random
構文
説明
例
平均 が 1、標準偏差 が 5 に等しい正規分布から 1 つの乱数を生成します。分布名 'Normal' と分布パラメーターを指定します。
rng('default') % For reproducibility mu = 1; sigma = 5; r = random('Normal',mu,sigma)
r = 3.6883
正規分布オブジェクトを作成し、そのオブジェクトを使用して 1 つの乱数を生成します。
平均 が 1、標準偏差 が 5 に等しい正規分布オブジェクトを作成します。
mu = 1; sigma = 5; pd = makedist('Normal','mu',mu,'sigma',sigma);
分布から 1 つの乱数を生成します。
rng('default') % For reproducibility r = random(pd)
r = 3.6883
乱数発生器の現在の状態を保存します。次に、レート パラメーター 5 をもつポアソン分布から乱数を生成します。
s = rng;
r = random('Poisson',5)r = 5
乱数発生器の状態を s に戻してから、新しい乱数を作成します。値は前と同じです。
rng(s);
r1 = random('Poisson',5)r1 = 5
既存の配列と同じサイズをもつ、乱数の行列を作成します。形状パラメーター 2 および 0、スケール パラメーター 1、位置パラメーター 0 をもつ安定分布を使用します。
A = [3 2; -2 1];
sz = size(A);
R = random('Stable',2,0,1,0,sz)R = 2×2
0.7604 -3.1945
2.5935 1.2193
上記の 2 行のコードを結合して 1 行にすることができます。
R = random('Stable',2,0,1,0,size(A))R = 2×2
0.4508 -0.6132
-1.8494 0.4845
既定のパラメーター値を使用してワイブル確率分布オブジェクトを作成します。
pd = makedist('Weibull')pd =
WeibullDistribution
Weibull distribution
A = 1
B = 1
この分布から乱数を生成します。
rng('default') % For reproducibility r = random(pd,10000,1);
100 個のビンを使用して、ワイブル分布を当てはめたヒストグラムを作成します。
histfit(r,100,'weibull')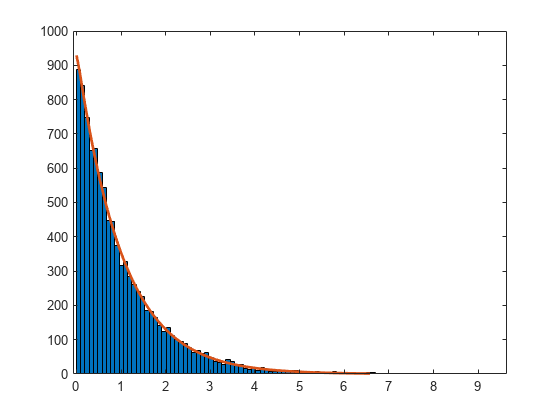
標準正規確率分布オブジェクトを作成します。
pd = makedist('Normal')pd =
NormalDistribution
Normal distribution
mu = 0
sigma = 1
分布から乱数の 2 x 3 x 2 の配列を生成します。
r = random(pd,[2,3,2])
r =
r(:,:,1) =
0.5377 -2.2588 0.3188
1.8339 0.8622 -1.3077
r(:,:,2) =
-0.4336 3.5784 -1.3499
0.3426 2.7694 3.0349
入力引数
出力引数
代替機能
randomは、名前nameによって指定された分布、または確率分布オブジェクトpdのいずれも受け入れる汎用関数です。正規分布の場合はrandnやnormrnd、二項分布の場合はbinorndなど、分布特有の関数を使用する方が高速です。分布特有の関数の一覧については、サポートされている分布を参照してください。乱数を対話的に生成するには、乱数発生用ユーザー インターフェイス
randtoolを使用します。