SSD マルチボックス検出入門
シングル ショット マルチボックス検出器 (SSD) は、single stage オブジェクト検出ネットワークを使用して、マルチスケールの特徴から予測した検出結果をマージします。SSD は、Faster R-CNN 検出器のような 2 段階の検出器よりも高速です。また、YOLO v2 検出器のような single スケール特徴検出器よりも正確にオブジェクトの位置推定ができます。
SSD は入力イメージに対して深層学習 CNN を実行し、複数の特徴マップからネットワーク予測を生成します。このオブジェクト検出器は予測結果を収集して復号化し、境界ボックスを生成します。

イメージ内のオブジェクトの検出
SSD は、検出されたオブジェクトの位置を境界ボックスのセットとして返します。SSD は、各アンカー ボックスの次の 2 つの属性を予測します。
アンカー ボックスのオフセット — アンカー ボックスの位置を調整します。
クラス確率 — 各アンカー ボックスに割り当てられるクラス ラベルを予測します。
次の図は、特徴マップ内の各位置の事前定義されたアンカー ボックス (破線) と、オフセットの適用後の調整された位置を示します。クラスと一致したボックスは青色とオレンジ色で表示されます。詳細については、アンカー ボックスによるオブジェクトの検出を参照してください。

SSD 検出ネットワークの設計
関数 ssdObjectDetector を使用すると、プログラムでカスタム SSD モデルを設計できます。
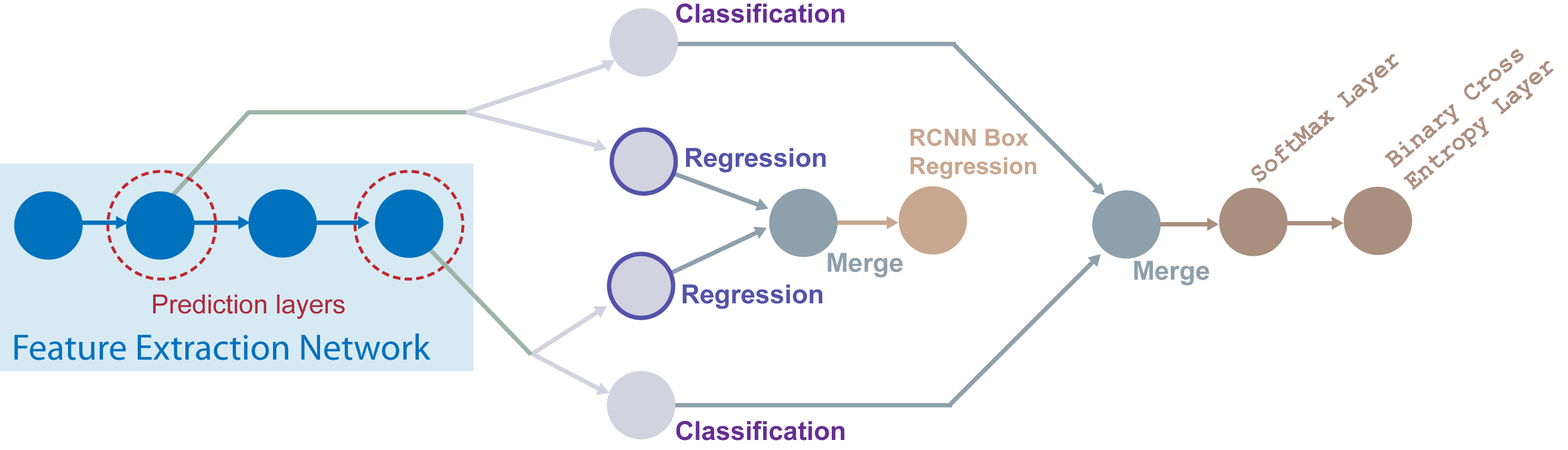
SSD マルチボックス検出ネットワークを設計するには、次の手順に従います。
事前学習済みまたは未学習の CNN である特徴抽出ネットワークから、モデルを開始します。
特徴抽出ネットワークから予測層を選択します。特徴抽出ネットワークの層はどれでも、予測層として使用できます。オブジェクト検出にマルチスケールの特徴を使用する利点を活かすためには、サイズの異なる特徴マップを選択してください。
ssdObjectDetectorオブジェクトへの検出ネットワーク ソース入力として、予測層の名前を指定します。また、クラスとアンカー ボックスの名前を入力として指定し、学習用の検出器を構成します。
ssdObjectDetector オブジェクトは、予測層の出力を分類分岐と回帰分岐に接続します。分類分岐は、タイル配置された各アンカー ボックスのクラスを予測します。回帰分岐は、アンカー ボックスのオフセットを予測します。
ssdObjectDetectorオブジェクトは、マージ層を使用して、すべての予測層からの分類分岐の出力を統合します。次に、分類分岐のマージ層からの出力はソフトマックス層に接続され、その後にバイナリ交差エントロピー層が続きます。分類分岐は、バイナリ交差エントロピー関数を使用して分類損失を計算します。同様に、
ssdObjectDetectorオブジェクトは、マージ層を使用して、すべての予測層からの回帰分岐の出力を統合します。次に、回帰分岐のマージ層からの出力は、境界ボックス回帰層に接続されます。回帰分岐は、滑らかな L1 関数を使用して境界ボックスの損失を計算します。
SSD モデルを使用したオブジェクト検出器の学習とオブジェクトの検出
SSD オブジェクト検出ネットワークに学習させるには、trainSSDObjectDetector 関数を使用します。詳細については、Train SSD Object Detectorを参照してください。
detect 関数を使用してイメージ内のオブジェクトを検出します。例については、SSD 深層学習を使用したオブジェクト検出を参照してください。
転移学習
転移学習を使用すると、SSD 検出ネットワークで事前学習済みの CNN を特徴抽出器として使用できます。ssdObjectDetector 関数を使用して、MobileNet-v2 などの事前学習済みの CNN から SSD 検出ネットワークを作成します。事前学習済みの CNN の一覧については、事前学習済みの深層ニューラル ネットワーク (Deep Learning Toolbox)を参照してください。
コード生成
SSD オブジェクト検出器 (ssdObjectDetector オブジェクトを使用して作成) を使用した CUDA® コードの生成方法の詳細については、シングル ショット マルチボックス検出器を使用したオブジェクト検出のコードの生成を参照してください。
深層学習用学習データのラベル付け
イメージ ラベラー、ビデオ ラベラー、またはグラウンド トゥルース ラベラー (Automated Driving Toolbox) アプリを使用して、対話形式でピクセルにラベル付けし、ラベル データを学習用にエクスポートできます。アプリは、オブジェクト検出用の四角形の関心領域 (ROI)、イメージ分類用のシーン ラベル、セマンティック セグメンテーション用のピクセルにラベルを付けるためにも使用できます。いずれかのラベラーでエクスポートされたグラウンド トゥルース オブジェクトから学習データを作成するには、関数 objectDetectorTrainingData または関数 pixelLabelTrainingData を使用できます。詳細については、オブジェクト検出およびセマンティック セグメンテーション用の学習データを参照してください。
参照
[1] Liu, Wei, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C. Berg. "SSD: Single Shot MultiBox Detector." In Computer Vision – ECCV 2016, edited by Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, 9905:21-37. Cham: Springer International Publishing, 2016. https://doi.org/10.1007/978-3-319-46448-0_2.
参考
アプリ
- イメージ ラベラー | グラウンド トゥルース ラベラー (Automated Driving Toolbox) | ビデオ ラベラー | ディープ ネットワーク デザイナー (Deep Learning Toolbox)
オブジェクト
関数
trainSSDObjectDetector|detect|analyzeNetwork(Deep Learning Toolbox)
トピック
- SSD 深層学習を使用したオブジェクト検出
- 深層学習を使用したオブジェクト検出入門
- オブジェクト検出器の選択
- アンカー ボックスによるオブジェクトの検出
- MATLAB による深層学習 (Deep Learning Toolbox)
- 事前学習済みの深層ニューラル ネットワーク (Deep Learning Toolbox)