このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
深層学習を使用したオブジェクト検出入門
深層学習を使用したオブジェクト検出は、イメージ内のオブジェクトの位置を予測するための迅速で正確な手段を提供します。深層学習は、オブジェクト検出器が検出タスクに必要なイメージの特徴を自動的に学習する強力な機械学習手法です。Computer Vision Toolbox™ には、YOLO (You Only Look Once) v2、YOLO v3、YOLO v4、YOLOX、RTMDet、シングル ショット検出 (SSD) など、深層学習を使用したオブジェクト検出のためのさまざまな手法が用意されています。

オブジェクト検出は次のような用途で使用されます。
シーン理解
マルチオブジェクト トラッキング
外観検査
自動運転車
監視
Computer Vision Toolbox とそのサポート パッケージを使用すると、事前学習済みのオブジェクト検出の構成、カスタムのオブジェクト検出ネットワークの設計、事前学習済みまたは学習済みのネットワークを使用した推論、およびカスタム データ セットによる転移学習を行うことができます。
事前学習済みのネットワークを使用したイメージ内のオブジェクト検出を開始するには、事前学習済みのオブジェクト検出ネットワークを使用したオブジェクトの検出のセクションを参照してください。
学習させていないオブジェクト検出ネットワークや事前学習済みのオブジェクト検出ネットワークの転移学習用の学習を開始するには、オブジェクト検出ネットワークの学習と転移学習の実行のセクションを参照してください。
ディープ ネットワーク デザイナー (Deep Learning Toolbox) アプリを使用して、カスタム ネットワークを 1 層ずつ設計することもできます。YOLO v2 オブジェクト検出ネットワークの使用例については、事前学習済みの YOLO v2 検出器を使用した転移学習の実行を参照してください。
事前学習済みのオブジェクト検出ネットワークを使用したオブジェクトの検出
Computer Vision Toolbox には、カスタム データ セットによる推論や転移学習をすぐに実行できる事前学習済みのオブジェクト検出モデルが用意されています。
事前学習済みモデルの構成
事前学習済みオブジェクト検出モデルを使用するには、最初に事前学習済みのオブジェクト検出モデルをダウンロードしてインストールしなければなりません。アドオン エクスプローラーを使用し、事前学習済みのモデル サポート パッケージをダウンロードしてインストールできます。アドオンのインストールの詳細については、アドオンの取得と管理を参照してください。
次の表に、オブジェクト検出器オブジェクトの名前、対応する利用可能な事前学習済みモデル、およびダウンロードが必要な対応するアドオン サポート パッケージの名前の一覧を示します。
| オブジェクト検出モデル | 利用可能な事前学習済みモデル | サポート パッケージの名前 |
|---|---|---|
yolov2ObjectDetector |
| Computer Vision Toolbox Model for YOLO v2 Object Detection |
yolov3ObjectDetector |
| Computer Vision Toolbox Model for YOLO v3 Object Detection |
yolov4ObjectDetector |
| Computer Vision Toolbox Model for YOLO v4 Object Detection |
yoloxObjectDetector |
| Automated Visual Inspection Library for Computer Vision Toolbox |
| Computer Vision Toolbox Model for RTMDet Object Detection |
事前学習済みモデルを使用した推論の実行
事前学習済みの検出器モデルを使用して推論を実行し、テスト イメージ内のオブジェクトを検出します。用途に応じて事前学習済みのオブジェクト検出ネットワークを選択する方法については、オブジェクト検出器の選択を参照してください。境界ボックス、信頼度スコア、および対応するクラス ラベルを返すには、対応する detect オブジェクト関数に事前学習済み検出器オブジェクトを渡します。
たとえば、事前学習済みモデルの構成のセクションでリストされている事前学習済み YOLO v4 tiny-yolov4-coco ネットワークを使用するには、yolov4ObjectDetector オブジェクトを作成してモデルを読み込みます。
detector = yolov4ObjectDetector("tiny-yolov4-coco");
yolov4ObjectDetector オブジェクトの detect オブジェクト関数を使用して、テスト イメージ I 内のオブジェクトを検出します。
I = imread("carsonroad.png");
[bboxes,scores,labels] = detect(detector,I);insertObjectAnnotation 関数を使用して、入力イメージに結果を重ねて表示します。
detectedImg = insertObjectAnnotation(I,"Rectangle",bboxes,labels);
figure
imshow(detectedImg)

学習済みのオブジェクト検出ネットワークを使用してテスト イメージの推論を実行するには、同じ処理を使用しますが、学習済みのネットワークを detect 関数の detector 引数として指定します。
MathWorks GitHub の事前学習済みのネットワーク
MathWorks® GitHub リポジトリでは、ダウンロードして使用できる最新の事前学習済みオブジェクト検出深層学習ネットワークの実装を提供しており、すぐに推論を実行できます。事前学習済みのオブジェクト検出ネットワークは、COCO データ セットや Pascal VOC データ セットなどの標準データ セットについて学習済みです。これらの事前学習済みモデルを直接使用して、テスト イメージ内のさまざまなオブジェクトを検出できます。
最新の MathWorks 事前学習済みオブジェクト検出器の一覧については、MATLAB Deep Learning (GitHub) を参照してください。
オブジェクト検出ネットワークの学習と転移学習の実行
追加のクラスを検出するようにネットワークを変更する場合、またはネットワークの他のパラメーターをカスタマイズする場合は、転移学習を実行できます。このセクションでは、学習データを準備し、オブジェクト検出ネットワークを構成し、ネットワークに学習させて転移学習を実行する方法を説明します。
学習データの作成
ラベル付けアプリを使用して、ビデオ、イメージ シーケンス、イメージ コレクション、またはカスタム データ ソースのグラウンド トゥルース データに対話形式でラベルを付けます。イメージ内のオブジェクトの位置とサイズを定義する四角形のラベルを使用して、オブジェクト検出グラウンド トゥルースにラベルを付けることができます。

オブジェクト検出用のイメージのラベル付けに関する詳細については、次のトピックを参照してください。
データの拡張と前処理
データ拡張を使用して、限られたデータ セットでオブジェクト検出器に学習させます。平行移動、切り取り、変換といった、影響の少ない方法でデータ セットのイメージを変更することで、明確に区別された一意の学習データを作成し、よりロバストな検出器を作成することができます。データストアを使用すると、データのコレクションを簡単に読み取って拡張することができます。イメージのデータストアとラベル付き境界ボックス データのデータストアを作成するには、それぞれ imageDatastore および boxLabelDatastore を使用します。
学習データの拡張と前処理の詳細については、次のトピックを参照してください。
データストアを使用して学習データを拡張する方法の詳細については、深層学習用のデータストア (Deep Learning Toolbox)および組み込みデータストアを使用した追加のイメージ処理演算の実行 (Deep Learning Toolbox)を参照してください。
オブジェクト検出器の学習
オブジェクト検出ネットワークに学習させるには、オブジェクト検出モデルに対応する学習関数を使用します。たとえば、yolov4ObjectDetector オブジェクトを使用して検出器を構成する場合は、trainYOLOv4ObjectDetector 関数を使用します。
trainingOptions (Deep Learning Toolbox) 関数を使用してネットワークの学習オプションを指定します。実験マネージャー (Deep Learning Toolbox)アプリを使用して学習オプションのパラメーターを決定できます。実験マネージャーを使用したハイパーパラメーター調整の詳細については、Train Object Detectors in Experiment Managerを参照してください。
学習、推論、結果の評価の詳細については、次の例を参照してください。
オブジェクト検出器のパフォーマンスの評価と微調整
包括的なメトリクス セットを使用して、グラウンド トゥルースに照らし合わせて学習結果を評価するには、evaluateObjectDetection 関数を使用します。この関数は、オブジェクト検出メトリクスを objectDetectionMetrics オブジェクトとして返します。以下の objectDetectionMetrics オブジェクト関数を使用し、すべての (または一部の) クラスおよびオーバーラップしきい値についてメトリクスを評価します。
objectDetectionMetrics オブジェクト関数 | 使用方法 |
|---|---|
データ セット内のすべてのクラスまたは一部のクラスの平均適合率 (AP) とオーバーラップ (Intersection Over Union) しきい値を計算します。 | |
データ セット内のすべてのクラス、または指定されたクラスとオーバーラップしきい値の適合率、再現率、信頼度スコアを計算します。 | |
confusionMatrix | 指定された信頼度スコアのしきい値、またはオーバーラップしきい値における混同行列と正規化混同行列を計算します。 |
summarize | データ セット全体または各クラスについて、オブジェクト検出メトリクスの要約を計算します。 |
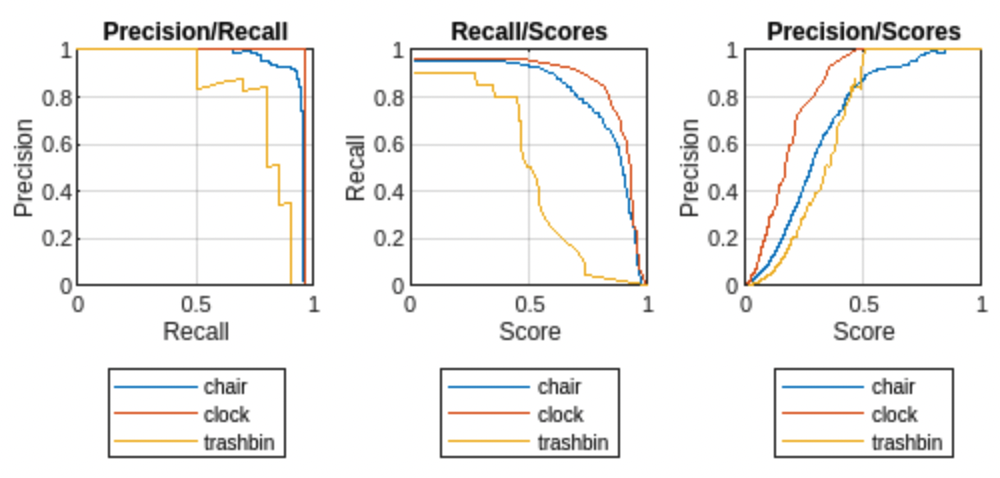
オブジェクト検出メトリクスを使用してオブジェクト検出器の評価および微調整を行う方法を示す例については、YOLO v2 深層学習を使用したマルチクラス オブジェクト検出の例を参照してください。次のイメージは、データ セット内の選択されたクラスのサンプルの適合率-再現率 (PR) プロット、および信頼度スコアの関数として表された再現率と適合率のプロットの例を示しています。