lillietest
リリーフォース検定
構文
説明
h = lillietest(x,Name,Value)
例
標本データを読み込みます。ガロンあたりの走行マイル数 (MPG) で表した自動車の燃費が、さまざまな車種間で正規分布に従うという帰無仮説を検定します。
load carbig
[h,p,k,c] = lillietest(MPG)Warning: P is less than the smallest tabulated value, returning 0.001.
h = 1
p = 1.0000e-03
k = 0.0789
c = 0.0451
検定統計量 k が棄却限界値 c を超えているため、lillietest は、既定の有意水準 5% で帰無仮説を棄却することを示す h = 1 の結果を返します。警告は、事前に計算された値の table に格納されている最小値より小さい 値が返されたことを示しています。より正確な 値を求めるには、MCTol を使用してモンテカルロ近似を実行します。モンテカルロ近似の使用による p 値の決定を参照してください。
標本データを読み込みます。学生の試験の採点データの 1 列目を含むベクトルを作成します。
load examgrades
x = grades(:,1);標本データは有意水準 1% で標本データが正規分布からのものであるという帰無仮説を検定します。
[h,p] = lillietest(x,'Alpha',0.01)h = 0
p = 0.0348
h = 0 の戻り値は、lillietest が有意水準 1% で帰無仮説を棄却しないことを示します。
標本データを読み込みます。ガロンあたりの走行マイル数 (MPG) で表した自動車の燃費が、さまざまな車種間で指数分布に従うという帰無仮説を検定します。
load carbig h = lillietest(MPG,'Distribution','exponential')
h = 1
h = 1 の戻り値は、lillietest が既定の有意水準 5% で帰無仮説を棄却することを示します。
2 つの標本データ セットを、一方はワイブル分布から、もう一方は対数正規分布から生成します。リリーフォース検定を実行して、各データ セットがワイブル分布からのものかどうかを評価します。ワイブル確率プロット (wblplot) を使用して視覚的に比較することにより、検定の判定を確認します。
ワイブル分布から標本を生成します。
rng('default')
data1 = wblrnd(0.5,2,[500,1]);lillietest を使用して、リリーフォース検定を実行します。ワイブル分布に対してデータを検定するため、データの対数が極値分布に従うかどうかを検定します。
h1 = lillietest(log(data1),'Distribution','extreme value')
h1 = 0
h1 = 0 の戻り値は、lillietest が既定の有意水準 5% で帰無仮説を棄却できないことを示します。ワイブル確率プロットを使用して、検定の判定を確認します。
wblplot(data1)
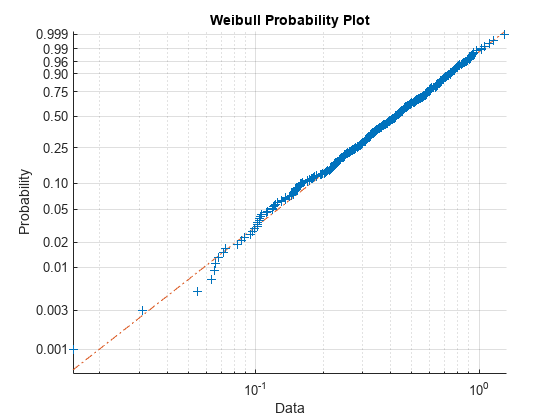
このプロットは、データがワイブル分布に従うことを示しています。
対数正規分布から標本を生成します。
data2 =lognrnd(5,2,[500,1]);
リリーフォース検定を実行します。
h2 = lillietest(log(data2),'Distribution','extreme value')
h2 = 1
h2 = 1 の戻り値は、lillietest が既定の有意水準 5% で帰無仮説を棄却することを示します。ワイブル確率プロットを使用して、検定の判定を確認します。
wblplot(data2)
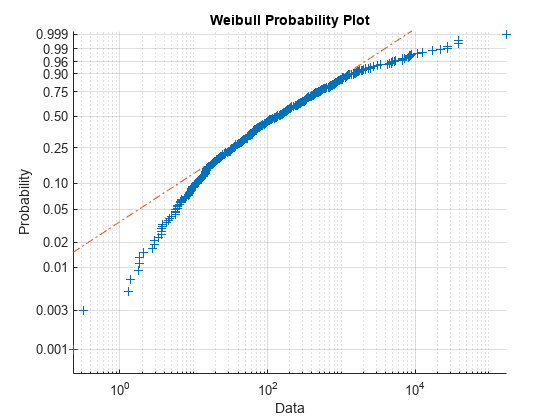
このプロットは、データがワイブル分布に従わないことを示しています。
標本データを読み込みます。ガロンあたりの走行マイル数 (MPG) で表した自動車の燃費が、さまざまな車種間で正規分布に従うという帰無仮説を検定します。最大モンテカルロ標準誤差が 1e-4 であるモンテカルロ近似を使用して、 値を決定します。
load carbig [h,p] = lillietest(MPG,'MCTol',1e-4)
h = 1
p = 8.3333e-06
h = 1 の戻り値は、lillietest が、有意水準 5% でデータは正規分布から派生するという帰無仮説を棄却することを示します。
入力引数
名前と値の引数
出力引数
詳細
アルゴリズム
仮説検定の棄却限界値を計算するために、lillietest は、標本サイズが 1,000 未満であり、0.001 から 0.50 までの有意水準をもつ標本に対してモンテカルロ シミュレーションを使用し、事前に計算された棄却限界値の表に内挿します。lillietest で使用される表は、リリーフォースによって導入された表よりも大きくて正確です。さらに正確な p 値が必要な場合や、必要な有意水準が 0.001 未満または 0.50 を超える場合、MCTol 入力引数を使用してモンテカルロ シミュレーションを実行し、p 値をさらに正確に計算することができます。
検定統計量の計算された値が棄却限界値よりも大きい場合、lillietest は有意水準 Alpha で帰無仮説を棄却します。
lillietest は、x の NaN 値を欠損値として扱い、無視します。
参照
[1] Conover, W. J. Practical Nonparametric Statistics. Hoboken, NJ: John Wiley & Sons, Inc., 1980.
[2] Lilliefors, H. W. “On the Kolmogorov-Smirnov test for the exponential distribution with mean unknown.” Journal of the American Statistical Association. Vol. 64, 1969, pp. 387–389.
[3] Lilliefors, H. W. “On the Kolmogorov-Smirnov test for normality with mean and variance unknown.” Journal of the American Statistical Association. Vol. 62, 1967, pp. 399–402.
バージョン履歴
R2006a より前に導入