分布フィッター アプリによる分布の当てはめ
この例では、分布フィッター アプリを使用して対話的に確率分布をデータに当てはめる方法を示します。
手順 1: 標本データの読み込み
標本データを読み込みます。
load carsmall手順 2: データのインポート
分布フィッター ツールを開きます。
distributionFitter
ベクトル MPG を分布フィッター アプリにインポートするため、[データ] をクリックします。[データ] ダイアログ ボックスが開きます。

[データ] フィールドは、MATLAB® ワークスペース内の数値配列をすべて表示します。ドロップダウン リストから [MPG] を選択します。選択したデータのヒストグラムが [データ プレビュー] ペインに表示されます。
[データ セット名] フィールドにデータ セットの名前 (「MPG data」など) を入力し、[データ セットの作成] をクリックします。分布フィッター アプリのメイン ウィンドウで、[データ プレビュー] ペインにヒストグラムが拡大表示されます。
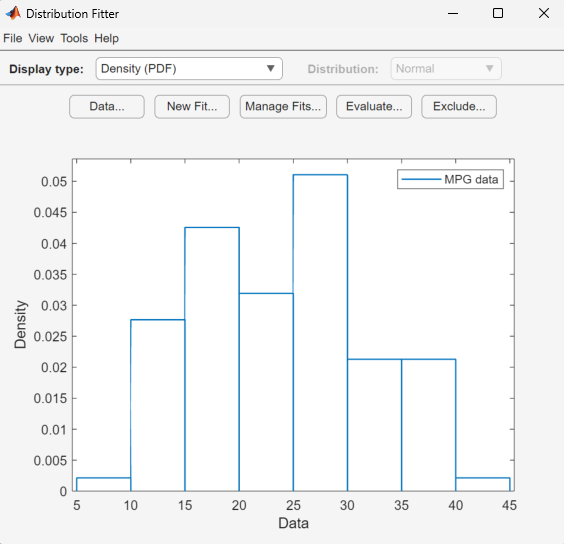
手順 3: 新しい近似の作成
分布をデータに当てはめるため、分布フィッター アプリのメイン ウィンドウで [新規近似] をクリックします。
正規分布で MPG data を近似するため、以下の手順を実行します。
[近似名] フィールドに近似の名前 (「
My fit」など) を入力します。[データ] フィールドのドロップダウン リストから [
MPG data] を選択します。[分布] フィールドのドロップダウン リストから
[正規]を選択します。[適用] をクリックします。

MPG data に最も適合する正規分布の平均値と標準偏差が [結果] ペインに表示されます。
この平均値と標準偏差による正規分布のプロットが分布フィッター アプリのメイン ウィンドウに表示されます。
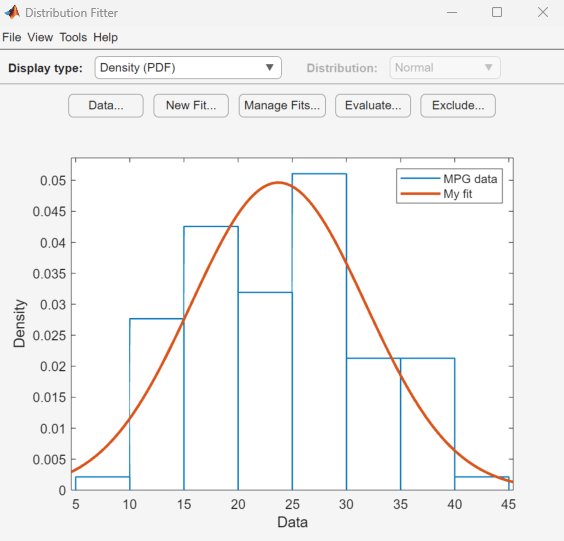
このプロットの正規分布は、MPG data にあまり適合していないように見えます。評価を向上させるため、[表示タイプ] ドロップダウン リストから [確率プロット] を選択します。[分布] ドロップダウン リストは [正規] に設定します。次の図がメイン ウィンドウに表示されます。
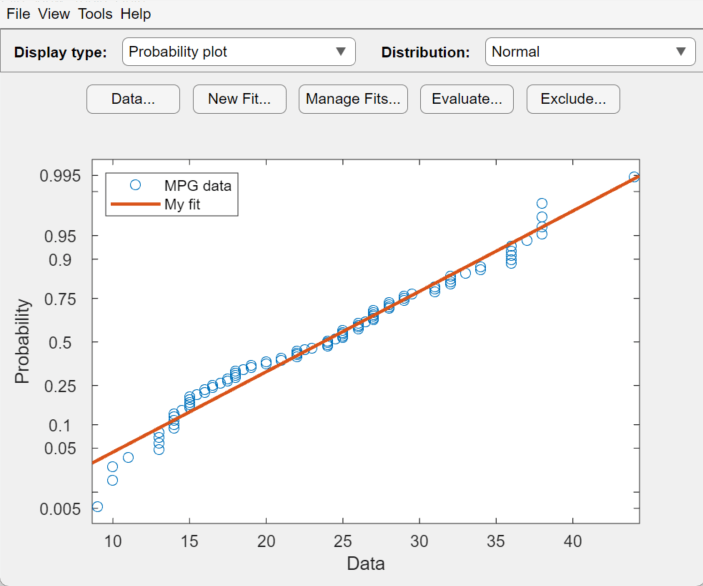
この正規確率プロットは、特に裾の部分でデータが正規分布から逸脱していることを示しています。
手順 4: 追加の近似の作成と管理
MPG データの pdf は、データに 2 つのピークがあることを示しています。このデータにさらに適合する近似を得るため、ノンパラメトリックなカーネル分布で近似します。
[近似の管理] をクリックします。ダイアログ ボックスで [新規近似] をクリックします。
[近似名] フィールドに近似の名前 (「
Kernel fit」など) を入力します。[データ] フィールドのドロップダウン リストから [
MPG data] を選択します。[分布] フィールドのドロップダウン リストから [ノンパラメトリック] を選択します。この操作により、[ノンパラメトリック] ペインで [カーネル]、[帯域幅]、[領域] などのオプションが使用できるようになります。ここでは既定値をそのまま使用して、正規分布の形状のカーネルを適用し、カーネルの帯域幅を自動的に決定します ([自動] を使用)。ノンパラメトリックなカーネル分布についての詳細は、カーネル分布を参照してください。
[適用] をクリックします。
MPG data を近似するノンパラメトリックな分布のカーネルのタイプ、帯域幅および領域が [結果] ペインに表示されます。

元の MPG data に正規分布とノンパラメトリックなカーネル分布を重ねたプロットがメイン ウィンドウに表示されます。この 2 つの近似を視覚的に比較するため、[表示タイプ] ドロップダウン リストから [密度 (PDF)] を選択します。
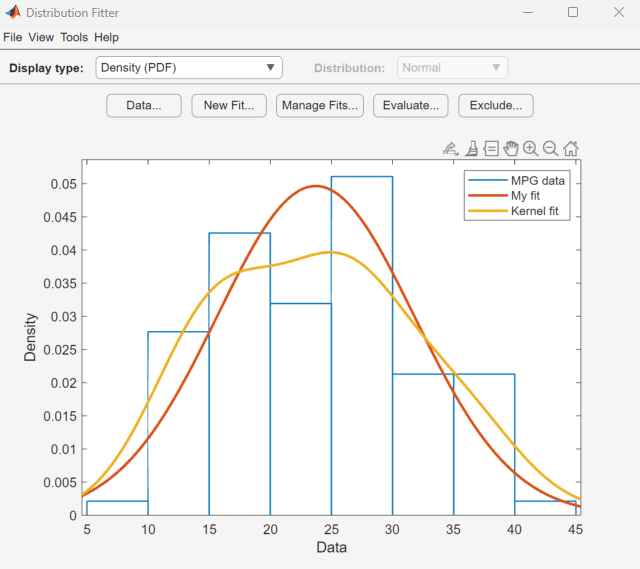
ノンパラメトリックなカーネル近似線 (Kernel fit) のみをプロットに含めるため、[近似の管理] をクリックします。[近似テーブル] ペインで、正規分布近似 (My fit) を探して [プロット] 列のボックスをクリアします。
