このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
分布フィッター アプリを使用したデータのモデリング
分布フィッター アプリを使用すると、視覚的かつ対話的な方法で一変量分布をデータに当てはめることができます。
対話的な確率分布の調査
分布フィッター アプリを使用すると、MATLAB® のワークスペースからインポートしたデータに確率分布を対話的に当てはめることができます。組み込まれている 22 個の確率分布から選択することも、独自のカスタム分布を作成することもできます。このアプリでは、pdf、cdf、確率プロット、生存時間関数などの経験分布のプロットの上に近似分布が表示されます。さらに解析するために、近似パラメーター値などの近似データをワークスペースにエクスポートできます。
分布フィッター アプリのワークフロー
確率分布を標本データに当てはめるには、次のようにします。
MATLAB のツールストリップの [アプリ] タブをクリックします。[数学、統計および最適化] グループで分布フィッター アプリを開きます。または、コマンド プロンプトで「
distributionFitter」と入力します。標本データをインポートするか、アプリで直接データ ベクトルを作成します。データ セットを管理してどれを近似するかを選択することもできます。データ セットの作成と管理を参照してください。
データについて新しい近似を作成します。新しい近似の作成を参照してください。
近似の結果を表示します。密度 (pdf)、累積確率 (cdf)、分位数 (逆 cdf)、確率プロット (複数の分布から 1 つを選択)、生存時間関数および累積ハザードの表示を選択できます。結果の表示を参照してください。
アプリ内で別の近似を作成して複数の近似を管理することができます。近似の管理を参照してください。
近似について確率関数を評価します。密度 (pdf)、累積確率 (cdf)、分位数 (逆 cdf)、生存時間関数および累積ハザードの評価を選択できます。近似の評価を参照してください。
特定のデータを除外して近似を改善します。除外するデータの境界を指定するか、標本データの値のプロットを使用してグラフィカルにデータを除外できます。データの除外を参照してください。
後から開くことができるように、現在の分布フィッター アプリのセッションを保存します。セッションの保存と読み込みを参照してください。
データ セットの作成と管理
[データ] ダイアログ ボックスを開くには、分布フィッター アプリの [データ] をクリックします。

データのインポート
MATLAB のワークスペースからベクトルをインポートしてデータ セットを作成するには、[ワークスペース ベクトルのインポート] オプションを使用します。
[データ] ― [データ] フィールドのドロップダウン リストには、1 行 1 列の行列 (スカラー値)を除いて、MATLAB のワークスペースにあるすべての行列とベクトルの名前が含まれています。近似するデータが含まれている配列を選択します。インポートするデータはベクトルでなければなりません。[データ] フィールドの行列を選択する場合、既定の設定では行列の 1 列目がインポートされます。行列の別の列や行を選択するには、[列または行の選択] をクリックします。行列が [列または行の選択] ダイアログ ボックスに表示されます。行または列を選択するには、その行または列を強調表示します。
あるいは、[データ] フィールドに有効な MATLAB 式を入力できます。
[データ] フィールドでベクトルを選択すると、[データ プレビュー] ペインにデータのヒストグラムが表示されます。
[打ち切り] ― 打ち切られた点がデータ セットに含まれている場合、データの打ち切り要素を指定するブール ベクトル (データ ベクトルと同じサイズ) を入力します。打ち切りベクトルの
1は、データ ベクトルの対応する要素が打ち切られていることを示します。0は要素が打ち切られていないことを示します。行列を入力する場合、[列または行の選択] をクリックすることにより列または行を選択できます。打ち切られたデータがない場合は、[打ち切り] フィールドを空白のままにしてください。[頻度] ― データ ベクトルの対応する要素の頻度を指定するために、データ ベクトルと同じサイズの正の整数のベクトルを入力します。たとえば、頻度ベクトルの 15 番目の要素の値が
7の場合、データ ベクトルの 15 番目の要素に対応するデータ点が 7 つあることを指定します。データ ベクトルの要素の頻度がすべて 1 の場合は、[頻度] フィールドを空白のままにします。[データ セット名] ― ワークスペースからインポートするデータ セットの名前 (例:
My data) を入力します。
これらのフィールドに情報を入力して [データ セットの作成] をクリックすると、データ セット My data が作成されます。
データ セットの管理
作成したデータ セットを表示および管理するには、[データ セットの管理] ペインを使用します。データ セットを作成すると、その名前が [データ セット] リストに表示されます。次の図は、データ セット My data を作成した後の [データ セットの管理] ペインを示します。
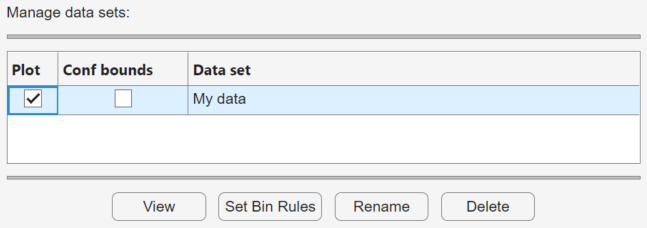
[データ セット] リストの各データ セットに対して、次の操作ができます。
分布フィッター アプリのメイン ウィンドウにデータのプロットを表示するには、[プロット] チェック ボックスをオンにします。新しいデータ セットを作成する場合、既定の設定では [プロット] が選択されます。[プロット] チェック ボックスをオフにすると、メイン ウィンドウのプロットからデータが削除されます。表示されたプロットのタイプを、メイン ウィンドウの [表示タイプ] フィールドに指定できます。
[プロット] が選択されると、[信頼限界] も選択可能になり、メイン ウィンドウでプロットの信頼区間限界を表示できます。信頼限界のこれらの上下限は、これらの関数の経験的上の推定を含みます。境界が表示されるのは、メイン ウィンドウで [表示タイプ] を次のいずれかに設定した場合だけです。
累積確率 (CDF)生存時間関数累積ハザード
分布フィッター アプリでは、密度 ([PDF])、分位数 ([逆 CDF]) または確率プロットに信頼限界を表示できません。[信頼限界] チェック ボックスをオフにすると、メイン ウィンドウのプロットから信頼限界が削除されます。
リストからデータ セットを選択するときに、以下のボタンを使用できます。
[ビュー] ― 新しいウィンドウの表にデータを表示します。
[ビン ルールの設定] ― 密度 (PDF) プロットに使用されるヒストグラムのビンを定義します。
[名前の変更] ― データ セットの名前を変更します。
[削除] ― データ セットを削除します。
ビンのルールの設定
データ セットのヒストグラムに対してビンのルールを設定するには、[ビン ルールの設定] をクリックして [ビン ルールの設定] ダイアログ ボックスを開きます。

次の規則から選択できます。
[フリードマン・ダイアコニスの法則] ― 標本のサイズとデータの広がりに基づき、ビンの幅と位置を自動的に選択するアルゴリズム。これは、整数のみで構成されるデータを除くすべてのデータに対する既定のルールです。
[Scott ルール] ― ほぼ正規分布するデータのためのアルゴリズム。このアルゴリズムは、ビンの幅と位置を自動的に選択します。
[ビンの数] ― ビンの数を入力します。すべてのビンの幅は同じです。
[整数を中心とするビン] ― 中心が整数の点にあるビンを指定します。これは、整数のみで構成されるデータに対する既定のルールです。
[ビンの幅] ― 各ビンの幅を入力します。このオプションを選択すると、次のオプションが選択できるようになります。
[自動ビン配置] ― [ビンの幅] の整数倍の位置にビンの端を配置します。
[ビンの境界] ― ビンの境界を指定するスカラーを入力します。各ビンの境界は、このスカラーと [ビンの幅] の整数倍の和に等しいです。
以下を行うこともできます。
[既存のデータ セットすべてに適用] ― 該当のルールがすべてのデータ セットに適用されます。このオプションを選択しない場合、ルールは [データ] ダイアログ ボックスで現在選択されているデータ セットにのみ適用されます。
[既存の設定として保存] — 現在のルールが、作成するすべての新規のデータ セットに適用されます。メイン ウィンドウの [ツール] メニューから [既定のビン幅ルールを設定] を選択すると、既定のビンの幅に関するルールを設定できます。
既定のビン ルールの設定
アプリで作成されるすべてのヒストグラムに対して既定のビン ルールを設定するには、メイン ウィンドウの [ツール] メニューで [既定のビン ルールの設定] をクリックします。


ここに、ルールを [自動] として設定するための追加のオプションがあります。これを選択すると、整数のみで構成されるデータに対する既定のビン ルールは [整数を中心とするビン]、それ以外のタイプのデータに対する既定のビン ルールは [フリードマン・ダイアコニスの法則] になります。
新しい近似の作成
メイン ウィンドウの上部にある [新規近似] ボタンをクリックして、[新規近似] ダイアログ ボックスを開きます。データ セットの My data を作成すると、[データ] フィールドに表示されます。
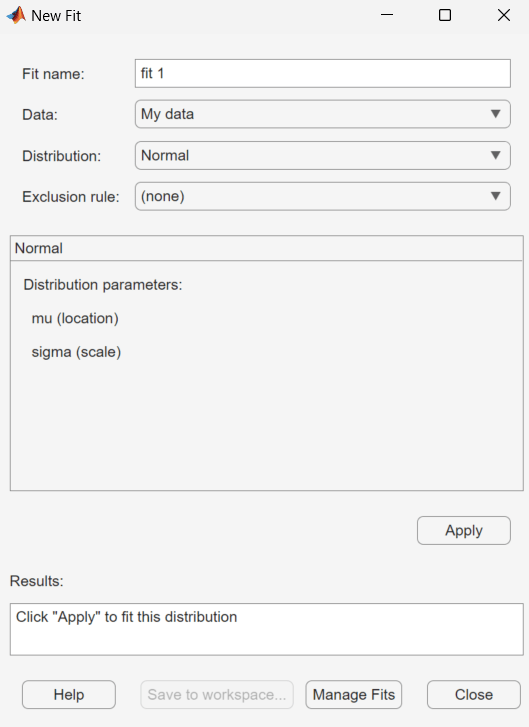
| フィールド名 | 説明 |
|---|---|
| 近似名 | 近似の名前を入力します。 |
| データ | 分布を近似させるデータ セットをドロップダウン リストから選択します。 |
| 分布 | [分布] ドロップダウン リストから、当てはめる分布のタイプを選択します。 [分布] フィールドには、選択したデータ セットの値に適用される分布のみが表示されます。たとえば、ゼロまたは負の値がデータに含まれている場合、正の分布は表示されません。 パラメトリックまたはノンパラメトリック分布のいずれかを指定できます。ドロップダウン リストから [パラメトリック分布] を選択すると、そのパラメーターの説明が表示されます。分布フィッターは、これらのパラメーターを推定して分布をデータ セットに当てはめます。二項分布または一般化極値分布を選択した場合、いずれかのパラメーターについて固定値を指定する必要があります。このペインには、パラメーターを指定するためのテキスト フィールドがあります。
|
| 除外規則 | データを除外するための規則を指定します。除外規則を作成するには、分布フィッター アプリで [除外] をクリックします。詳細は、データの除外を参照してください。 |
新しい近似の適用
分布を適用するためには、[適用] をクリックします。パラメトリックな近似の場合、[結果] ペインが推定されたパラメーターの値を表示します。ノンパラメトリックな近似の場合、[結果] ペインが近似についての情報を表示します。
[適用] をクリックすると、分布のプロットおよび対応するデータが分布フィッター アプリに表示されます。
メモ:
[適用] をクリックすると、ダイアログ ボックスのタイトルが [近似の編集] に変わります。ここで、作成した近似に変更を行い、保存するために再び [適用] をクリックすることができます。[近似の編集] ダイアログ ボックスの終了後に近似を編集する必要がある場合はいつでも [近似マネージャー] ダイアログ ボックスから再度開けます。
近似の適用後は、[ワークスペースに保存] をクリックすると、確率分布オブジェクトを使用して情報をワークスペースに保存できます。
利用可能な分布
分布フィッター アプリで使用できるすべての分布は、Statistics and Machine Learning Toolbox™ の他の場所でもサポートされています。関数 fitdist を使用すると、このアプリでサポートされているすべての分布を近似させることができます。多くの分布には、専用の近似関数もあります。これらの関数は、分布フィッター アプリで使用できる近似の大部分を計算します。これらについては、以下のリストで参照しています。その他の近似は、分布フィッター アプリの内部の関数を使用して計算されます。
記載されている分布には、データ セットによっては利用できないものもあります。分布フィッター アプリは、データの範囲 (非負、単位間隔など) を決め、[分布] ドロップダウン リストに適切な分布を表示します。分布のデータの範囲は、以下のリストのかっこ内に記載されています。
バーンバウム・サンダース (正値) 分布。
ブール型 XII (正値) 分布
逆ガウス (正値) 分布。
ロジスティック (すべての値) 分布
対数ロジスティック (正値) 分布。
仲上 (正値) 分布。
ライス (正値) 分布
t location-scale (すべての値) 分布
ノンパラメトリック近似のオプションの詳細
[分布] フィールドで、[ノンパラメトリック] を選択すると、次の図に示すように、オプションのセットが [ノンパラメトリック] ペインに表示されます。
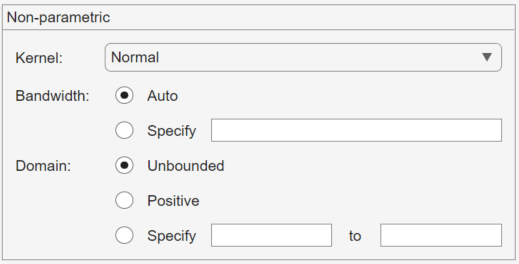
ノンパラメトリックな分布には、以下のオプションがあります。
[カーネル] ― 使用するカーネル関数のタイプ。
正規ボックス三角形Epanechnikov
[帯域幅] ― カーネル平滑化ウィンドウの帯域幅。正規密度の推定に適した既定値を使用する場合は、[自動] を選択します。[適用] をクリックすると、この値が [結果] ペインに表示されます。値を指定する場合は [指定] を選択し、複数の最頻値などの特性を明らかにするには小さい値を、近似を平滑化するには大きい値を入力します。
[領域] ― 密度として許容される x の値。
[制限なし] — 密度の範囲が実数直線全体になります。
[正] — 密度は正の値に限定されます。
[指定] — 密度の範囲の下限と上限を入力します。
[正] または [指定] を選択する場合、指定した範囲の外ではノンパラメトリックな近似の確率は 0 になります。
結果の表示
分布フィッター アプリのウィンドウには、次のプロットが表示されます。
[データ] ダイアログ ボックスで [プロット] を選択したデータ セット
[近似マネージャー] ダイアログ ボックスで [プロット] を選択した近似
以下に対する信頼限界
[データ] ダイアログ ボックスで [信頼限界] を選択したデータ セット。
[近似マネージャー] ダイアログ ボックスで [信頼限界] を選択した当てはめ。
以下のフィールドを使用できます。
表示タイプ
表示するプロットのタイプを指定するには、アプリのメイン ウィンドウにある [表示タイプ] フィールドを使用します。それぞれのタイプは、確率関数 (たとえば、確率密度関数) に対応します。次の表示タイプから選択できます。
密度 (PDF)— 近似分布の確率密度関数 (PDF) プロットを表示します。メイン ウィンドウは、確率のヒストグラムを使用してデータ セットを表示します。ここで、各四角形の高さは、ビンにあるデータ点をビンの幅で除算した分数です。これにより、四角形の領域の和が 1 に等しくなります。累積確率 (CDF)— データの累積確率プロットを表示します。メイン ウィンドウは、累積確率のステップ関数を使用してデータ セットを表示します。各ステップの高さは、確率のヒストグラムの四角形の高さの累積的な合計です。分位数 (逆 CDF)— 分位数 (逆 CDF) プロットを表示します。確率プロット— データの確率プロットを表示します。確率プロットを作成するために使用する分布のタイプは、[分布] フィールドで指定します。このフィールドは、[確率プロット]を選択した場合のみ使用できます。以下の分布を選択できます。指数極値半正規対数ロジスティックロジスティック対数正規正規レイリーワイブル
[新規近似] ダイアログ ボックスで作成したパラメトリックな当てはめに対して確率プロットを作成することもできます。このような近似を作成すると、[分布] ドロップダウン リストの下部に作成した近似が追加されます。
生存時間関数— データの生存時間関数のプロットを表示します。累積ハザード— データの累積ハザード プロットを表示します。メモ:
プロットしたデータに
0または負の値が含まれている場合、一部の分布は使用できません。
信頼限界
データ セットと近似の信頼限界は、[表示タイプ] を [累積確率 (CDF)]、[生存時間関数]、[累積ハザード] に設定した場合に、また、近似のみの信頼限界は、[分位数 (逆 CDF)] に設定した場合に表示できます。
データ セットの範囲を表示するには、[データ] ダイアログ ボックスの [データ セットの管理] ペインでデータ セットの横にある [信頼限界] を選択します。
当てはめの範囲を表示するには、[近似マネージャー] ダイアログ ボックスの当てはめの横にある [信頼限界] を選択します。信頼限界は、すべての近似のタイプで利用できるわけではありません。
範囲に信頼水準を設定するには、メイン ウィンドウの[ビュー] メニューから [信頼水準] を選択し、オプションから選びます。
近似の管理
[近似の管理] ボタンをクリックすると、[近似マネージャー] ダイアログ ボックスが開きます。

作成した近似のリストが次のオプションと共に [近似テーブル] に表示されます。
プロット — 分布フィッター アプリのメイン ウィンドウに近似のプロットを表示します。新しい近似を作成すると、既定で [プロット] が選択されます。[プロット] チェック ボックスをオフにすると、メイン ウィンドウのプロットから近似が削除されます。
信頼限界 ― [プロット] を選択した場合、[信頼限界] を選択すると信頼限界をプロットに表示できます。信頼限界は、メイン ウィンドウの [表示タイプ] を以下のいずれかに設定すると表示されます。
累積確率 (CDF)分位数 (逆 CDF)生存時間関数累積ハザード
分布フィッター アプリでは、密度 (
[PDF]) と確率プロットに信頼限界を表示できません。ノンパラメトリックな近似と一部のパラメトリックな近似では、信頼限界がサポートされていません。[信頼限界] チェック ボックスをオフにすると、メイン ウィンドウのプロットから信頼区間が削除されます。
[近似テーブル] で近似を選択すると、表の下の次のボタンが使用可能になります。
[新規近似] ― [新規近似] ウィンドウが開きます。
[コピー] ― 選択された近似のコピーを作成します。
[編集] ― 近似を編集するための [近似の編集] ダイアログ ボックスが開きます。
メモ:
[近似の編集] ダイアログ ボックスで編集できるのは、現在選択している近似だけです。別の近似を編集するには、[近似テーブル] でその近似を選択し、[編集] をクリックして別の [近似の編集] ダイアログ ボックスを開いてください。
[ワークスペースへ保存] — 選択されている近似を分布オブジェクトとして保存します。
[削除] ― 選択されている近似を削除します。
近似の評価
選択した任意のデータ点で近似分布を評価するには、[評価] ダイアログ ボックスを使用します。このダイアログ ボックスを開くには、[評価] をクリックします。
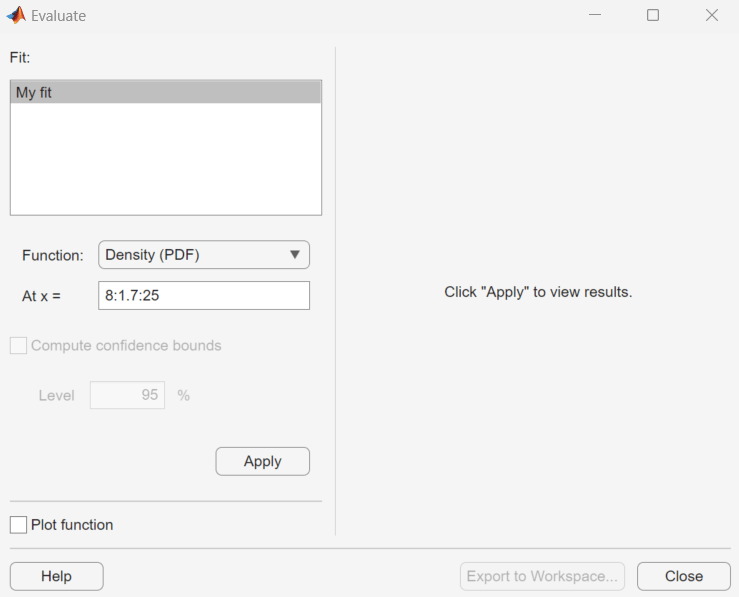
[評価] ダイアログ ボックスでは、以下の項目を選択できます。
[近似] ペイン ― 既存の近似の名前を表示します。評価する 1 つ以上の近似を選択します。プラットフォーム固有の機能を使用して、複数の近似を選択できます。
[関数] ― 近似について評価する確率関数のタイプを選択します。次の関数を使用できます。
密度 (PDF)— 確率密度関数を計算します。累積確率 (CDF)— 累積分布関数を計算します。分位数 (逆 CDF)— 分位数 (逆 CDF) 関数を計算します。生存時間関数— 生存時間関数を計算します。累積ハザード— 累積ハザード関数を計算します。ハザード率— ハザード率を計算します。
x = — 分布関数を評価する点のベクトルが含まれている点のベクトルまたはワークスペース変数の名前を入力します。[関数] を
[分位数 (逆 CDF)]に変更した場合、フィールド名は [p =] に変更されます。この場合は、確率値のベクトルを入力します。[信頼限界の計算] ― このチェック ボックスをオンにすると、選択された近似の信頼限界を計算します。このチェック ボックスが有効になるのは、[関数] を次のいずれかに設定した場合だけです。
累積確率 (CDF)分位数 (逆 CDF)生存時間関数累積ハザード
分布フィッター アプリは、ノンパラメトリック近似といくつかのパラメトリック近似の信頼限界を計算できません。これらの場合、範囲の
NaNが返されます。[水準] ― 信頼限界に対する水準を設定します。
[関数のプロット] ― このボックスを選択して、新しいウィンドウの [x =] フィールドに入力する点で評価した、分布関数のプロットを表示します。
メモ:
[信頼限界の計算]、[水準] および [関数のプロット] の設定は、分布フィッター アプリのメイン ウィンドウに表示されるプロットに影響を与えません。これらの設定は、[評価] ウィンドウで [関数のプロット] をクリックして作成するプロットのみに適用されます。
選択した近似にこれらの評価設定を適用するには、[適用] をクリックします。次の図には、近似 [My fit] の累積分布関数をベクトル 8:1.7:25 の点で評価した結果が示されています。

[近似] ペインの右にある表の列には、次の値が表示されます。
[X] ― [At x =] フィールドで入力したベクトルの要素
F(X) ― [X] の要素に対応する CDF の値
[LB] ― 信頼区間の下限 ([信頼限界の計算] を選択した場合)
[UB] ― 信頼区間の上限 ([信頼限界の計算] を選択した場合)
この表に表示されているデータを MATLAB のワークスペースの行列に格納するには、[ワークスペースにエクスポート] をクリックします。
データの除外
近似から値を除外するには、[除外] をクリックして [除外] ウィンドウを開きます。[除外] ウィンドウでは、特定のデータ値を除外するための規則を作成できます。[新規近似] ウィンドウで新しい近似を作成するときに、これらの規則を使用してデータを近似から除外できます。

除外規則を作成するには、次の操作を行います。
除外規則名 ― 除外規則の名前を入力します。
セクションの除外 ― 除外するデータの境界を指定します。
[下限: データの除外] ドロップダウン リストで [
<=] または [<] を選択し、右のフィールドにスカラー値を入力します。選択した演算子に基づいて、入力したスカラー値以下のデータまたは入力したスカラー値未満のデータが近似から除外されます。[上限: データの除外] ドロップダウン リストで [
>=] または [>] を選択し、右のフィールドにスカラー値を入力します。選択した演算子に基づいて、入力したスカラー値以上のデータまたは入力したスカラー値より大きいデータが近似から除外されます。
または
[グラフィカルに除外] をクリックしてデータ セットの値のプロットを表示し、除外するデータの境界を選択して除外規則を定義します。たとえば、「データ セットの作成と管理」で説明されているように
My dataというデータ セットを作成した場合、このデータ セットを [データの選択] ドロップダウン リストから選択してから [グラフィカルに除外] ボタンをクリックします。すると、新しいウィンドウにMy dataの値が表示されます。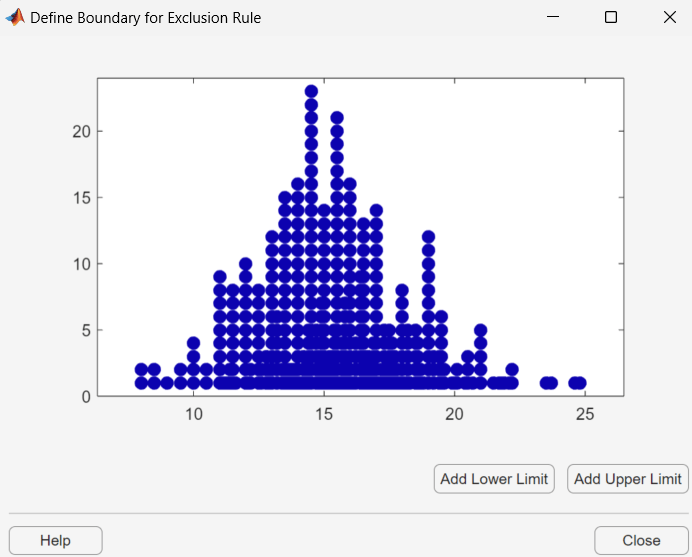
除外する範囲の下限を設定するには、[下限を追加] をクリックします。プロット ウィンドウの左側に垂直線が表示されます。次の図に示されているように、下限を設定する位置にこの線を移動します。

垂直線を移動すると、[除外] ウィンドウの [下限: データの除外] フィールドに表示される値が変化します。

表示された値は、垂直線の x 座標に相当します。
同様に、[上限を追加] をクリックしてプロット ウィンドウの右側に表示される垂直線を移動すると、除外する領域の境界の上限を設定できます。下限と上限を設定後、[閉じる] をクリックして [除外] ウィンドウに戻ります。
除外規則の作成 ― 除外するデータの範囲について下限と上限を設定してから、[除外規則の作成] をクリックして新しい規則を作成します。新しい規則の名前が [既存の除外規則] ペインに表示されます。
[既存の除外規則] ペインの除外規則を選択すると、次のボタンを使用できるようになります。
[コピー] ― 規則のコピーを作成します。その後、変更することができます。変更した規則に名前を付けて保存するには、[除外規則の作成] をクリックします。
[ビュー] ― 新しいウィンドウが開き、規則によって除外されるデータ点を確認できます。次の図は、典型的な例を示します。
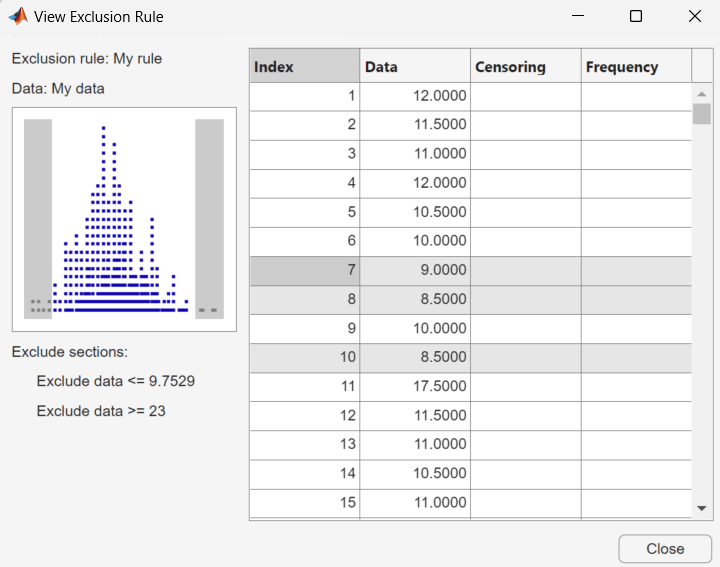
プロットの影のある領域は、どのデータ点が除外されるかを示します。右側の表では、すべてのデータ点を一覧できます。影の付いた行が、除外される点を示します。
[名前の変更] ― 規則の名前を変更します。
[削除] ― 規則を削除します。
定義した除外規則は、分布をデータに当てはめるときに使用できます。この規則は、データ セットの表示から点を除外しません。
セッションの保存と読み込み
現在のセッションの作業を保存し、以後のセッションで読み込むと、中断した場所から作業を続行できます。
セッションの保存
現在のセッションを保存するには、メイン ウィンドウの [ファイル] メニューから [セッションの保存] を選択します。ファイル名 (my_session.dfit など) を入力するためのダイアログ ボックスが表示されます。[保存] をクリックすると、現在のセッションで作成した以下の項目が保存されます。
データ セット
近似
除外規則
プロットの設定
ビン幅のルール
セッションの読み込み
前に保存したセッションを読み込むには、メイン ウィンドウの [ファイル] メニューから [セッションの読み込み] を選択します。前に保存したセッションの名前を入力します。[開く] をクリックすると、保存したセッションの情報が現在のセッションに復元されます。
分布の近似とプロットのためのファイルの作成
[ファイル] メニューの [コード生成] オプションを使用すると、次のことを行うファイルが作成されます。
現在のセッションの分布を MATLAB のワークスペースにあるデータ ベクトルに近似させる。
データと近似をプロット。
このファイルを使用すると、現在のセッションが終了した後で分布フィッター アプリを開かずに、MATLAB の標準的な Figure ウィンドウでプロットを作成できます。
たとえば、新しい近似の作成で説明されている近似を作成した場合、以下の手順に従います。
[ファイル] メニューから
[コード生成]を選択します。MATLAB のエディター ウィンドウで [ファイル]、[名前を付けて保存] を選択します。MATLAB パス上のフォルダーにファイル名を
normal_fit.mとしてファイルを保存します。
その後で、関数 normal_fit を MATLAB ワークスペースのすべてのデータ ベクトルに適用できます。たとえば、次のコマンドを実行したとします。
new_data = normrnd(4.1, 12.5, 100, 1); newfit = normal_fit(new_data) legend('New Data', 'My fit')
すると、データを近似する newfit という正規分布が生成されます。このコマンドでは、データと近似のプロットも生成されます。
newfit =
NormalDistribution
Normal distribution
mu = 5.63857 [2.7555, 8.52163]
sigma = 14.53 [12.7574, 16.8791]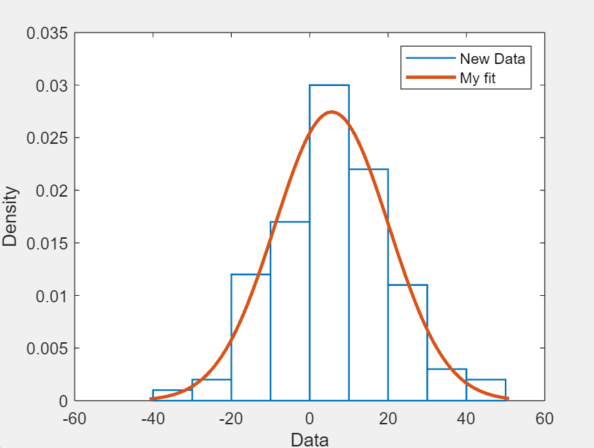
メモ:
既定の設定では、分布フィッター アプリのデータ セットと同じ名前を使用して凡例のデータにラベルが付けられます。前の例に示されているように、legend コマンドを使用するとラベルを変更できます。