cdfplot
経験累積分布関数 (cdf) プロット
説明
h = cdfplot(___)h を使用します。プロパティの一覧については、Line のプロパティを参照してください。
例
標本データ セットの経験 cdf をプロットし、標本データ セットの基となる分布の理論的な cdf と比較します。実際には、理論的な cdf は不明な場合があります。
位置パラメーターが 0、スケール パラメーターが 3 の極値分布から、ランダムな標本データ セットを生成します。
rng('default') % For reproducibility y = evrnd(0,3,100,1);
標本データ セットの経験 cdf と理論的な cdf を同じ図にプロットします。
cdfplot(y) hold on x = linspace(min(y),max(y)); plot(x,evcdf(x,0,3)) legend('Empirical CDF','Theoretical CDF','Location','best') hold off
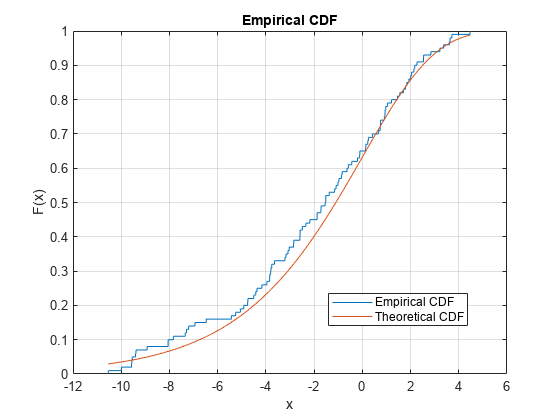
このプロットは、経験 cdf と理論的な cdf の間の類似性を示します。
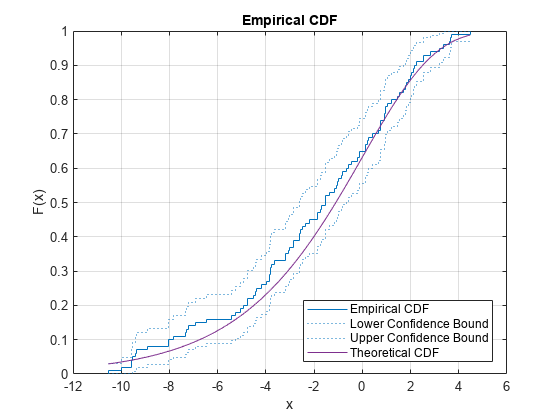
代わりに、関数 ecdf を使用することもできます。関数 ecdf は、グリーンウッドの公式を使用して推定した 95% 信頼区間もプロットします。詳細については、アルゴリズムを参照してください。
ecdf(y,'Bounds','on') hold on plot(x,evcdf(x,0,3)) grid on title('Empirical CDF') legend('Empirical CDF','Lower Confidence Bound','Upper Confidence Bound','Theoretical CDF','Location','best') hold off
kstest を使用して、1 標本コルモゴロフ・スミルノフ検定を実行します。経験累積分布関数 (cdf) を標準正規 cdf と視覚的に比較することにより、検定の判定を確認します。
examgrades データ セットを読み込みます。試験採点データの 1 列目が含まれているベクトルを作成します。
load examgrades
test1 = grades(:,1);平均が 75、標準偏差が 10 の正規分布にデータが由来しているという帰無仮説を検定します。kstest の既定の設定では標準正規分布について検定を行うので、これらのパラメーターを使用してデータ ベクトルの各要素をセンタリングおよびスケーリングします。
x = (test1-75)/10; h = kstest(x)
h = logical
0
h = 0 の戻り値は、kstest が既定の有意水準 5% で帰無仮説を棄却できないことを示します。
経験累積分布関数と標準正規累積分布関数をプロットして、視覚的に比較します。
cdfplot(x) hold on x_values = linspace(min(x),max(x)); plot(x_values,normcdf(x_values,0,1),'r-') legend('Empirical CDF','Standard Normal CDF','Location','best')
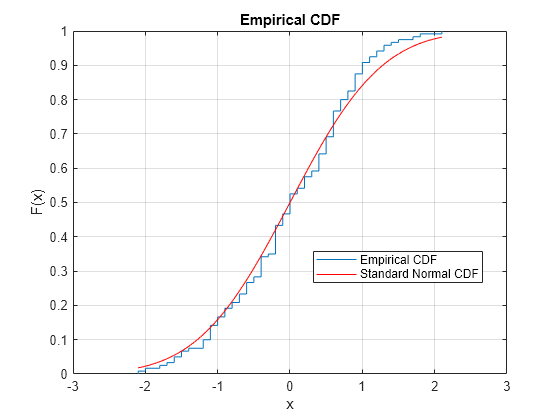
Figure には、センタリングおよびスケーリングされたデータ ベクトルの経験累積分布関数と標準正規分布の累積分布関数の間の類似性が示されています。
入力引数
出力引数
ヒント
cdfplotは、標本データ セットの分布を確認するために役立ちます。理論的な cdf を同じcdfplotのプロットに重ね合わせて、標本の経験分布を理論的分布と比較できます。たとえば、経験 cdf と理論的な cdf の比較を参照してください。関数
kstest、kstest2およびlillietestは、経験 cdf から導かれる検定統計量を計算します。cdfplotは、これらの関数からの出力を理解するために役立ちます。たとえば、標準正規分布の検定を参照してください。
代替機能
関数 ecdf を使用すると、経験 cdf の値を求めて経験 cdf のプロットを作成することができます。関数 ecdf では、打ち切られたデータが示され、推定された cdf 値の信頼限界が計算されます。