実験マネージャー
深層学習ネットワークの学習および比較に向けた実験の作成と実行
説明
実験マネージャー アプリを使用すると、異なる学習条件でネットワークに学習させて結果を比較するための深層学習実験を作成できます。実験マネージャーを使用すると、たとえば以下を行うことができます。
ハイパーパラメーター値の範囲のスイープ、ベイズ最適化の使用による最適な学習オプションの検出、または確率分布からのハイパーパラメーター値の無作為抽出。ベイズ最適化および無作為抽出の手法を使用するには、Statistics and Machine Learning Toolbox™ が必要です。
組み込み関数
trainnetの使用、または独自のカスタム学習関数の定義。さまざまなデータ セットを使用した結果の比較、またはさまざまな深いネットワークのアーキテクチャのテスト。
実験をすばやくセットアップするために、事前構成済みのテンプレートを使用して開始できます。実験テンプレートは、イメージ分類とイメージ回帰、シーケンス分類、オーディオ分類、信号処理、セマンティック セグメンテーション、およびカスタム学習ループといったワークフローをサポートします。
[実験ブラウザー] パネルには、プロジェクトの実験と結果の階層が表示されます。実験名の横にあるアイコンは、実験のタイプを表します。
 — 学習関数
— 学習関数 trainnetを使用する組み込み学習実験 — カスタム学習関数を使用するカスタムの学習実験
— カスタム学習関数を使用するカスタムの学習実験 — ユーザーが作成した実験関数を使用する汎用の実験
— ユーザーが作成した実験関数を使用する汎用の実験
このページには、Deep Learning Toolbox™ 用の組み込み学習実験とカスタムの学習実験に関する情報を掲載しています。アプリの使用に関する一般的な情報については、実験マネージャーを参照してください。実験マネージャー アプリを分類学習器アプリおよび回帰学習器アプリと組み合わせて使用する方法の詳細については、実験マネージャー (Statistics and Machine Learning Toolbox)を参照してください。
必要な製品
Deep Learning Toolbox を使用して、深層学習のための組み込みまたはカスタムの学習実験を実行し、それらの実験の混同行列を表示する。
Statistics and Machine Learning Toolbox を使用して、ベイズ最適化を使用する機械学習および実験のためのカスタムの学習実験を実行する。
Parallel Computing Toolbox™ を使用して、複数の GPU、1 つのクラスター、またはクラウドで、複数の試行を同時に実行したり、単一の試行を実行したりする。詳細については、Run Experiments in Parallelを参照してください。
MATLAB® Parallel Server™ を使用して、リモート クラスターのバッチ ジョブとして実験をオフロードする。詳細については、Offload Experiments as Batch Jobs to a Clusterを参照してください。
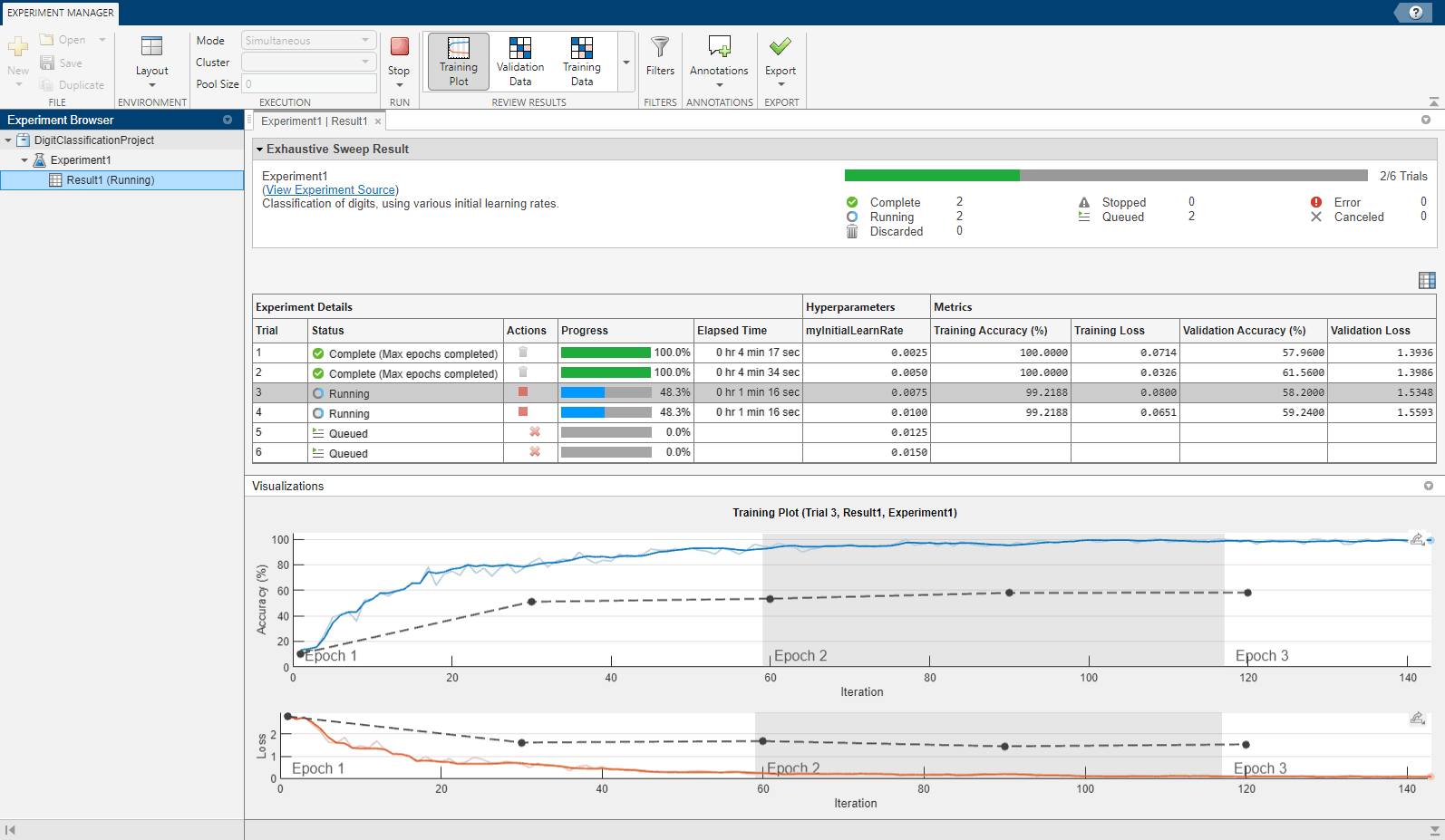
実験マネージャー アプリを開く
MATLAB ツールストリップ: [アプリ] タブの [MATLAB] にある [実験マネージャー] アイコンをクリックします。
MATLAB コマンド プロンプト:
experimentManagerと入力します。
アプリの使用に関する一般的な情報については、実験マネージャーを参照してください。
例
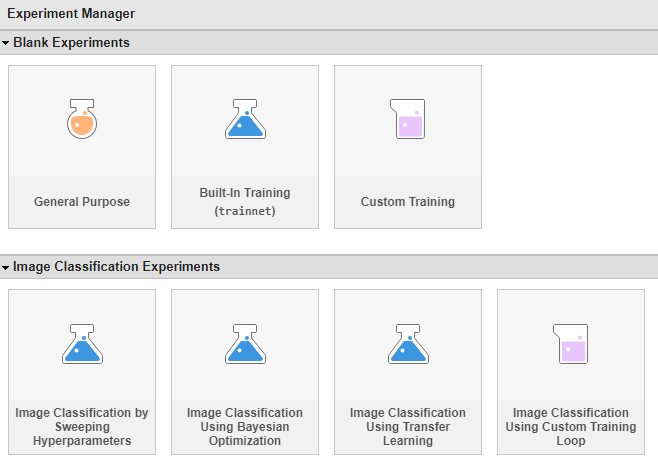
事前構成済みの実験テンプレートを使用して、実験を迅速にセットアップします。
実験マネージャー アプリを開きます。ダイアログ ボックスで、新規プロジェクトを作成するか、ドキュメンテーションのサンプルを開きます。[新規] で [空のプロジェクト] を選択します。
次のダイアログ ボックスで、空の実験テンプレートを開くか、AI ワークフローをサポートするように事前構成されたいずれかの実験テンプレートを開きます。たとえば、[イメージ分類実験] で、事前構成済みのテンプレート [ハイパーパラメーターのスイープによるイメージ分類] を選択します。
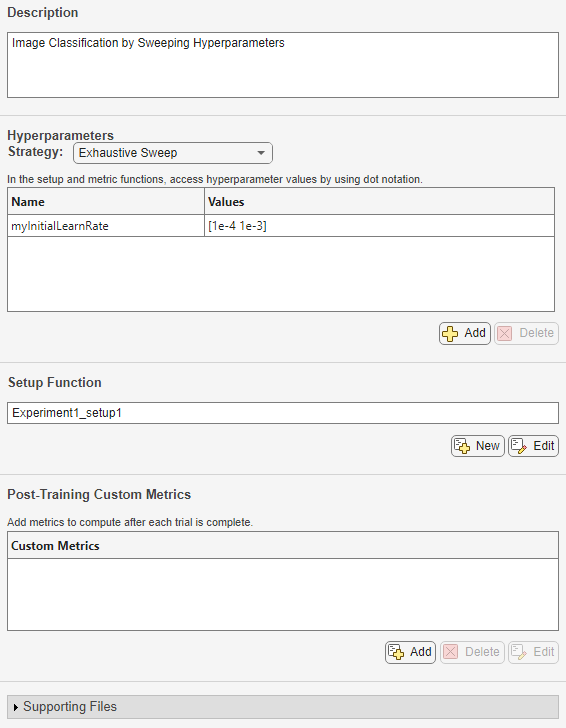
新しいプロジェクトの名前と場所を指定します。実験マネージャーによって、プロジェクトで新しい実験が開きます。
この実験は、![]() アイコンが示すように、学習関数
アイコンが示すように、学習関数 trainnet を使用する組み込み学習実験です。
実験定義タブに、実験を定義する説明、ハイパーパラメーター、セットアップ関数、学習後のカスタム メトリクス、およびサポート ファイルが表示されます。これらのパラメーターを変更することで、実験を迅速にセットアップして実行することができます。
実験パラメーターの構成後に実験を実行して結果を比較する方法の詳細については、実験マネージャーを参照してください。
関数 trainnet およびハイパーパラメーターの網羅的なスイープを使用して学習を行う実験をセットアップします。組み込み学習実験は、イメージ、シーケンス、時系列、特徴の分類や回帰などのワークフローをサポートします。
実験マネージャー アプリを開きます。ダイアログ ボックスで、新規プロジェクトを作成するか、ドキュメンテーションのサンプルを開きます。[新規] で [空のプロジェクト] を選択します。
次のダイアログ ボックスで、空の実験テンプレートを開くか、AI ワークフローをサポートするように事前構成されたいずれかの実験テンプレートを開きます。[空の実験] で、空のテンプレート [組み込み学習 (trainnet)] を選択します。
この実験は、![]() アイコンが示すように、学習関数
アイコンが示すように、学習関数 trainnet を使用する組み込み学習実験です。
実験定義タブに、実験を定義する説明、ハイパーパラメーター、セットアップ関数、学習後のカスタム メトリクス、およびサポート ファイルが表示されます。空の実験テンプレートで開始する場合、これらのパラメーターを手動で構成しなければなりません。パラメーターがある程度事前構成されたテンプレートを使用する場合は、代わりに、実験マネージャーのダイアログ ボックスから事前構成済みの組み込み学習テンプレートのいずれか 1 つを選択します。
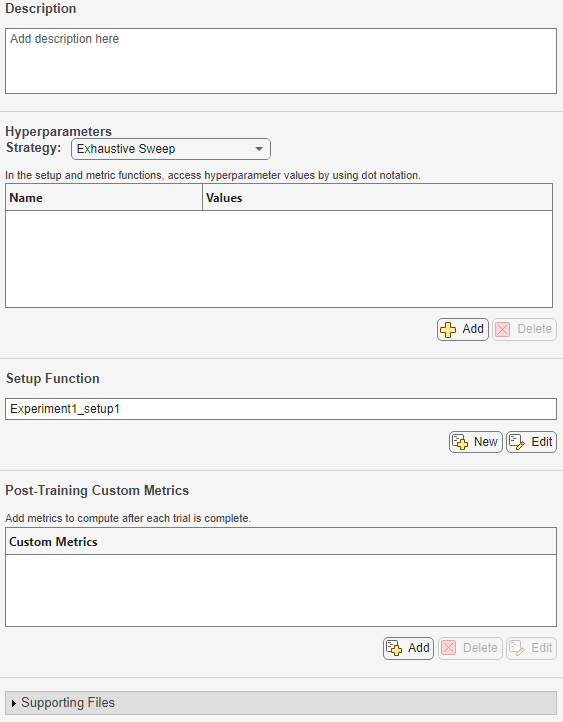
実験パラメーターを構成します。
説明 — 実験の説明を入力します。
ハイパーパラメーター — ハイパーパラメーター値のすべての組み合わせが使用されるように、[手法] を
[網羅的なスイープ]として指定します。次に、実験で使用するハイパーパラメーターを定義します。パラメーター探索の手法の選択と構成については、Choose Strategy for Exploring Experiment Parametersを参照してください。たとえば、Evaluate Deep Learning Experiments by Using Metric Functionsの場合、手法は
[網羅的なスイープ]で、ハイパーパラメーターはInitialLearnRateおよびMomentumです。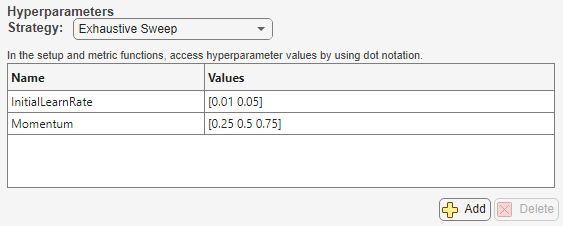
セットアップ関数 — セットアップ関数のシグネチャのいずれか 1 つを使用して、学習データ、ネットワーク アーキテクチャ、損失関数、および学習オプションを構成します。セットアップ関数の入力は、[ハイパーパラメーター] テーブルのフィールドをもつ構造体です。出力は、関数
trainnetの入力と一致しなければなりません。たとえば、Evaluate Deep Learning Experiments by Using Metric Functionsの場合、セットアップ関数は、ハイパーパラメーターの構造体にアクセスし、学習関数への入力を返します。このセットアップ関数は、
ClassificationExperiment_setup.mlxという名前のファイルで定義されています。
学習後のカスタム メトリクス — 各試行の後、結果テーブルに表示するメトリクスを計算します。カスタム メトリクス関数を作成するには、[学習後のカスタム メトリクス] セクションの [追加] ボタンをクリックします。次に、テーブルでメトリクスを選択して [編集] をクリックし、MATLAB エディターで関数を開いて編集します。実験に最適なハイパーパラメーターの組み合わせを決定するには、結果テーブルでこれらのメトリクスの値を検証します。
たとえば、Evaluate Deep Learning Experiments by Using Metric Functionsの場合、学習後のカスタム メトリクスは関数
OnesAsSevensおよびSevensAsOnesによって指定されます。この関数は、OnesAsSevens.mlxおよびSevensAsOnes.mlxという名前のファイルで定義されています。結果テーブルにこれらのメトリクスが表示されます。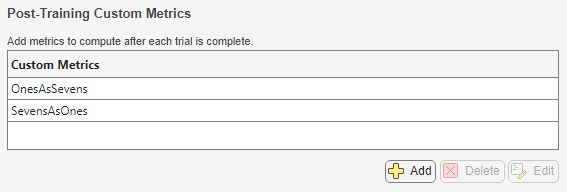
実験パラメーターの構成後に実験を実行して結果を比較する方法の詳細については、実験マネージャーを参照してください。
関数 trainnet およびベイズ最適化を使用して学習を行う実験をセットアップします。組み込み学習実験は、イメージ、シーケンス、時系列、特徴の分類や回帰などのワークフローをサポートします。
実験マネージャー アプリを開きます。ダイアログ ボックスで、新規プロジェクトを作成するか、ドキュメンテーションのサンプルを開きます。[新規] で [空のプロジェクト] を選択します。
次のダイアログ ボックスで、空の実験テンプレートを開くか、AI ワークフローをサポートするように事前構成されたいずれかの実験テンプレートを開きます。[空の実験] で、空のテンプレート [組み込み学習 (trainnet)] を選択します。
この実験は、![]() アイコンが示すように、学習関数
アイコンが示すように、学習関数 trainnet を使用する組み込み学習実験です。
実験定義タブに、実験を定義する説明、ハイパーパラメーター、セットアップ関数、学習後のカスタム メトリクス、およびサポート ファイルが表示されます。空の実験テンプレートで開始する場合、これらのパラメーターを手動で構成しなければなりません。パラメーターがある程度事前構成されたテンプレートを使用する場合は、代わりに、実験マネージャーのダイアログ ボックスから事前構成済みの組み込み学習テンプレートのいずれか 1 つを選択します。
実験パラメーターを構成します。
説明 — 実験の説明を入力します。
ハイパーパラメーター — [手法] を
[ベイズ最適化](Statistics and Machine Learning Toolbox) として指定します。下限と上限を示す 2 要素ベクトルとしてハイパーパラメーターを指定するか、ハイパーパラメーターが取り得る値をリストする string 配列または文字ベクトルの cell 配列としてハイパーパラメーターを指定します。この実験では、指定されたメトリクスが最適化され、実験に最適なハイパーパラメーターの組み合わせが自動的に決定されます。次に、ベイズ最適化の最大時間、最大試行回数、および詳細オプションを指定します。パラメーター探索の手法の選択と構成については、Choose Strategy for Exploring Experiment Parametersを参照してください。たとえば、Tune Experiment Hyperparameters by Using Bayesian Optimizationの場合、手法は
[ベイズ最適化]です。ハイパーパラメーター名は、SectionDepth、InitialLearnRate、Momentum、およびL2Regularizationです。最大試行回数は 30 です。
セットアップ関数 — セットアップ関数のシグネチャのいずれか 1 つを使用して、学習データ、ネットワーク アーキテクチャ、損失関数、および学習オプションを構成します。セットアップ関数の入力は、[ハイパーパラメーター] テーブルのフィールドをもつ構造体です。出力は、関数
trainnetの入力と一致しなければなりません。たとえば、Tune Experiment Hyperparameters by Using Bayesian Optimizationの場合、セットアップ関数は、ハイパーパラメーターの構造体にアクセスし、学習関数への入力を返します。このセットアップ関数は、
BayesOptExperiment_setup.mlxという名前のファイルで定義されています。
学習後のカスタム メトリクス — 最適化の方向を選択します。さらに、学習または検証の標準メトリクス (精度、RMSE、損失など) を選択するか、テーブルからカスタム メトリクスを選択します。メトリクス関数の出力は、数値、logical、または string スカラーでなければなりません。
たとえば、Tune Experiment Hyperparameters by Using Bayesian Optimizationの場合、学習後のカスタム メトリクスは関数
ErrorRateによって指定されます。この関数は、ErrorRate.mlxという名前のファイルで定義されています。この実験では、このメトリクスが最小化されます。
実験パラメーターの構成後に実験を実行して結果を比較する方法の詳細については、実験マネージャーを参照してください。
カスタム学習関数を使用して学習を行う実験をセットアップし、カスタムの可視化を作成します。
カスタムの学習実験は、trainnet 以外の学習関数を必要とするワークフローをサポートします。このワークフローには次が含まれます。
層グラフによって定義されていないネットワークの学習
カスタム学習率スケジュールを使用した、ネットワークの学習
カスタム関数を使用した、ネットワークの学習可能なパラメーターの更新
敵対的生成ネットワーク (GAN) の学習
ツイン ニューラル ネットワークの学習
実験マネージャー アプリを開きます。ダイアログ ボックスで、新規プロジェクトを作成するか、ドキュメンテーションのサンプルを開きます。[新規] で [空のプロジェクト] を選択します。
次のダイアログ ボックスで、空の実験テンプレートを開くか、AI ワークフローをサポートするように事前構成されたいずれかの実験テンプレートを開きます。[空の実験] で、空のテンプレート [カスタム学習] を選択します。
この実験は、![]() アイコンが示すように、カスタム学習関数を使用するカスタムの学習実験です。
アイコンが示すように、カスタム学習関数を使用するカスタムの学習実験です。
実験定義タブに、実験を定義する説明、ハイパーパラメーター、学習関数、およびサポート ファイルが表示されます。空の実験テンプレートで開始する場合、これらのパラメーターを手動で構成しなければなりません。パラメーターがある程度事前構成されたテンプレートを使用する場合は、代わりに、実験マネージャーのダイアログ ボックスから事前構成済みのカスタム学習テンプレートのいずれか 1 つを選択します。
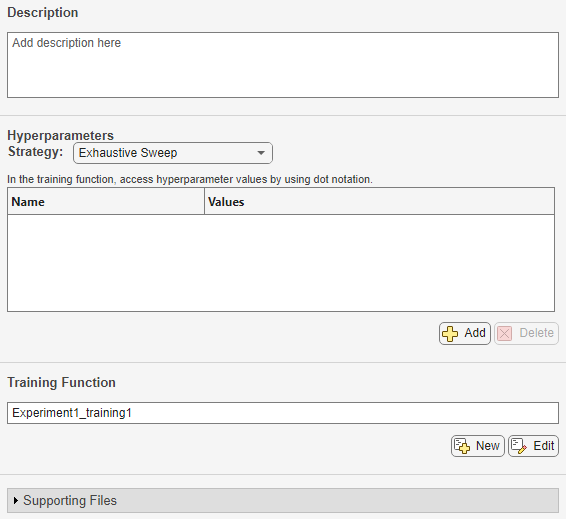
実験パラメーターを構成します。
説明 — 実験の説明を入力します。
ハイパーパラメーター — [手法] を
[網羅的スイープ]または[ベイズ最適化](Statistics and Machine Learning Toolbox) として指定し、実験で使用するハイパーパラメーターを定義します。網羅的なスイープでは、ハイパーパラメーター値のすべての組み合わせが使用されます。一方、ベイズ最適化では、指定されたメトリクスが最適化され、実験に最適なハイパーパラメーターの組み合わせが自動的に決定されます。パラメーター探索の手法の選択と構成については、Choose Strategy for Exploring Experiment Parametersを参照してください。たとえば、Run a Custom Training Experiment for Image Comparisonの場合、手法は
[網羅的なスイープ]で、ハイパーパラメーターはWeightsInitializerおよびBiasInitializerです。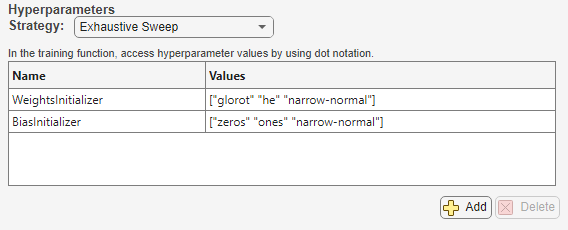
学習関数 — 学習データ、ネットワーク アーキテクチャ、学習手順、およびカスタムの可視化を構成します。実験マネージャーではこの関数の出力が保存されるため、学習完了時にこの出力を MATLAB ワークスペースにエクスポートできます。学習関数の入力は、[ハイパーパラメーター] テーブルのフィールドをもつ構造体、および
experiments.Monitorオブジェクトです。このオブジェクトを使用して、学習の進行状況を追跡し、結果テーブルの情報フィールドを更新し、学習で使用したメトリクスの値を記録し、プロットを生成します。たとえば、Run a Custom Training Experiment for Image Comparisonの場合、学習関数は、ハイパーパラメーターの構造体にアクセスし、学習済みネットワークが格納された構造体を返します。この学習関数は、ツイン ニューラル ネットワークに学習させるためのカスタム学習ループを実装します。この関数はプロジェクト内の
ImageComparisonExperiment_training.mlxという名前のファイルで定義されています。
また、この学習関数は、学習完了時に学習イメージのペアを表示する可視化
Test Imagesも作成します。
実験パラメーターの構成後に実験を実行して結果を比較する方法の詳細については、実験マネージャーを参照してください。
Parallel Computing Toolbox または MATLAB Parallel Server がある場合は、いくつかの実験の実行時間を短縮できる可能性があります。
既定では、実験マネージャーは一度に 1 つの試行を実行します。Parallel Computing Toolbox がある場合は、複数の GPU、1 つのクラスター、またはクラウドで、複数の試行を同時に実行したり、1 つの試行を実行したりすることができます。MATLAB Parallel Server を使用している場合は、リモート クラスターのバッチ ジョブとして実験をオフロードすることで、実験を実行しながら作業を続行することも MATLAB セッションを閉じることもできます。
実験マネージャーのツールストリップの [実行] セクションで、[モード] リストを使用して実行モードを指定します。実行モードとして [逐次バッチ] または [同時バッチ] を選択した場合、ツールストリップの [クラスター] リストと [プール サイズ] フィールドを使用してクラスターとプール サイズを指定します。
詳細については、Run Experiments in ParallelまたはOffload Experiments as Batch Jobs to a Clusterを参照してください。
関連する例
- 分類用の深層学習実験の作成
- 回帰用の深層学習実験の作成
- Evaluate Deep Learning Experiments by Using Metric Functions
- Tune Experiment Hyperparameters by Using Bayesian Optimization
- Use Bayesian Optimization in Custom Training Experiments
- Try Multiple Pretrained Networks for Transfer Learning
- Experiment with Weight Initializers for Transfer Learning
- Audio Transfer Learning Using Experiment Manager
- Choose Training Configurations for LSTM Using Bayesian Optimization
- Run a Custom Training Experiment for Image Comparison
- Use Experiment Manager to Train Generative Adversarial Networks (GANs)
- Custom Training with Multiple GPUs in Experiment Manager
詳細
ヒント
ネットワークの可視化と構築を行うには、ディープ ネットワーク デザイナー アプリを使用します。
実験のサイズを小さくするには、不要になった試行の結果と可視化を破棄します。結果テーブルの [アクション] 列で、試行の破棄ボタン
 をクリックします。
をクリックします。セットアップ関数では、ドット表記を使用してハイパーパラメーター値にアクセスします。詳細については、構造体配列を参照してください。
バッチ正規化層が含まれているネットワークで、
BatchNormalizationStatistics学習オプションがpopulationの場合、学習時に評価される検証メトリクスとは異なる最終検証メトリクス値が実験マネージャーに表示されることがよくあります。値の違いは、ネットワークの学習終了後に実行された追加の演算によるものです。詳細については、バッチ正規化層を参照してください。
バージョン履歴
R2020a で導入実験マネージャーのツールストリップの [キャンセル済みをすべて再開] ボタンが、[再開] リストに置き換えられました。実験の複数の試行を再開するには、[再開] リストを開き、再開条件を 1 つ以上選択し、[再開]
 をクリックします。再開条件として、
をクリックします。再開条件として、["キャンセル済み" をすべて]、["停止" をすべて]、["エラー" をすべて]、および["破棄" をすべて]を選択できます。組み込み学習実験では、学習が実行されている間、標準の学習メトリクスと検証メトリクスの途中の値が結果テーブルに表示されます。そのようなメトリクスとして、損失、精度 (分類実験の場合)、および平方根平均二乗誤差 (回帰実験の場合) があります。
組み込み学習実験では、組み込み学習実験における各試行が単一の CPU、単一の GPU、複数の CPU、複数の GPU のいずれで実行されたかが結果テーブルの [実行環境] 列に表示されます。
関連しなくなった試行の学習プロット、混同行列、および学習結果を破棄するには、結果テーブルの [アクション] 列で、破棄ボタン
をクリックします。
実験マネージャーのツールストリップの [並列の使用] ボタンが、[モード] リストに置き換えられました。
一度に 1 つの実験の試行を実行するには、
[逐次]を選択して [実行] をクリックします。複数の試行を同時に実行するには、
[同時]を選択して [実行] をクリックします。実験をバッチ ジョブとしてオフロードするには、
[逐次バッチ]または[同時バッチ]を選択し、クラスターとプール サイズを指定して、[実行] をクリックします。
新たに追加された [実験ブラウザー] コンテキスト メニュー オプションを使用し、次のように実験を管理します。
新しい実験をプロジェクトに追加するには、プロジェクトの名前を右クリックして [新規実験] を選択します。
実験のコピーを作成するには、実験の名前を右クリックして [複製] を選択します。
文字ベクトルの cell 配列としてハイパーパラメーターの値を指定します。以前のリリースの実験マネージャーでは、数値、logical 値、string 値のスカラーおよびベクトルを使用したハイパーパラメーターの指定のみがサポートされていました。
試行を停止、キャンセル、または再開するには、結果テーブルの [アクション] 列で停止ボタン
 、キャンセル ボタン
、キャンセル ボタン  、または再開ボタン
、または再開ボタン  をクリックします。以前のリリースでは、これらのボタンが [進行状況] 列にありました。あるいは、試行の行を右クリックし、コンテキスト メニューで [停止]、[キャンセル]、または [再開] を選択することもできます。
をクリックします。以前のリリースでは、これらのボタンが [進行状況] 列にありました。あるいは、試行の行を右クリックし、コンテキスト メニューで [停止]、[キャンセル]、または [再開] を選択することもできます。実験の試行が終了すると、結果テーブルの [ステータス] 列に、次のいずれかの停止理由が表示されます。
最大数のエポックが完了検証基準に適合OutputFcn によって停止学習損失が NaN
作成時間または試行番号で注釈を並べ替えるには、[注釈] パネルで [並べ替え] リストを使用します。
学習が完了したら、[エクスポート] 、 [結果テーブル] を選択し、結果テーブルの内容を MATLAB ワークスペースに
table配列として保存します。停止または完了した試行の学習情報または学習済みネットワークをエクスポートするには、試行の行を右クリックし、コンテキスト メニューで [学習情報のエクスポート] または [学習済みネットワークのエクスポート] を選択します。