trainYOLOv2ObjectDetector
Train YOLO v2 object detector
Syntax
Description
trainedDetector = trainYOLOv2ObjectDetector(trainingData,detector,options)detector. The options
argument specifies training parameters for the detection network.
You can use this syntax for training an untrained detector or for fine-tuning a pretrained detector.
trainedDetector = trainYOLOv2ObjectDetector(trainingData,checkpoint,options)
You can use this syntax to:
Add more training data and continue the training.
Improve training accuracy by increasing the maximum number of iterations.
[
also returns information on the training progress, such as the training accuracy and
learning rate for each iteration.trainedDetector,info] = trainYOLOv2ObjectDetector(___)
___ = trainYOLOv2ObjectDetector(___,
uses additional options specified by one or more name-value arguments and any of the
previous inputs. For example, Name=Value)ExperimentMonitor=[] specifies not to
track metrics with the Experiment Manager (Deep Learning Toolbox)
app.
Examples
Load the training data for vehicle detection into the workspace.
data = load("vehicleTrainingData.mat");
trainingData = data.vehicleTrainingData;Specify the directory in which training samples are stored. Add full path to the file names in training data.
dataDir = fullfile(toolboxdir("vision"),"visiondata"); trainingData.imageFilename = fullfile(dataDir,trainingData.imageFilename);
Randomly shuffle data for training.
rng(0) shuffledIdx = randperm(height(trainingData)); trainingData = trainingData(shuffledIdx,:);
Create an imageDatastore using the files from the table.
imds = imageDatastore(trainingData.imageFilename);
Create a boxLabelDatastore using the label columns from the table.
blds = boxLabelDatastore(trainingData(:,2:end));
Combine the datastores.
ds = combine(imds,blds);
Specify the class names using the label columns from the table.
classes = trainingData.Properties.VariableNames(2:end);
Specify anchor boxes.
anchorBoxes = [8 8; 32 48; 40 24; 72 48];
Load a preinitialized YOLO v2 object detection network.
load("yolov2VehicleDetectorNet.mat","net");
Create the YOLO v2 object detection network.
detector = yolov2ObjectDetector(net,classes,anchorBoxes)
detector =
yolov2ObjectDetector with properties:
Network: [1×1 dlnetwork]
InputSize: [128 128 3]
TrainingImageSize: [128 128]
AnchorBoxes: [4×2 double]
ClassNames: vehicle
ReorganizeLayerSource: ''
LossFactors: [5 1 1 1]
ModelName: ''
Configure the network training options.
options = trainingOptions("sgdm", ... InitialLearnRate=0.001, ... Verbose=true, ... MiniBatchSize=16, ... MaxEpochs=30, ... Shuffle="never", ... VerboseFrequency=30, ... CheckpointPath=tempdir);
Train the YOLO v2 network.
[trainedDetector,info] = trainYOLOv2ObjectDetector(ds,detector,options);
************************************************************************* Training a YOLO v2 Object Detector for the following object classes: * vehicle Training on single CPU. |========================================================================================| | Epoch | Iteration | Time Elapsed | Mini-batch | Mini-batch | Base Learning | | | | (hh:mm:ss) | RMSE | Loss | Rate | |========================================================================================| | 1 | 1 | 00:00:00 | 7.13 | 50.8 | 0.0010 | | 2 | 30 | 00:00:06 | 1.32 | 1.8 | 0.0010 | | 4 | 60 | 00:00:12 | 0.93 | 0.9 | 0.0010 | | 5 | 90 | 00:00:19 | 0.64 | 0.4 | 0.0010 | | 7 | 120 | 00:00:27 | 0.58 | 0.3 | 0.0010 | | 9 | 150 | 00:00:34 | 0.64 | 0.4 | 0.0010 | | 10 | 180 | 00:00:40 | 0.46 | 0.2 | 0.0010 | | 12 | 210 | 00:00:47 | 0.40 | 0.2 | 0.0010 | | 14 | 240 | 00:00:53 | 0.58 | 0.3 | 0.0010 | | 15 | 270 | 00:01:00 | 0.40 | 0.2 | 0.0010 | | 17 | 300 | 00:01:07 | 0.37 | 0.1 | 0.0010 | | 19 | 330 | 00:01:14 | 0.50 | 0.2 | 0.0010 | | 20 | 360 | 00:01:20 | 0.37 | 0.1 | 0.0010 | | 22 | 390 | 00:01:26 | 0.36 | 0.1 | 0.0010 | | 24 | 420 | 00:01:32 | 0.43 | 0.2 | 0.0010 | | 25 | 450 | 00:01:38 | 0.54 | 0.3 | 0.0010 | | 27 | 480 | 00:01:45 | 0.54 | 0.3 | 0.0010 | | 29 | 510 | 00:01:52 | 0.66 | 0.4 | 0.0010 | | 30 | 540 | 00:01:58 | 0.38 | 0.1 | 0.0010 | |========================================================================================| Training finished: Max epochs completed. Detector training complete. *************************************************************************
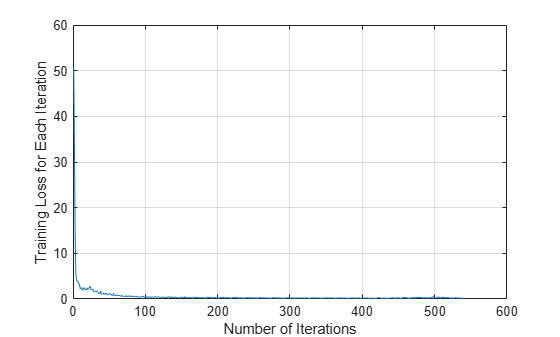
Verify the training accuracy by inspecting the training loss for each iteration.
figure plot(info.TrainingLoss) grid on xlabel("Number of Iterations") ylabel("Training Loss for Each Iteration")
Read a test image into the workspace.
img = imread("detectcars.png");Run the trained YOLO v2 object detector on the test image for vehicle detection.
[bboxes,scores] = detect(trainedDetector,img);
Display the detection results.
if(~isempty(bboxes)) img = insertObjectAnnotation(img,"rectangle",bboxes,scores); end figure imshow(img)

Input Arguments
Labeled ground truth images, specified as a datastore or a table.
If you use a datastore, your data must be set up so that calling the datastore with the
readandreadallfunctions returns a cell array or table with three columns. The second column must contain the bounding boxes, and the third column must contain the labels. The first column can contain image or point cloud data.data boxes labels The first column must be images.
M-by-4 matrices of bounding boxes of the form [x, y, width, height], where [x,y] represent the top-left coordinates of the bounding box.
The third column must be a cell array that contains M-by-1 categorical vectors containing object class names. All categorical data returned by the datastore must contain the same categories.
For more information, see Datastores for Deep Learning (Deep Learning Toolbox).
If you use a table, the table must have two or more columns. The first column of the table must contain image file names with paths. The images must be grayscale or truecolor (RGB) and they can be in any format supported by
imread. Each of the remaining columns must be a cell vector that contains M-by-4 matrices that represent a single object class, such as vehicle, flower, or stop sign. The columns contain 4-element double arrays of M bounding boxes in the format [x,y,width,height]. The format specifies the upper-left corner location and size of the bounding box in the corresponding image. To create a ground truth table, you can use the Image Labeler app or Video Labeler app. To create a table of training data from the generated ground truth, use theobjectDetectorTrainingDatafunction.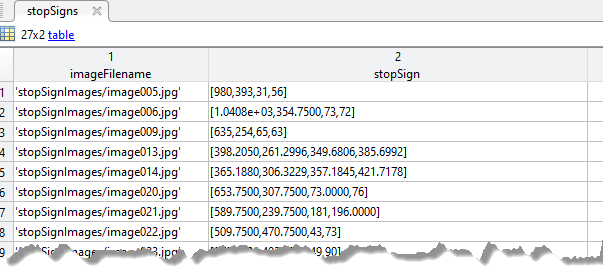
Note
When the training data is specified using a table, the
trainYOLOv2ObjectDetector function checks these conditions
The bounding box values must be integers. Otherwise, the function automatically rounds each noninteger values to its nearest integer.
The bounding box must not be empty and must be within the image region. While training the network, the function ignores empty bounding boxes and bounding boxes that lie partially or fully outside the image region.
Pretrained or untrained YOLO v2 object detector, specified as a yolov2ObjectDetector object. If detector is a
pretrained detector, then you can continue training the detector with additional
training data or perform more training iterations to improve detector accuracy.
Training options, specified as a TrainingOptionsSGDM,
TrainingOptionsRMSProp, or TrainingOptionsADAM
object returned by the trainingOptions (Deep Learning Toolbox) function. To specify the
solver name and other options for network training, use the trainingOptions (Deep Learning Toolbox) function.
Note
The trainYOLOv2ObjectDetector function does not support
these training options:
The
trainingOptionsShufflevalues,"once"and"every-epoch"are not supported when you use a datastore input.Datastore inputs are not supported when you set the
DispatchInBackgroundtraining option totrue.
Saved detector checkpoint, specified as a yolov2ObjectDetector object. To periodically save a detector checkpoint
during training, specify CheckpointPath. To control how frequently
check points are saved see the CheckPointFrequency and
CheckPointFrequencyUnit training options.
To load a checkpoint for a previously trained detector, load the MAT file from the
checkpoint path. For example, if the CheckpointPath property of the
object specified by options is "/checkpath", you
can load a checkpoint MAT file by using this code.
data = load("/checkpath/yolov2_checkpoint__216__2018_11_16__13_34_30.mat");
checkpoint = data.detector;The name of the MAT file includes the iteration number and timestamp of when the
detector checkpoint was saved. The detector is saved in the detector
variable of the file. Pass this file back into the
trainYOLOv2ObjectDetector function:
yoloDetector = trainYOLOv2ObjectDetector(trainingData,checkpoint,options);
Name-Value Arguments
Output Arguments
More About
Tips
To generate the ground truth, use the Image Labeler or Video Labeler app. To create a table of training data from the generated ground truth, use the
objectDetectorTrainingDatafunction.To improve prediction accuracy:
Increase the number of images you can use to train the network. You can expand the training dataset through data augmentation. For information on how to apply data augmentation for preprocessing, see Preprocess Images for Deep Learning (Deep Learning Toolbox).
Perform multiscale training by specifying an input detector whose
TrainingImageSizeproperty is a matrix with two or more rows. For each training epoch, thetrainYOLOv2ObjectDetectorfunction randomly resizes the input training images to one of the specified training image sizes.Choose anchor boxes appropriate to the dataset for training the network. You can use the
estimateAnchorBoxesfunction to compute anchor boxes directly from the training data.
References
[1] Joseph. R, S. K. Divvala, R. B. Girshick, and F. Ali. "You Only Look Once: Unified, Real-Time Object Detection." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 779–788. Las Vegas, NV: CVPR, 2016.
[2] Joseph. R and F. Ali. "YOLO 9000: Better, Faster, Stronger." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6517–6525. Honolulu, HI: CVPR, 2017.
Version History
Introduced in R2019aSee Also
Apps
Functions
trainingOptions(Deep Learning Toolbox) |objectDetectorTrainingData|trainYOLOv4ObjectDetector
Objects
Topics
- Create Custom YOLO v2 Object Detection Network
- Object Detection Using YOLO v2 Deep Learning
- Estimate Anchor Boxes from Training Data
- Code Generation for Object Detection by Using YOLO v2
- Train Object Detectors in Experiment Manager
- Getting Started with YOLO v2
- Get Started with Object Detection Using Deep Learning
- Choose an Object Detector
- Anchor Boxes for Object Detection
- Datastores for Deep Learning (Deep Learning Toolbox)