このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
YOLO v2 深層学習を使用したオブジェクトの検出
この例では、You Only Look Once (YOLO) v2 オブジェクト検出器に学習させる方法を説明します。
深層学習は、ロバストなオブジェクト検出器に学習させるために使用できる強力な機械学習手法です。オブジェクト検出の方法は、Faster R-CNN や You Only Look Once (YOLO) v2 など複数あります。この例では、関数 trainYOLOv2ObjectDetector を使用して、YOLO v2 車両検出器に学習させます。詳細については、YOLO v2 入門を参照してください。
事前学習済みの検出器のダウンロード
学習の完了を待たなくて済むように、事前学習済みの検出器をダウンロードします。検出器に学習させる場合は、変数 doTraining を true に設定します。
doTraining = false; if ~doTraining && ~exist("yolov2ResNet50VehicleExample_19b.mat","file") disp("Downloading pretrained detector (98 MB)..."); pretrainedURL = "https://www.mathworks.com/supportfiles/vision/data/yolov2ResNet50VehicleExample_19b.mat"; websave("yolov2ResNet50VehicleExample_19b.mat",pretrainedURL); end
Downloading pretrained detector (98 MB)...
データセットの読み込み
この例では、295 個のイメージを含んだ小さな車両データセットを使用します。これらのイメージの多くは、Caltech の Cars 1999 データ セットおよび Cars 2001 データ セットからのものです。Pietro Perona 氏によって作成されたもので、許可を得て使用しています。各イメージには、1 または 2 個のラベル付けされた車両インスタンスが含まれています。小さなデータセットは YOLO v2 の学習手順を調べるうえで役立ちますが、実際にロバストな検出器に学習させるにはラベル付けされたイメージがより多く必要になります。車両のイメージを解凍し、車両のグラウンド トゥルース データを読み込みます。
unzip vehicleDatasetImages.zip data = load("vehicleDatasetGroundTruth.mat"); vehicleDataset = data.vehicleDataset;
車両データは 2 列の table に保存されています。1 列目にはイメージ ファイルのパスが含まれ、2 列目には境界ボックスが含まれています。
% Display first few rows of the data set.
vehicleDataset(1:4,:)ans=4×2 table
imageFilename vehicle
_________________________________ _________________
{'vehicleImages/image_00001.jpg'} {[220 136 35 28]}
{'vehicleImages/image_00002.jpg'} {[175 126 61 45]}
{'vehicleImages/image_00003.jpg'} {[108 120 45 33]}
{'vehicleImages/image_00004.jpg'} {[124 112 38 36]}
% Add the full path to the local vehicle data folder.
vehicleDataset.imageFilename = fullfile(pwd,vehicleDataset.imageFilename);データセットは学習、検証、テスト用のセットに分割します。データの 60% を学習用に、10% を検証用に、残りを学習済みの検出器のテスト用に選択します。
rng("default");
shuffledIndices = randperm(height(vehicleDataset));
idx = floor(0.6 * length(shuffledIndices) );
trainingIdx = 1:idx;
trainingDataTbl = vehicleDataset(shuffledIndices(trainingIdx),:);
validationIdx = idx+1 : idx + 1 + floor(0.1 * length(shuffledIndices) );
validationDataTbl = vehicleDataset(shuffledIndices(validationIdx),:);
testIdx = validationIdx(end)+1 : length(shuffledIndices);
testDataTbl = vehicleDataset(shuffledIndices(testIdx),:);imageDatastore と boxLabelDatastore を使用し、学習中および評価中にイメージとラベル データを読み込むためのデータストアを作成します。
imdsTrain = imageDatastore(trainingDataTbl{:,"imageFilename"});
bldsTrain = boxLabelDatastore(trainingDataTbl(:,"vehicle"));
imdsValidation = imageDatastore(validationDataTbl{:,"imageFilename"});
bldsValidation = boxLabelDatastore(validationDataTbl(:,"vehicle"));
imdsTest = imageDatastore(testDataTbl{:,"imageFilename"});
bldsTest = boxLabelDatastore(testDataTbl(:,"vehicle"));イメージ データストアとボックス ラベル データストアを組み合わせます。
trainingData = combine(imdsTrain,bldsTrain); validationData = combine(imdsValidation,bldsValidation); testData = combine(imdsTest,bldsTest);
学習イメージとボックス ラベルのうちの 1 つを表示します。
data = read(trainingData);
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,"rectangle",bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
YOLO v2 オブジェクト検出ネットワークの作成
YOLO v2 オブジェクトの検出ネットワークは、特徴抽出ネットワークと、その後に続く検出ネットワークという、2 つのサブネットワークで構成されます。通常、特徴抽出ネットワークは事前学習済みの CNN です (詳細については事前学習済みの深層ニューラル ネットワーク (Deep Learning Toolbox)を参照)。この例では特徴抽出に ResNet-50 を使用します。用途の要件によって、MobileNet v2 や ResNet-18 など、その他の事前学習済みのネットワークも使用できます。検出サブネットワークは特徴抽出ネットワークと比べて小さい CNN であり、少数の畳み込み層と YOLO v2 に固有の層で構成されます。
最初に、ネットワーク入力サイズとクラス数を指定します。ネットワーク入力サイズを選択する際には、ネットワーク自体に必要な最小サイズ、学習イメージのサイズ、選択したサイズでのデータの処理によって発生する計算コストを考慮します。可能な場合、学習イメージのサイズに近く、ネットワークに必要な入力サイズより大きいネットワーク入力サイズを選択します。例の実行にかかる計算コストを削減するには、ネットワーク入力サイズをネットワークの実行に必要な最小サイズである [224 224 3] に指定します。
inputSize = [224 224 3];
検出するオブジェクト クラスの名前を指定します。
classes = "vehicle";この例で使用される学習イメージのサイズはさまざまであり、ネットワーク入力サイズ (224×224) よりも大きいことに注意してください。これを修正するには、学習前の前処理ステップでイメージのサイズを変更します。
次に、estimateAnchorBoxes を使用して、学習データ内のオブジェクトのサイズに基づいてアンカー ボックスを推定します。学習前のイメージのサイズ変更を考慮するには、アンカー ボックスを推定する学習データのサイズを変更します。transform を使用して学習データの前処理を行い、アンカー ボックスの数を定義してアンカー ボックスを推定します。サポート関数 preprocessData を使用して、学習データのサイズをネットワークの入力イメージ サイズに変更します。
trainingDataForEstimation = transform(trainingData,@(data)preprocessData(data,inputSize)); numAnchors = 7; [anchorBoxes,meanIoU] = estimateAnchorBoxes(trainingDataForEstimation,numAnchors)
anchorBoxes = 7×2
40 38
156 127
74 71
135 121
36 25
56 52
98 89
meanIoU = 0.8383
アンカー ボックスの選択の詳細については、学習データからのアンカー ボックスの推定 (Computer Vision Toolbox™) およびアンカー ボックスによるオブジェクトの検出を参照してください。
事前学習済みの ResNet-50 モデルを読み込みます。
baseNet = imagePretrainedNetwork("resnet50");検出ネットワーク ソースとして "activation_40_relu" を選択し、"activation_40_relu" の後の層を検出サブネットワークに置き換えます。この検出ネットワーク ソース層は、係数 16 でダウンサンプリングされた特徴マップを出力します。このダウンサンプリングの量は、空間分解能と抽出される特徴の強度との適切なトレードオフです (ネットワークでさらに抽出された特徴により、より強力なイメージの特徴が符号化されますが、空間分解能は低下します)。最適な特徴抽出層を選択するには経験的解析が必要です。
detectionSource = "activation_40_relu";YOLO v2 オブジェクト検出ネットワークを作成します。
detector = yolov2ObjectDetector(baseNet,classes,anchorBoxes,DetectionNetworkSource=detectionSource);
Deep Learning Toolbox™ から analyzeNetwork またはディープ ネットワーク デザイナーを使用してネットワークを可視化できます。
データ拡張
データ拡張は、学習中に元のデータをランダムに変換してネットワークの精度を高めるために使用されます。データ拡張を使用すると、ラベル付き学習サンプルの数を実際に増やさずに、学習データをさらに多様化させることができます。
transform を使用して、イメージと関連するボックス ラベルを水平方向にランダムに反転させることによって学習データを拡張します。データ拡張は、テスト データと検証データには適用されないことに注意してください。理想的には、テスト データと検証データは元のデータを代表するもので、バイアスのない評価を行うために変更なしで使用されなければなりません。
augmentedTrainingData = transform(trainingData,@augmentData);
同じイメージを複数回読み取り、拡張された学習データを表示します。
augmentedData = cell(4,1); for k = 1:4 data = read(augmentedTrainingData); augmentedData{k} = insertShape(data{1},"rectangle",data{2}); reset(augmentedTrainingData); end figure montage(augmentedData,BorderSize=10)

学習データの前処理
拡張された学習データと検証データを前処理して学習用に準備します。
preprocessedTrainingData = transform(augmentedTrainingData,@(data)preprocessData(data,inputSize)); preprocessedValidationData = transform(validationData,@(data)preprocessData(data,inputSize));
前処理された学習データを読み取ります。
data = read(preprocessedTrainingData);
イメージと境界ボックスを表示します。
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,"rectangle",bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
YOLO v2 オブジェクト検出器に学習させる
trainingOptions を使用してネットワーク学習オプションを指定します。ValidationData を前処理済みの検証データに設定します。CheckpointPath を一時的な場所に設定します。これにより、学習プロセス中に部分的に学習させた検出器を保存できます。停電やシステム障害などで学習が中断された場合に、保存したチェックポイントから学習を再開できます。
options = trainingOptions("adam", ... MiniBatchSize=16, .... InitialLearnRate=1e-3, ... MaxEpochs=10, ... CheckpointPath=tempdir, ... ValidationData=preprocessedValidationData);
doTraining が true の場合、trainYOLOv2ObjectDetector関数を使用して YOLO v2 オブジェクト検出器に学習させます。そうでない場合は、事前学習済みのネットワークを読み込みます。
if doTraining % Train the YOLO v2 detector. [detector,info] = trainYOLOv2ObjectDetector(preprocessedTrainingData,detector,options); else % Load pretrained detector for the example. pretrained = load("yolov2ResNet50VehicleExample_19b.mat"); detector = pretrained.detector; end
このネットワークの学習には、12 GB のメモリを搭載した NVIDIA™ Titan X GPU を使用して約 7 分かかりました。学習時間は使用するハードウェアによって異なります。GPU のメモリがこれより少ない場合、メモリ不足が発生する可能性があります。これが発生した場合は、trainingOptions 関数を使用して MiniBatchSize を減らします。
迅速なテストとして、1 つのテスト イメージ上で検出器を実行します。イメージのサイズを変更して学習イメージと同じサイズにします。
I = imread("highway.png");
I = imresize(I,inputSize(1:2));
[bboxes,scores] = detect(detector,I);結果を表示します。
I = insertObjectAnnotation(I,"rectangle",bboxes,scores);
figure
imshow(I)
テスト セットを使用した検出器の評価
大規模なイメージ セットで学習済みのオブジェクト検出器を評価し、パフォーマンスを測定します。Computer Vision Toolbox™ には、平均適合率や対数平均ミス率などの一般的なメトリクスを測定するためのオブジェクト検出器評価関数 (evaluateObjectDetection) が用意されています。この例では、平均適合率メトリクスを使用してパフォーマンスを評価します。平均適合率は、検出器が正しい分類を実行できること (適合率) と検出器がすべての関連オブジェクトを検出できること (再現率) を示す単一の数値です。
学習データと同じ前処理変換をテスト データに適用します。データ拡張はテスト データには適用されないことに注意してください。テスト データは元のデータを代表するもので、バイアスのない評価を行うために変更なしで使用されなければなりません。
preprocessedTestData = transform(testData,@(data)preprocessData(data,inputSize));
すべてのテスト イメージに対して検出器を実行します。できるだけ多くのオブジェクトを検出するには、検出しきい値を低い値に設定します。これは、検出器の適合率を、再現率の値の全範囲にわたって評価するのに役立ちます。
detectionThreshold = 0.01; detectionResults = detect(detector,preprocessedTestData,Threshold=detectionThreshold);
テスト データ セットでオブジェクト検出器を評価します。
metrics = evaluateObjectDetection(detectionResults,preprocessedTestData);
平均適合率 (AP) メトリクスと適合率/再現率 (PR) 曲線を計算します。適合率/再現率曲線は、再現率のさまざまなレベルにおける検出器の適合率を示します。すべてのレベルの再現率で適合率が 1 になるのが理想的です。より多くのデータを使用すると平均適合率を向上できますが、学習に必要な時間が長くなる場合があります。
AP = averagePrecision(metrics,ClassName="vehicle"); [precision, recall] = precisionRecall(metrics,ClassName="vehicle");
PR 曲線をプロットし、AP を表示します。
figure
plot(recall{:},precision{:})
xlabel("Recall")
ylabel("Precision")
grid on
title("Average Precision = "+AP)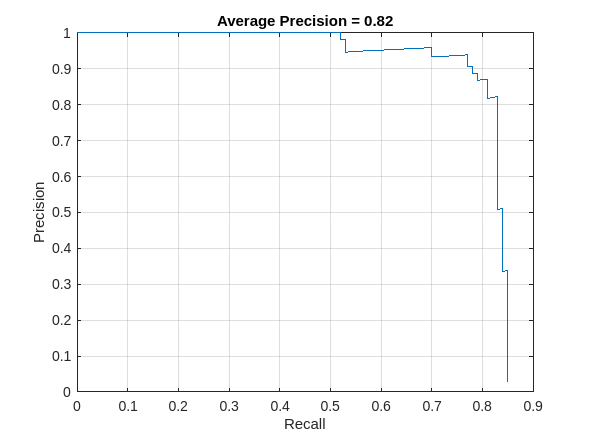
コード生成
検出器に学習させて評価したら、GPU Coder™ を使用して yolov2ObjectDetector のコードを生成できます。詳細については、YOLO v2 を使用したオブジェクト検出のコードの生成 (GPU Coder)の例を参照してください。
サポート関数
function B = augmentData(A) % Apply random horizontal flipping, and random X/Y scaling. Boxes that get % scaled outside the bounds are clipped if the overlap is above 0.25. Also, % jitter image color. B = cell(size(A)); I = A{1}; sz = size(I); if numel(sz)==3 && sz(3) == 3 I = jitterColorHSV(I ,... Contrast=0.2, ... Hue=0, ... Saturation=0.1, ... Brightness=0.2); end % Randomly flip and scale image. tform = randomAffine2d(XReflection=true,Scale=[1 1.1]); rout = affineOutputView(sz,tform,BoundsStyle="CenterOutput"); B{1} = imwarp(I,tform,OutputView=rout); % Sanitize boxes, if needed. This helper function is attached as a % supporting file. Open the example in MATLAB to access this function. A{2} = helperSanitizeBoxes(A{2}); % Apply same transform to boxes. [B{2},indices] = bboxwarp(A{2},tform,rout,OverlapThreshold=0.25); B{3} = A{3}(indices); % Return original data only when all boxes are removed by warping. if isempty(indices) B = A; end end function data = preprocessData(data,targetSize) % Resize image and bounding boxes to the targetSize. sz = size(data{1},[1 2]); scale = targetSize(1:2)./sz; data{1} = imresize(data{1},targetSize(1:2)); % Sanitize boxes, if needed. This helper function is attached as a % supporting file. Open the example in MATLAB to access this function. data{2} = helperSanitizeBoxes(data{2}); % Resize boxes to new image size. data{2} = bboxresize(data{2},scale); end
参考文献
[1] Redmon, Joseph, and Ali Farhadi. "YOLO9000: Better, Faster, Stronger." In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6517–25. Honolulu, HI: IEEE, 2017. https://doi.org/10.1109/CVPR.2017.690.
参考
yolov2ObjectDetector |
trainYOLOv2ObjectDetector