ecdf
経験累積分布関数
説明
[ では、1 つ以上の名前と値の引数を使用して追加オプションを指定します。たとえば、f,x] = ecdf(y,Name,Value)'Function','survivor'f の関数のタイプを生存関数として指定します。
例
シミュレーションを実行した生存データの経験累積分布関数 (cdf) のカプラン・マイヤー推定値を計算します。
パラメーター 3 と 1 を使用してワイブル分布から生存データを生成します。
rng("default") % For reproducibility failuretime = random("wbl",3,1,15,1);
生存データの経験 cdf のカプラン・マイヤー推定値を計算します。
[f,x] = ecdf(failuretime); [f,x]
ans = 16×2
0 0.0895
0.0667 0.0895
0.1333 0.1072
0.2000 0.1303
0.2667 0.1313
0.3333 0.2718
0.4000 0.2968
0.4667 0.6147
0.5333 0.6684
0.6000 1.3749
0.6667 1.8106
0.7333 2.1685
0.8000 3.8350
0.8667 5.5428
0.9333 6.1910
⋮
推定された経験 cdf をプロットします。
ecdf(failuretime)
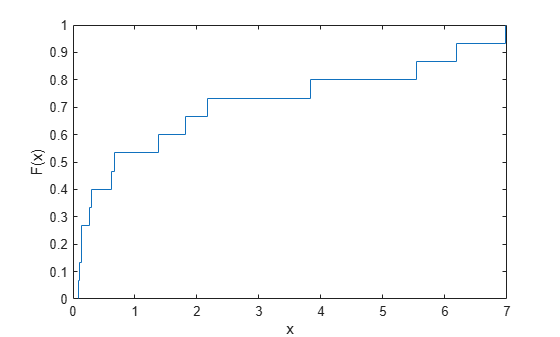
この図は、x の値が小さいうちは cdf が大きく上昇し、x が 7 に近づいたところで 1 に達することを示しています。
右側打ち切りの生存データを生成し、経験累積分布関数 (CDF) と既知の累積分布関数を比較します。
平均故障時間 15 をもつ指数分布から故障時間を生成します。
rng('default') % For reproducibility y = exprnd(15,75,1);
平均故障時間 30 をもつ指数分布から脱落時間を生成します。
d = exprnd(30,75,1);
観測故障時間を生成します。つまり、生成された故障時間と脱落時間の最小値です。
t = min(y,d);
脱落時間よりも大きい生成された故障時間を含む logical 配列を作成します。この条件が真となるデータが打ち切られます。
censored = (y>d);
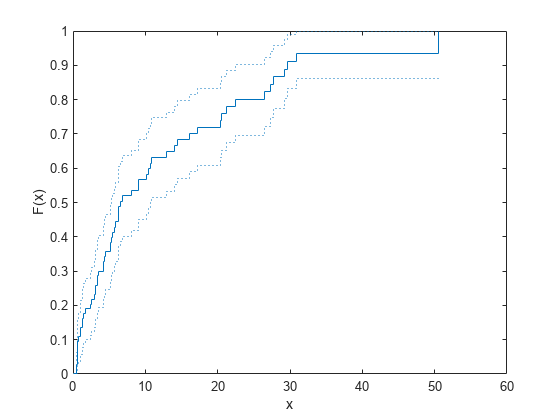
経験累積分布関数と信頼限界を計算します。
[f,x,flo,fup] = ecdf(t,'Censoring',censored);経験累積分布関数と信頼限界をプロットします。
ecdf(t,'Censoring',censored,'Bounds','on') hold on
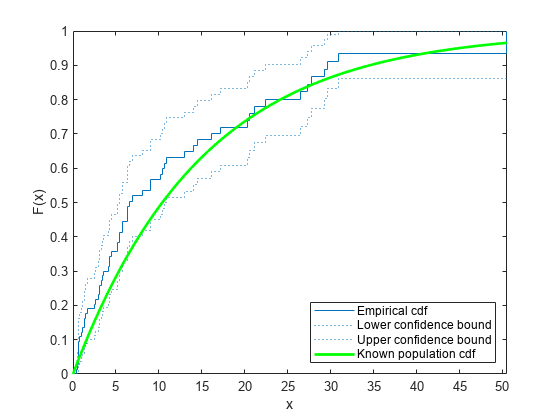
既知の母集団の累積分布関数のプロットを重ね合わせます。
xx = 0:.1:max(t); yy = 1-exp(-xx/15); plot(xx,yy,'g-','LineWidth',2) axis([0 max(t) 0 1]) legend('Empirical cdf','Lower confidence bound', ... 'Upper confidence bound','Known population cdf', ... 'Location','southeast') hold off
生存データを生成し、99% の信頼限界をもつ経験生存関数をプロットします。
パラメーター 100 と 2 を使用してワイブル分布から寿命データを生成します。
rng('default') % For reproducibility R = wblrnd(100,2,100,1);
99% の信頼限界をもつデータの経験生存関数をプロットします。
ecdf(R,'Function','survivor','Alpha',0.01,'Bounds','on') hold on
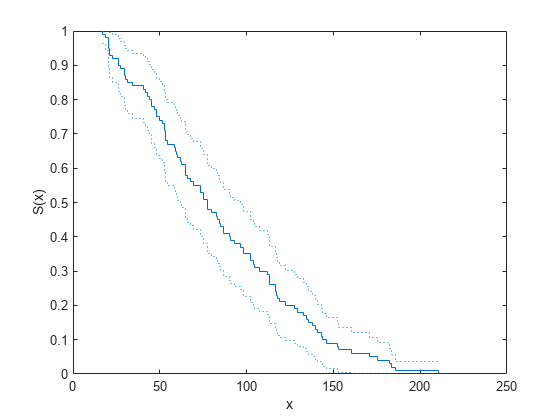
ワイブル生存関数のプロットを重ね合わせます。
x = 1:1:250; wblsurv = 1-cdf('weibull',x,100,2); plot(x,wblsurv,'g-','LineWidth',2) legend('Empirical survivor function','Lower confidence bound', ... 'Upper confidence bound','Weibull survivor function', ... 'Location','northeast')
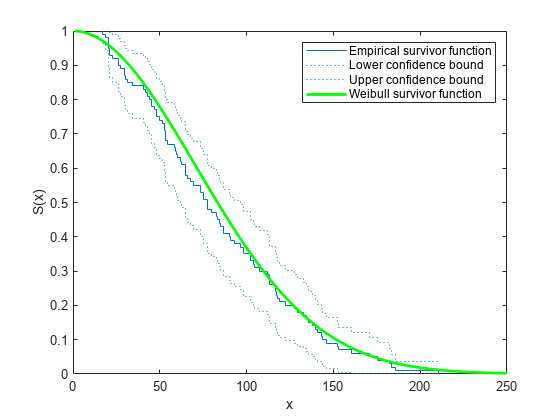
実際の分布に基づくワイブル生存関数は、信頼限界内に入っています。
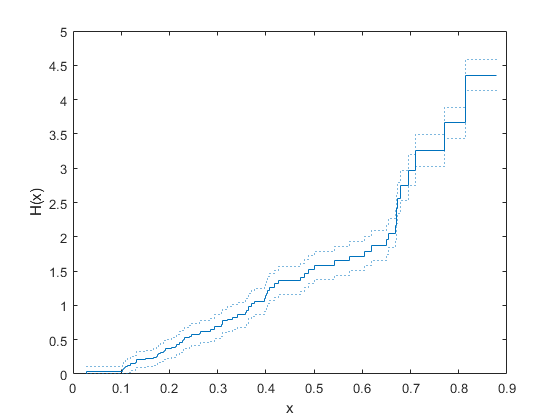
シミュレーション済みの二重打ち切り生存データの累積ハザード関数を計算およびプロットします。
バーンバウム・サンダース分布から故障時間を生成します。
rng('default') % For reproducibility failuretime = random('BirnbaumSaunders',0.3,1,[100,1]);
分析は時間 0.1 から開始し、時間 0.9 で終了すると仮定します。この仮定は、0.1 より小さい故障時間は左側打ち切りされ、0.9 より大きい故障時間は右側打ち切りされることを意味します。
各要素が failuretime の対応する観測の打ち切りステータスを示すベクトルを作成します。–1、1、および 0 を使用して、それぞれ左側打ち切り観測値、右側打ち切り観測値、完全に観測された観測値を示します。
L = 0.1; U = 0.9; left_censored = (failuretime<L); right_censored = (failuretime>U); c = right_censored - left_censored;
95% の信頼限界をもつデータの経験的累積ハザード関数をプロットします。
ecdf(failuretime,'Function','cumulative hazard', ... 'Censoring',c,'Bounds','on')
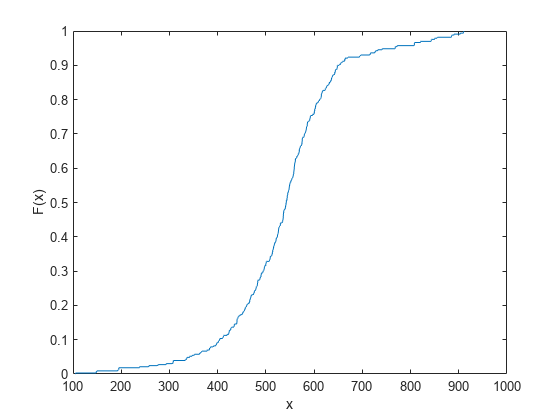
区間打ち切りデータの経験累積分布関数を計算してプロットします。
cities データ セットを読み込みます。このデータには、アメリカ合衆国の 329 の都市について、生活の質を表す 9 つの異なる指標 (気候、住宅、健康、犯罪、交通、教育、芸術、レクリエーション、経済) の評価点が含まれています。どの指標でも、評価点が高いほど優れています。
load cities最初の指標 (気候) を標本データに選択します。
Y = ratings(:,1);
Y の指標は、最も近い整数に丸められた値であると仮定します。すると、Y の値を区間打ち切り観測値として扱えます。Y の観測値 y は、実際の評価点が y–0.5 と y+0.5 の間にあることを示しています。
各行が Y にあるそれぞれの整数を囲む区間を表している行列を作成します。
intervalY = [Y-0.5, Y+0.5];
経験累積分布関数値を計算します。
[f,x] = ecdf(intervalY);
経験累積分布関数値をプロットします。
figure ecdf(intervalY)
より小さな領域にズーム インして、区間推定を確認します。
idx_roi = 21:30; xlim([x(idx_roi(1),1) x(idx_roi(end),2)])
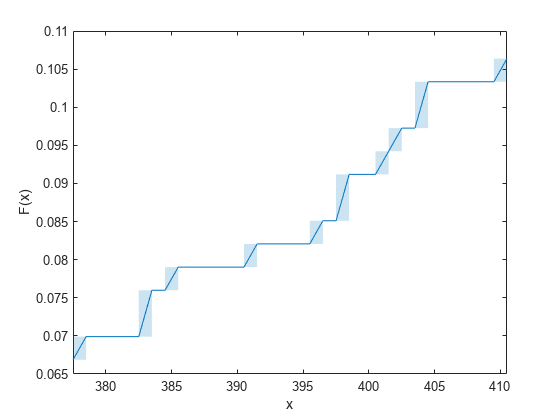
対応する x と f の値を表示します。
table(idx_roi',x(idx_roi,:),f(idx_roi,:), ... 'VariableNames',{'Index','x','Empirical cdf F(x)'})
ans=10×3 table
Index x Empirical cdf F(x)
_____ ______________ __________________
21 377.5 378.5 0.069909
22 382.5 383.5 0.075988
23 384.5 385.5 0.079027
24 390.5 391.5 0.082067
25 395.5 396.5 0.085106
26 397.5 398.5 0.091185
27 400.5 401.5 0.094225
28 401.5 402.5 0.097264
29 403.5 404.5 0.10334
30 409.5 410.5 0.10638
影付きの矩形は、対応する区間内で経験累積分布関数値 F(x) が変化していることを示します。たとえば、ズームしたプロットで左から 2 番目の影付きの矩形は、区間 (382.5,383.5] に対応します。F(382.5) は 0.075988、F(383.5) は 0.079027 で、0.075988 から 0.079027 への変化が区間 (382.5,383.5] で発生しています。変化の厳密なタイミングは不確定です。
区間推定はさまざまな方法でプロットできます。確率の変化が各区間の最初で生じていると仮定した場合、x の最初の列を使用して F(x) の値をプロットできます。
figure stairs(x(:,1),f) title('Probability changes at the start') xlabel('x') ylabel('F(x)') xlim([x(idx_roi(1),1) x(idx_roi(end),2)])
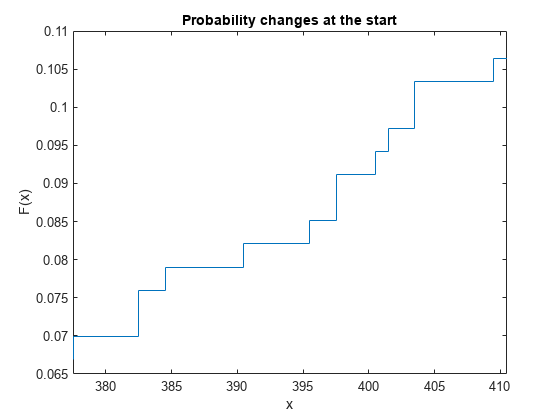
もしくは、確率の変化が各区間の最後に生じていると仮定した場合、x の 2 番目の列を使用して F(x) の値をプロットできます。
figure stairs(x(:,2),f) title('Probability changes at the end') xlabel('x') ylabel('F(x)') xlim([x(idx_roi(1),1) x(idx_roi(end),2)])
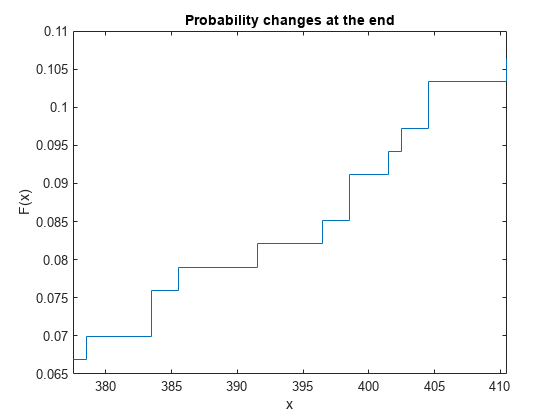
前の 2 つのプロットを組み合わせて、区間を可視化します。
figure stairs(x(:,1),f) hold on stairs(x(:,2),f) title('Probability changes in the interval') xlabel('x') ylabel('F(x)') xlim([x(idx_roi(1),1) x(idx_roi(end),2)]) hold off

データの経験累積分布関数 (cdf) を計算し、この経験累積分布関数の近似を使用して区分的線形分布オブジェクトを作成します。
標本データを読み込みます。ヒストグラムを使用して患者の体重データを可視化します。
load patients histogram(Weight(strcmp(Gender,'Female'))) hold on histogram(Weight(strcmp(Gender,'Male'))) legend('Female','Male')

ヒストグラムは、データに女性の患者と男性の患者に 1 つずつ 2 つの最頻値があることを示しています。
データの経験累積分布関数を計算します。
[f,x] = ecdf(Weight);
5 点ごとに値を 1 つ採用し、経験累積分布関数への区分的線形近似を構成します。
f = f(1:5:end); x = x(1:5:end);
経験累積分布関数と近似をプロットします。
figure ecdf(Weight) hold on plot(x,f,'ko-','MarkerFace','r') legend('Empirical cdf','Piecewise linear approximation', ... 'Location','best')
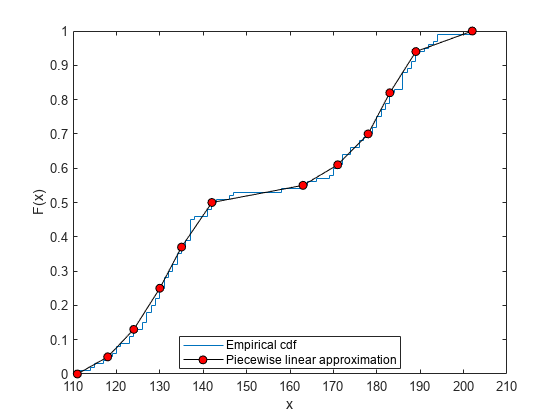
経験累積分布関数の区分的近似を使用して、区分的線形確率分布オブジェクトを作成します。
pd = makedist('PiecewiseLinear','x',x,'Fx',f)
pd = PiecewiseLinearDistribution F(111) = 0 F(118) = 0.05 F(124) = 0.13 F(130) = 0.25 F(135) = 0.37 F(142) = 0.5 F(163) = 0.55 F(171) = 0.61 F(178) = 0.7 F(183) = 0.82 F(189) = 0.94 F(202) = 1
分布から 100 個の乱数を生成します。
rng('default') % For reproducibility rw = random(pd,[100,1]);
乱数をプロットして、分布を元のデータと視覚的に比較します。
figure histogram(Weight) hold on histogram(rw) legend('Original data','Generated data')
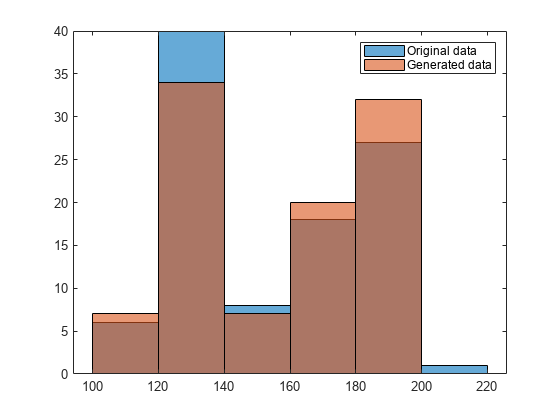
区分的線形分布から生成された乱数は、元のデータと同じ二峰性分布をもちます。
入力引数
名前と値の引数
出力引数
詳細
アルゴリズム
ecdf は、打ち切り情報に応じて異なるアルゴリズムを使用し、関数値 (f) および信頼限界 (flo および fup) を計算します。f の関数タイプは、名前と値の引数 Function で指定されるように、cdf (既定)、生存関数、または累積ハザード関数にできます。
| 打ち切りのタイプ | f のアルゴリズム | flo および fup のアルゴリズム |
|---|---|---|
| 右側打ち切りデータ。完全に観測された観測値または右側打ち切り観測値を含む |
| グリーンウッドの公式を使用します。この式はカプラン・マイヤー推定器の分散の近似です。 分散推定は次の式で与えられます。 |
| 左側打ち切りデータ。完全に観測された観測値または左側打ち切り観測値を含む | カプラン・マイヤー推定器を使用します。 | グリーンウッドの公式を使用します。 |
| 二重打ち切りデータ。右側打ち切り観測値および左側打ち切り観測値の両方を含む | ターンブルのアルゴリズム [3][4] を使用します。アルゴリズムに対して最大反復回数 ( | フィッシャー情報行列を使用します。 |
| 区間打ち切りデータ。区間打ち切り観測値を含む |
| サポートなし |
代替機能
fitdist 関数を使用して分布をデータに当てはめることにより、EmpiricalDistribution オブジェクトを作成できます。当てはめた後に、cdf オブジェクト関数を使用して cdf を評価できます。EmpiricalDistribution のその他のオブジェクト関数を使用して、逆 cdf を計算したり、確率密度関数 (pdf) を評価したり、分布から乱数を生成したりできます。
参照
[1] Cox, D. R., and D. Oakes. Analysis of Survival Data. London: Chapman & Hall, 1984.
[2] Lawless, J. F. Statistical Models and Methods for Lifetime Data. 2nd ed., Hoboken, NJ: John Wiley & Sons, Inc., 2003.
[3] Klein, John P., and Melvin L. Moeschberger. Survival Analysis: Techniques for Censored and Truncated Data. 2nd ed. Statistics for Biology and Health. New York: Springer, 2003.
[4] Turnbull, Bruce W. "Nonparametric Estimation of a Survivorship Function with Doubly Censored Data." Journal of the American Statistical Association 69, No. 345 (1974): 169–73.
[5] Anderson-Bergman, Clifford. "An Efficient Implementation of the EMICM Algorithm for the Interval Censored NPMLE." Journal of Computational and Graphical Statistics 26, no. 2 (April 3, 2017): 463–67.
[6] Ware, James H., and David L. Demets. "Reanalysis of Some Baboon Descent Data." Biometrics 32, no. 2 (June 1976): 459–63.
拡張機能
バージョン履歴
R2006a より前に導入