オブジェクトの検出
Computer Vision Toolbox™ は、深層学習と従来型のコンピューター ビジョン技術の両方を使用して、オブジェクト検出モデルの作成、学習、評価、および展開を行うための包括的なツールと関数を提供します。イメージ ラベラー アプリとビデオ ラベラー アプリを使用して、ラベル付きのグラウンド トゥルースを作成することから始められます。これらのアプリは、対話形式および AI アシストによる、イメージやビデオ フレーム内のオブジェクトを囲む境界ボックスの注釈付けをサポートしています。
ラベル付きデータを入手したら、YOLO v2、YOLO v3、YOLO v4、YOLOX、RTMDet、SSD、Grounding DINO など、幅広い事前学習済み深層学習オブジェクト検出器から選択できます。ツールボックスには、人物認識や顔認識タスクのための、peopleDetector や faceDetector といった専用の検出器も含まれています。これらのモデルは、推論に直接使用することも、転移学習の出発点として使用して特定のデータ セットや用途に合わせてモデルをカスタマイズすることもできます。詳細については、深層学習を使用したオブジェクト検出入門を参照してください。従来のオブジェクト検出手法のために、ツールボックスには集約チャネル特徴 (ACF) およびカスケード (Viola-Jones) オブジェクト検出器のサポートが含まれています。
ツールボックスは、転移学習を使用してオブジェクト検出器に学習させるための関数を提供します。さらに、ツールボックスは、学習データの管理と前処理機能に加え、現実世界の変動をシミュレーションすることでロバストなモデル学習を実現するデータ拡張ツールも提供します。詳細については、深層学習用イメージ前処理とイメージ拡張の入門を参照してください。
事前学習済みモデルまたはカスタム モデルを使用して検出結果を生成した後、オブジェクト検出器アナライザー アプリを使用して、検出結果をグラウンド トゥルースと比較できます。このアプリを使用すると、さまざまな intersection over union (IOU) しきい値にわたって、混同行列、適合率、再現率、F1 スコア、平均適合率 (mAP) などの主要なパフォーマンス メトリクスを評価できます。あるいは、evaluateObjectDetection 関数を使用して、検出パフォーマンス メトリクスを評価することもできます。詳細については、Evaluate Object Detector PerformanceとGet Started with Object Detector Analyzer Appを参照してください。
アプリ
| イメージ ラベラー | コンピューター ビジョンの応用に使用するラベル イメージ |
| ビデオ ラベラー | Label video for computer vision applications |
| オブジェクト検出器アナライザー | Interactively visualize and evaluate object detection results against ground truth (R2026a 以降) |
関数
ブロック
| Deep Learning Object Detector | 学習済み深層学習オブジェクト検出器を使用したオブジェクトの検出 (R2021b 以降) |
トピック
オブジェクト検出用のグラウンド トゥルースと学習データの作成
- イメージ ラベラー入門
四角形の ROI (オブジェクト検出用)、ピクセル (セマンティック セグメンテーション用)、多角形 (インスタンス セグメンテーション用)、およびシーン (イメージ分類用) に対話形式でラベルを付ける。 - ビデオ ラベラー入門
ビデオおよびイメージのシーケンス内の四角形の ROI (オブジェクト検出用)、ピクセル (セマンティック セグメンテーション用)、多角形 (インスタンス セグメンテーション用)、およびシーン (イメージ分類用) に対話形式でラベルを付ける。 - オブジェクト検出およびセマンティック セグメンテーション用の学習データ
イメージ ラベラーやビデオ ラベラーを使用して、オブジェクト検出器やセマンティック セグメンテーションの学習データを作成します。 - 深層学習用イメージ前処理とイメージ拡張の入門
サイズ変更などの確定的演算を使用して深層学習アプリケーション用にデータを前処理する。あるいは、ランダム トリミングなどのランダム演算を使用して学習データを拡張する。
事前学習済み検出器を使用したオブジェクトの検出
- 深層学習を使用したオブジェクト検出入門
YOLOX、YOLO v4、SSD などの深層学習ニューラル ネットワークを使用してオブジェクト検出を実行する。 - オブジェクト検出器の選択
YOLOX、YOLO v4、RTMDet、SSD などのオブジェクト検出深層学習モデルの比較。 - カスケード型オブジェクト検出器入門
カスタム分類器に学習させる。 - MATLAB による深層学習 (Deep Learning Toolbox)
畳み込みニューラル ネットワークを使用して分類や回帰を行う MATLAB® の深層学習機能を確認します。これには、事前学習済みのネットワークと転移学習のほか、GPU、CPU、クラスター、およびクラウドでの学習が含まれます。 - 事前学習済みの深層ニューラル ネットワーク (Deep Learning Toolbox)
分類、転移学習、特徴抽出用の事前学習済みの畳み込みニューラル ネットワークのダウンロード方法と使用方法を学習します。
オブジェクト検出結果の評価
- Evaluate Object Detector Performance
Evaluate object detector performance using metrics such as average precision, precision recall, and confusion matrix. - Get Started with Object Detector Analyzer App
Use Object Detector Analyzer app to evaluate pretrained object detectors or precomputed detection results against the ground truth data, and evaluate performance metrics. - Calibrate Object Detection Confidence Scores
This example shows how to calibrate the confidence scores of an object using Platt scaling.
注目の例

Automatically Search and Label Video Frames Using VLMs
Automatically search and detect objects based on natural language text queries using vision-language models (VLMs).
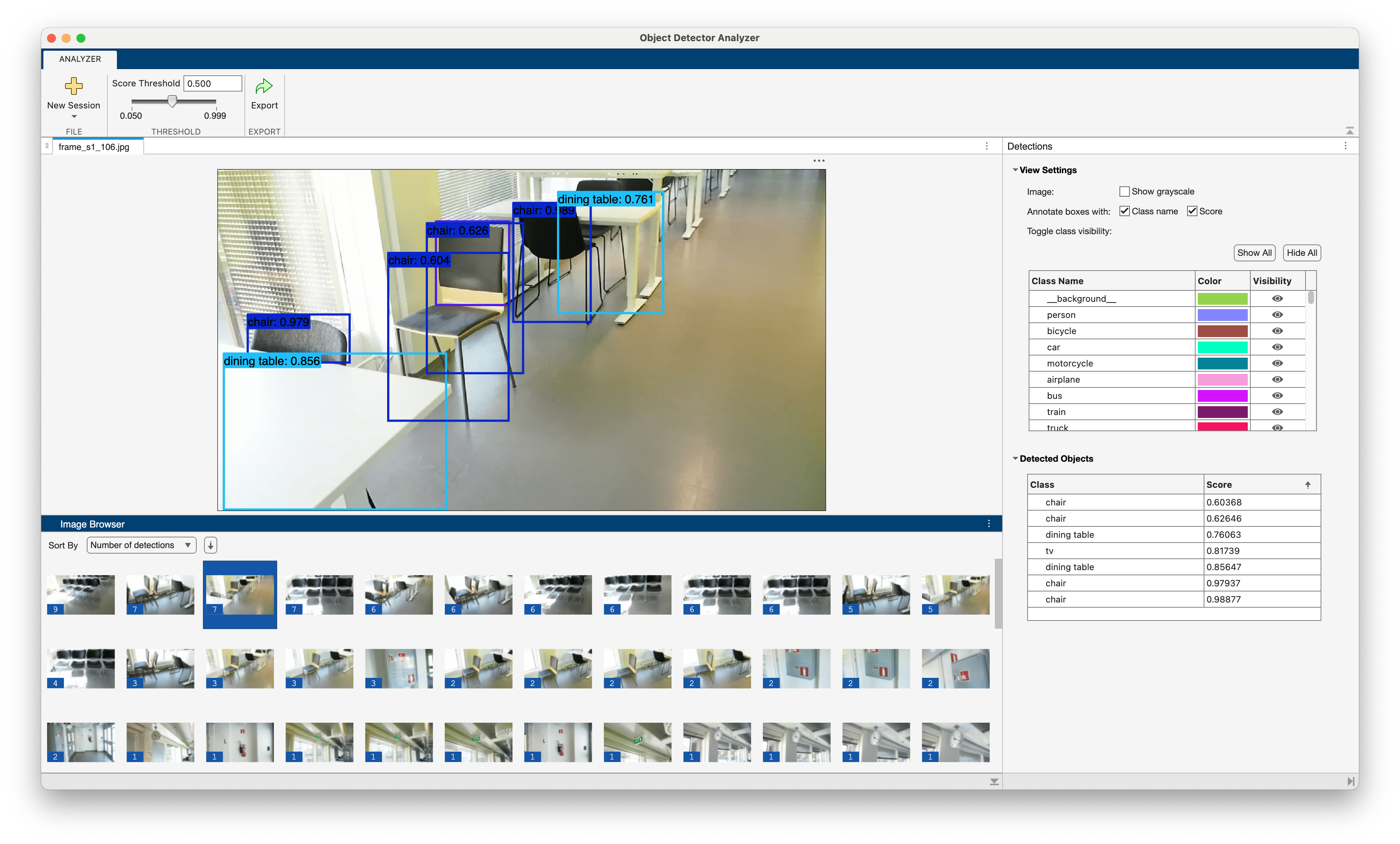
Visualize Object Detection Results from Pretrained PyTorch Model
Detect objects using a pretrained PyTorch® model and visualize the results in Object Detector Analyzer.
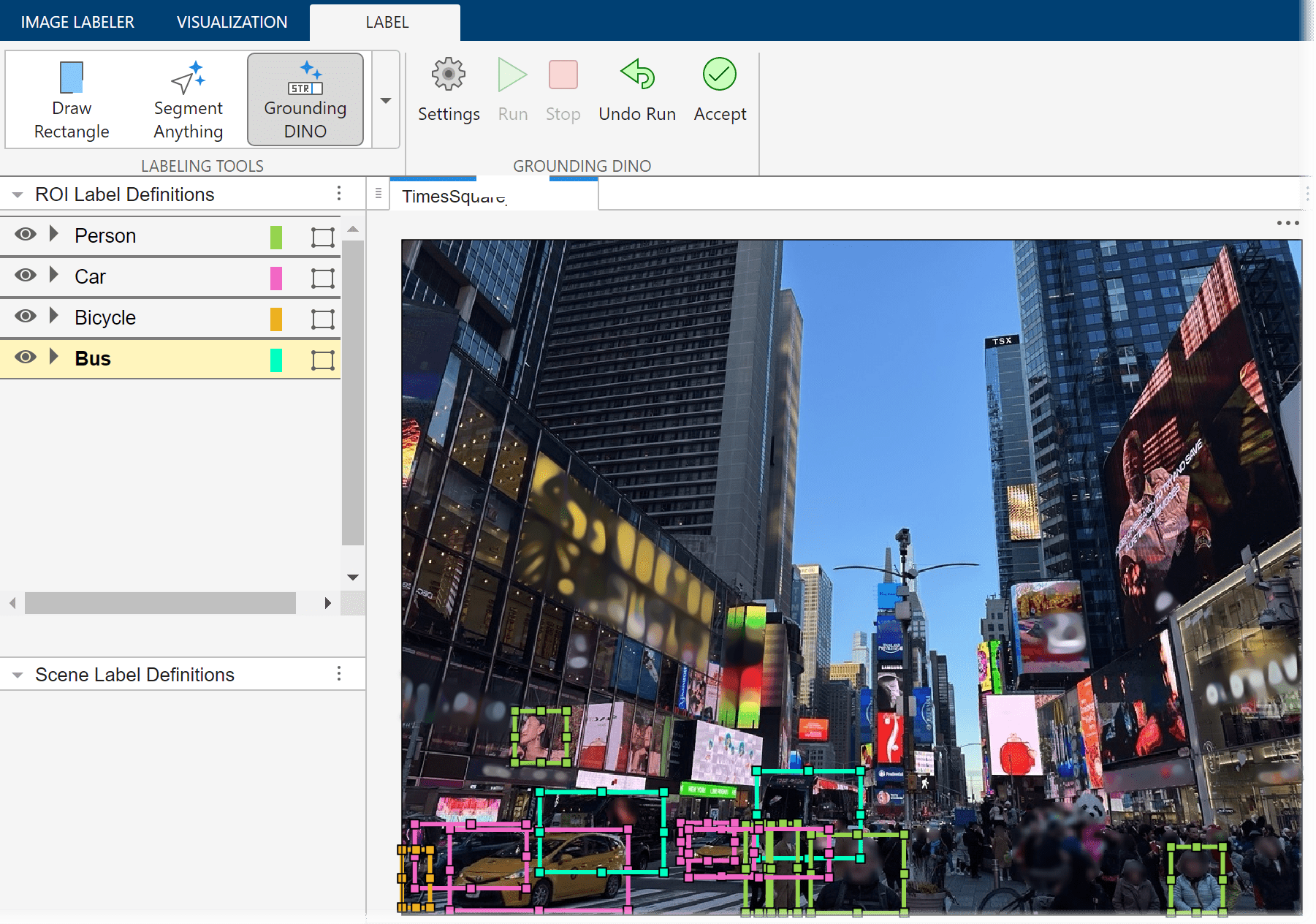
Automatically Label Ground Truth Using Vision-Language Model
Automatically label ground truth images for object detection using the Grounding DINO vision-language model (VLM).

Detect Small Objects Using Tiled Training of YOLOX Network
Detect small objects in full-resolution images using tiled training of a you only look once version X (YOLOX) deep learning network.
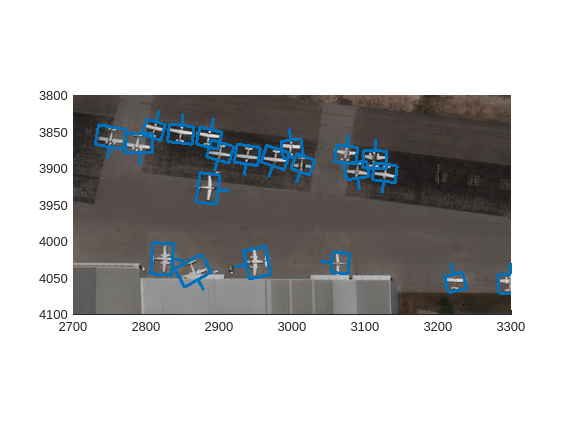
Object Detection in Large Satellite Imagery Using Deep Learning
Perform object detection on large satellite imagery using deep learning.

YOLO v4 深層学習を使用したオブジェクトの検出
この例では、You Only Look Once version 4 (YOLO v4) 深層学習ネットワークを使用して、イメージ内のオブジェクトを検出する方法を説明します。この例では、次の作業を行います。

YOLO v2 深層学習を使用したマルチクラス オブジェクト検出
YOLO v2 マルチクラス オブジェクト検出器に学習させ、選択したクラスとオーバーラップしきい値についてオブジェクト検出器のパフォーマンスを評価する。

Train Object Detectors in Experiment Manager
Use the Experiment Manager app to find optimal training options for object detectors.

イメージ ポイント機能を使用した要素の多いシーン内のオブジェクトの検出
この例では、オブジェクトの参照イメージがある場合に、要素の多いシーンで特定のオブジェクトを検出する方法を説明します。

混合ガウス モデルを使用した自動車の検出
この例では、混合ガウス モデル (GMM) に基づく前景検出器を使用してビデオ シーケンスから自動車を検出し、その数をカウントする方法を説明します。

事前学習済みの ONNX YOLO v2 オブジェクト検出器のインポート
事前学習済みの YOLO v2 オブジェクト検出器を ONNX 深層学習フレームワークからインポートします。
YOLO v2 オブジェクト検出器の ONNX へのエクスポート
事前学習済みの YOLO v2 オブジェクト検出器を ONNX 深層学習フレームワークへエクスポートします。

Generate Code for Detecting Objects in Images by Using ACF Object Detector
Generate code from a MATLAB® function that detects objects in images by using an acfObjectDetector object. When you intend to generate code from your MATLAB function that uses an acfObjectDetector object, you must create the object outside of the MATLAB function. The example explains how to modify the MATLAB code in ACF オブジェクト検出器を使用した一時停止標識検出器の学習 to support code generation.

YOLO v2 を使用したオブジェクト検出のコードの生成
YOLO v2 を使用してオブジェクト検出用の CUDA® コードを生成します。

シングル ショット マルチボックス検出器を使用したオブジェクト検出のコードの生成
SSD ネットワーク用の CUDA コードを生成します。

Code Generation for People Detection Using Deep Learning
Generate CUDA code for people detection