distribution="BirnbaumSaunders",Censoring=c)phat = 1×2
0.2632 1.3040
関数 makedist を使用し、MLE で確率分布オブジェクトを作成します。
pd = makedist("BirnbaumSaunders",beta=phat(1),gamma=phat(2))pd =
BirnbaumSaundersDistribution
Birnbaum-Saunders distribution
beta = 0.263184
gamma = 1.304
pd は、BirnbaumSaundersDistribution オブジェクトです。pd のオブジェクト関数を使用して、分布の評価と乱数の生成を実行できます。サポートされるオブジェクト関数を表示します。
methods(pd)
Methods for class prob.BirnbaumSaundersDistribution: cdf gather icdf iqr mean median negloglik paramci pdf plot proflik random std truncate var
たとえば、関数 mean および var を使用して、それぞれ分布の平均と分散を計算します。
mean(pd)
ans = 0.4869
var(pd)
ans = 0.3681
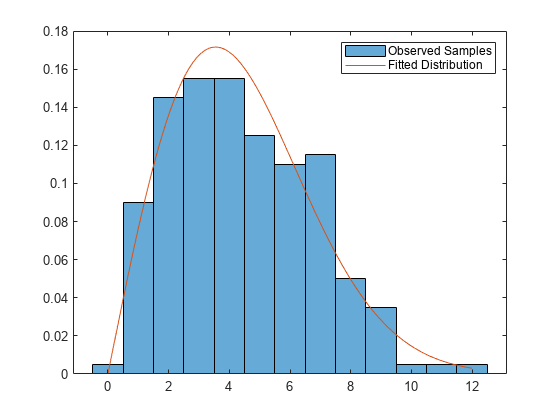
ワイブル分布に従う機械故障時間を表す標本データを生成します。
rng("default") % For reproducibility failureTimes = wblrnd(5,2,[200,1]);
観測された故障時間は最も近い秒に丸められた値であると指定します。
observed = round(failureTimes);
observed は区間打ち切りデータです。observed の観測値 t は、事象が時間 t–0.5 の後かつ時間 t+0.5 の前に発生したことを示しています。
打ち切り情報を含む 2 列の行列を作成します。
intervalTimes = [observed-0.5 observed+0.5];
故障時間は正の値である必要があります。eps より小さい値を求め、eps に変更します。
intervalTimes(intervalTimes < eps) = eps;
intervalTimesを使用して、ワイブル分布パラメーターの MLE を求めます。
params = mle(intervalTimes,Distribution="Weibull")params = 1×2
5.0067 2.0049
結果をプロットします。
figure histogram(observed,Normalization="pdf") hold on x = linspace(0,max(observed)); plot(x,wblpdf(x,params(1),params(2))) legend("Observed Samples","Fitted Distribution") hold off
有限のサポートをもつ分布から標本を生成し、反復推定処理用にカスタマイズされたオプションで MLE を計算します。
確率密度がゼロになる領域がある分布の場合、mle は密度がゼロになるパラメーターを試す可能性があり、MLE の計算が失敗する原因となります。この問題を回避するため、関数 mle を呼び出すときに、無効な関数値をチェックするオプションをオフにして、パラメーターの境界を指定できます。
スケール パラメーター 1 および形状パラメーター 1 をもつワイブル分布から、サイズが 1000 の標本データを生成します。10 を足して標本を移動させます。
rng("default") % For reproducibility data = wblrnd(1,1,[1000,1]) + 10; histogram(data,Normalization="pdf")

ヒストグラムに 10 より小さい標本はありません。この分布では 10 より小さい領域の確率がゼロであることを示しています。この分布は 3 パラメーターのワイブル分布で、位置の 3 番目のパラメーターが含まれます (3 パラメーター ワイブル分布を参照)。
3 パラメーターのワイブル分布の確率密度関数 (pdf) を定義します。
custompdf = @(x,a,b,c) wblpdf(x-c,a,b);
関数 mle を使用して MLE を計算します。名前と値の引数 Options を指定して、無効な関数値をチェックするオプションをオフにします。また、名前と値の引数 LowerBound および UpperBound を使用してパラメーターの境界を指定します。スケール パラメーターと形状パラメーターは正である必要があります。位置パラメーターは標本データの最小値より小さい必要があります。
params = mle(data,pdf=custompdf,Start=[5 5 5], ... Options=statset(FunValCheck="off"), ... LowerBound=[0 0 -Inf],UpperBound=[Inf Inf min(data)])
params = 1×3
1.0258 1.0618 10.0004
関数 mle は 3 つのパラメーターの正確な推定値を計算します。反復プロセスに指定するカスタム オプションの詳細については、3 パラメーター ワイブル分布の例を参照してください。
入力引数
名前と値の引数
出力引数
詳細
ヒント
カスタム分布関数を提供するか、左側打ち切り、二重打ち切り、区間打ち切り、または打ち切られた観測値に組み込み分布を使用すると、
mleは反復最大化アルゴリズムを使用してパラメーター推定を計算します。一部のモデルやデータにおいて開始点 (Start) の選択が適切でないと、mleはグローバル最大値ではなくローカル最適値に収束したり、収束がすべて失敗する可能性があります。対数尤度がグローバル最大値近くで適切に機能する場合でも、多くの場合、アルゴリズムの収束には開始点の選択が重要です。特に、初期パラメーター値が MLE から離れている場合、分布関数のアンダーフローによって対数尤度が無制限になってしまうことがあります。
アルゴリズム
関数
mleは、負の対数尤度関数を最小化 (つまり、対数尤度関数を最大化) するか、利用できる場合は閉形式解を使用して MLE を計算します。目的関数は、分布パラメーター (θ) が与えられた場合の標本データ (X) 確率の積について対数を取り、負の値にしたものです。確率関数 P は、観測値ごとの打ち切り情報によって異なります。
完全に観測された観測 — P(x|θ) = f(x)。ここで f はパラメーター θ の確率密度関数 (pdf) です。
左側打ち切り観測 — P(x|θ) = F(x)。ここで F はパラメーター θ の累積分布関数 (cdf) です。
右側打ち切り観測 — P(x|θ) = 1 – F(x)。
xL と xU の間の区間打ち切り観測 — P(x|θ) = F(xU) – F(xL)。
打ち切りデータの場合、
mleはすべての確率が打ち切り範囲 [L,U] に含まれるように分布関数をスケーリングします。関数
mleは、厳密法が使用可能であり、かつ標本データが打ち切られておらず、左側打ち切りおよび区間打ち切り観測値を含まない場合、厳密法を使用して信頼区間pciを計算します。そうでない場合は Wald 法を使用します。厳密法が利用可能な分布は、二項分布、離散一様分布、指数分布、正規分布、対数正規分布、ポアソン分布、レイリー分布、および連続一様分布です。