生存時間分析とは
はじめに
生存時間分析とは、イベントまでの時間解析のことです。つまり、関連の結果は、イベントが発生するまでの時間になります。事象までの時間の一般的な例としては次のものがあります。
健康科学の分野における感染、疾病の再発、回復までの時間
経済の分野における失業期間や景気後退期間
エンジニアリングの分野における機械部品が故障するまでの時間や電球の寿命
生存時間分析は、エンジニアリングにおける信頼性研究の一部です。この場合、通常は工業部品の寿命を研究するために使用されます。通常、信頼性解析では、生存時間は故障時間と呼ばれます。関連の変数は、部品が故障するまで正しく動作する時間の長さです。
生存時間分析は、パラメトリック手法、セミパラメトリック手法およびノンパラメトリック手法で構成されています。これらの手法を使用して、生存研究、生存関数およびハザード関数で最も一般的に使用される尺度を推定して、その尺度をさまざまなグループで比較し、生存時間に対する予測子変数の関係を評価します。いくつかの統計確率分布でも生存時間が表されます。通常使用される分布は、指数分布、ワイブル分布、対数正規分布、ブール分布、およびバーンバウム・サンダース分布です。Statistics and Machine Learning Toolbox™ 関数である ecdf と ksdensity は、累積分布関数、累積ハザード関数、および生存関数の経験的密度推定とカーネル密度推定を計算します。coxphfit はコックス比例ハザード モデルをデータに当てはめます。fitcox はコックス比例ハザード モデル用の新しい近似関数です。
打ち切り
打ち切りは、生存時間分析における 1 つの重要な概念です。一部の個体の生存時間は、さまざまな理由により十分観測できない可能性があります。ライフ サイエンスにおいてこの問題が生じるのは、すべての個人の完全な生存時間が観測される前に生存研究 (臨床試験など) が中止されたり、個人が研究への参加を止めた場合や、長期間の研究中に経過を観察すべき患者がいなくなった場合です。産業界において、信頼性研究が終了するまでにすべての要素で故障が発生するとは限りません。このような場合、個人は研究期間の経過後も生存するため、正確な生存時間が不明になります。これは、右側打ち切りと呼ばれます。
生存研究中、個体は T 時に故障が観測されるか、その個体に関する観測が c 時に中断します。この場合、観測値は min(T,c) で、指標変数 Ic で、個体が打ち切られるかどうかを示します。打ち切りを考慮してハザード関数および生存関数の計算を調整しなければなりません。ecdf、ksdensity、coxphfit、および mle などの Statistics and Machine Learning Toolbox 関数では打ち切りが考慮されます。
データ
通常、生存データは関連のイベントが発生するまでの時間と、個人または部品ごとの打ち切り情報で構成されます。以下の表に、6 か月の研究期間における架空の個人の失業期間を示します。2 人が右側打ち切りされています (1 の打ち切り値で示されます)。研究が終了した 24 週目以降も 1 人が失業中です。打ち切られたもう 1 人との連絡は 21 週目の終わりに途絶えています。
| 失業期間 (週) | 打ち切り |
|---|---|
| 14 | 0 |
| 23 | 0 |
| 7 | 0 |
| 21 | 1 |
| 19 | 0 |
| 16 | 0 |
| 24 | 1 |
| 8 | 0 |
生存データには、一定の時間の故障の回数 (特定の生存または故障時間が観測された回数) も含まれる場合があります。以下の表は、高速寿命テストで発光ダイオードが完全な光出力レベルの 70% に低下するまでのシミュレーション時間 (時間単位) を示したものです。
| 故障時間 (時間単位) | 頻度 |
|---|---|
| 8600 | 6 |
| 15300 | 19 |
| 22000 | 11 |
| 28600 | 20 |
| 35300 | 17 |
| 42000 | 14 |
| 48700 | 8 |
| 55400 | 2 |
| 62100 | 0 |
| 68800 | 2 |
データには、コックス比例ハザード回帰などのセミパラメトリック回帰のような手法で使用するために、予測子変数に関する情報も含まれる場合があります。
| 回復までの時間 (週単位) | 打ち切り | 性別 | 収縮期血圧 | 拡張期血圧 |
|---|---|---|---|---|
| 12 | 1 | 男性 | 124 | 93 |
| 20 | 0 | 女性 | 109 | 77 |
| 7 | 0 | 女性 | 125 | 83 |
| 13 | 0 | 男性 | 117 | 75 |
| 9 | 1 | 男性 | 122 | 80 |
| 15 | 0 | 女性 | 121 | 70 |
| 17 | 1 | 男性 | 130 | 88 |
| 8 | 0 | 女性 | 115 | 82 |
| 14 | 0 | 男性 | 118 | 86 |
生存関数
生存関数とは、時間の関数としての生存の確率です。これは生存時間関数とも呼ばれます。この関数は、個体の生存時間が特定の値を超える確率を示します。累積分布関数 F(t) は、生存時間が特定の時点以下である確率で、連続分布の生存時間関数 S(t) は、累積分布関数の補数です。
S(t) = 1 – F(t).
生存関数は、ハザード関数とも関連します。データにハザード関数 h(t) がある場合、生存関数は次のようになります。
これは次に相当します。
ここで、H(t) は累積ハザード関数です。
ブール分布の生存関数
パラメーターが 50、3、および 1 のブール分布の生存関数を計算してプロットします。
x = 0:0.1:200; figure() plot(x,1-cdf('Burr',x,50,3,1)) xlabel('Failure time'); ylabel('Survival probability');

データをもとにした生存関数
この例では、データから生存関数を推定する方法を説明します。
標本データを読み込みます。
load readmissiontimes列ベクトル ReadmissionTime は、100 人の患者の再入院時間を示します。列ベクトル Censored には各患者の打ち切り情報が含まれ、1 は打ち切られたデータを示し、0 は正確な再入院時間が観測されることを示します。このデータは、シミュレーションされたものです。
[ReadmissionTime Censored]
ans = 100×2
5 1
3 1
19 0
17 0
9 0
16 0
4 0
2 0
3 0
15 0
7 0
9 0
1 0
2 0
5 0
⋮
最初の 2 つの再入院時間、5 および 3 はどちらも打ち切られています。
名前と値のペアの引数 'function','survivor' および 'censoring',Censored と共に ecdf を使用して、打ち切りを伴う経験生存関数を表示します。
ecdf(ReadmissionTime,'censoring',Censored,'function','survivor')

ハザード関数
ハザード関数は、個体が一定時間まで生存した事実に基づいて条件付けられた個体の瞬間故障率を示します。つまり、次のようになります。
ここで、Δt は非常に短い時間間隔です。したがって、ハザード率は条件付き故障率とも呼ばれることがあります。ハザード関数は常に正の値を取ります。ただし、これらの値は確率を表すものではないため、1 を超える可能性もあります。
ハザード関数は、次のように確率密度関数 f(t)、累積分布関数 F(t) および生存関数 S(t) と関連します。
これは次と同等です。
したがって、生存時間関数の形状が既知である場合は、対応するハザード関数も導出できます。
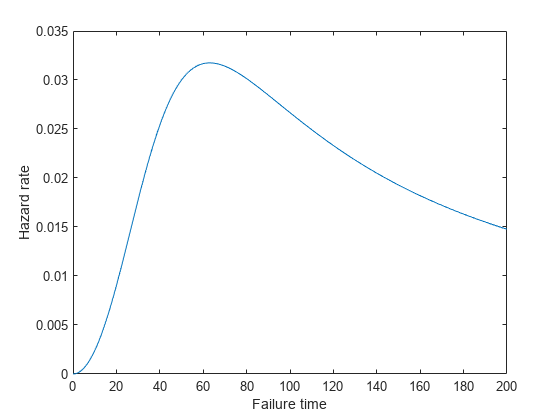
ブール分布のハザード関数
パラメーターが 50、3、および 1 のブール分布のハザード関数を計算してプロットします。
x = 0:1:200; Burrhazard = pdf('Burr',x,50,3,1)./(1-cdf('Burr',x,50,3,1)); figure() plot(x,Burrhazard) xlabel('Failure time'); ylabel('Hazard rate');
ワイブル ハザード関数
ハザード関数にはさまざまなタイプがあります。前の図は、ハザード率が初期の期間に上昇した後、徐々に下降していく状況を示しています。ハザード率は、単調減少、単調増加または常に一定である場合もあります。以下の図は、さまざまなワイブル分布から抽出されたデータに対する各種ハザード関数の例を示しています。
figure ax1 = subplot(3,1,1); x1 = 0:0.05:10; hazard1 = pdf('wbl',x1,3,0.6)./(1-cdf('wbl',x1,3,0.6)); plot(x1,hazard1,'color','b') set(ax1,'Ylim',[0 0.6]); legend(ax1,'a=3, b=0.6'); ax2 = subplot(3,1,2); x2 = 0:0.05:10; hazard2 = pdf('wbl',x2,9,4)./(1-cdf('wbl',x2,9,4)); plot(x2,hazard2,'color','r') set(ax2,'Ylim',[0 0.6]); legend(ax2,'a=9, b=4','location','southeast'); ax3 = subplot(3,1,3); x3 = 0:0.05:10; hazard3 = pdf('wbl',x3,2.5,1)./(1-cdf('wbl',x3,2.5,1)); plot(x3,hazard3,'color','g') set(ax3,'Ylim',[0 0.6]); legend(ax3,'a=2.5, b=1');

3 つ目の例で、ワイブル分布には、指数分布に対応した形状パラメーター値 1 があります。指数分布のハザード率は常に一定です。
参照
[1] Cox, D. R., and D. Oakes. Analysis of Survival Data. London: Chapman & Hall, 1984.
[2] Lawless, J. F. Statistical Models and Methods for Lifetime Data. Hoboken, NJ: Wiley-Interscience, 2002.
[3] Kleinbaum, D. G., and M. Klein. Survival Analysis. Statistics for Biology and Health. 2nd edition. Springer, 2005.
参考
ecdf | fitcox | coxphfit | ksdensity