分布フィッター
確率分布をデータに当てはめ
説明
分布フィッター アプリでは、MATLAB® のワークスペースからインポートしたデータに対話的な方法で確率分布を当てはめることができます。組み込まれている 22 個の確率分布から選択することも、独自のカスタム分布を作成することもできます。当てはめた分布のプロットは、データのヒストグラムに重ね合わさって表示されます。作成可能なプロットには、確率密度関数 (pdf)、累積分布関数 (cdf)、確率プロットおよび生存時間関数があります。当てはめたパラメーター値を確率分布オブジェクトとしてワークスペースにエクスポートし、オブジェクト関数を使用してさらに分析を実行できます。これらのオブジェクトの操作方法についての詳細は、確率分布の操作を参照してください。分布フィッター アプリのプログラムのワークフローについては、プログラムでの使用を参照してください。
必要な製品
MATLAB
Statistics and Machine Learning Toolbox™
分布フィッター アプリを開く
MATLAB ツールストリップ: [アプリ] タブの [数学、統計および最適化] でアプリのアイコンをクリックします。
MATLAB コマンド プロンプト: 「
distributionFitter」と入力します。
例
標本データ carsmall を読み込みます。
load carsmallガロンあたりの走行マイル数データ MPG を使用して分布フィッター アプリを開きます。
distributionFitter(MPG)
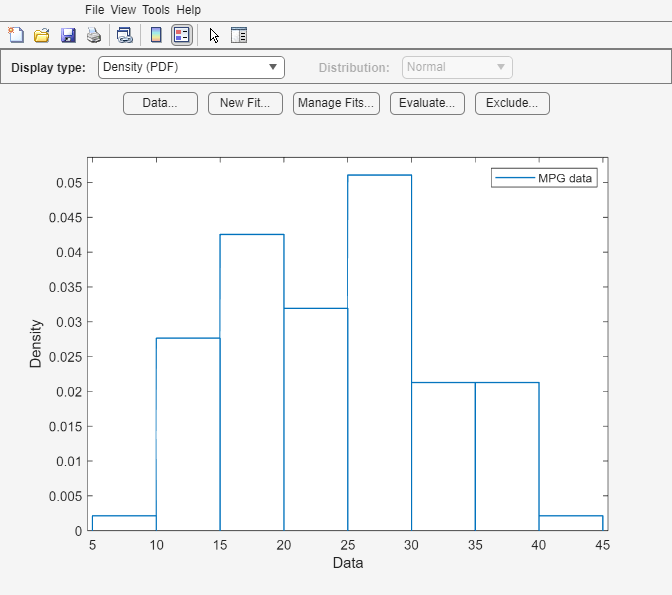
分布フィッター アプリが開き、MPG のデータが読み込まれ、密度 (PDF) プロットが表示されます。このアプリを使用すると、他のプロットを表示したり、このデータに分布を当てはめたりすることができます。
標本データを読み込みます。
load lightbulb.matデータの 1 列目には、2 種類の電球の寿命 (時間単位) が含まれています。2 列目には、電球のタイプに関する情報が含まれています。1 は蛍光灯を、0 は白熱灯を示します。3 列目には、打ち切り情報が含まれています。1 は打ち切られたデータを示し、0 は正確な故障時間を示します。このデータは、シミュレーションされたものです。
lightbulb の 1 列目を入力データ、3 列目を打ち切りデータとして使用して、分布フィッター アプリを開きます。データに lifetime という名前を付けます。
distributionFitter(lightbulb(:,1),lightbulb(:,3),[],"lifetime")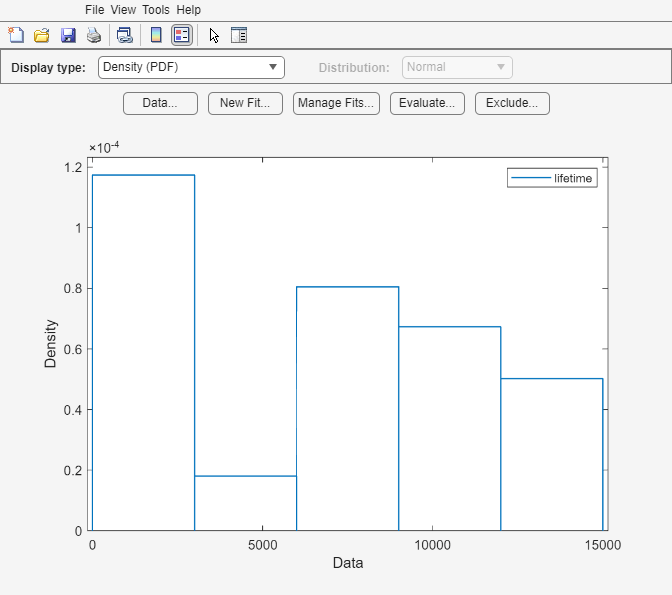
[データ] ダイアログ ボックスを開くには、[データ] をクリックします。[データ セットの管理] ペインで、データ セット lifetime の行をクリックして強調表示にします。そして、[データ セットの表示] ダイアログ ボックスを開くため、[ビュー] をクリックします。寿命データが 2 列目に、対応する打ち切りインジケーターが 3 列目に表示されます。