trainnet
構文
説明
netTrained = trainnet(sequences,net,lossFcn,options)sequences で指定したシーケンスとターゲットを使用して、シーケンス タスクまたは時系列タスクのためのニューラル ネットワーク (LSTM や GRU ニューラル ネットワークなど) に学習させます。
netTrained = trainnet(features,net,lossFcn,options)features で指定した特徴データとターゲットを使用して、特徴タスクのためのニューラル ネットワーク (多層パーセプトロン (MLP) ニューラル ネットワークなど) に学習させます。
netTrained = trainnet(data,net,lossFcn,options)
[ は、前述の構文のいずれかを使用して学習情報も返します。netTrained,info] = trainnet(___)
例
イメージのデータ セットがある場合は、イメージ入力層を使用して深層ニューラル ネットワークに学習させることができます。
数字のサンプル データを解凍し、イメージ データストアを作成します。関数 imageDatastore は、フォルダー名に基づいてイメージに自動的にラベルを付けます。
unzip("DigitsData.zip") imds = imageDatastore("DigitsData", ... IncludeSubfolders=true, ... LabelSource="foldernames");
データを学習データ セットとテスト データ セットに分割し、学習セットの各カテゴリに 750 個のイメージが含まれ、テスト セットに各ラベルの残りのイメージが含まれるようにします。splitEachLabel は、イメージ データストアを学習用とテスト用の 2 つの新しいデータストアに分割します。
numTrainFiles = 750;
[imdsTrain,imdsTest] = splitEachLabel(imds,numTrainFiles,"randomized");畳み込みニューラル ネットワーク アーキテクチャを定義します。ネットワークの入力層にイメージのサイズを指定し、最終全結合層にクラスの数を指定します。イメージはそれぞれ 28 x 28 x 1 ピクセルです。
inputSize = [28 28 1];
classNames = categories(imds.Labels);
numClasses = numel(classNames);
layers = [
imageInputLayer(inputSize)
convolution2dLayer(5,20)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];学習オプションを指定します。
SGDM ソルバーを使用して学習させます。
学習を 4 エポック行います。
学習の進行状況をプロットで監視し、精度メトリクスを監視します。
詳細出力を無効にします。
options = trainingOptions("sgdm", ... MaxEpochs=4, ... Verbose=false, ... Plots="training-progress", ... Metrics="accuracy");
ニューラル ネットワークに学習させます。分類には、クロスエントロピー損失を使用します。
net = trainnet(imdsTrain,layers,"crossentropy",options);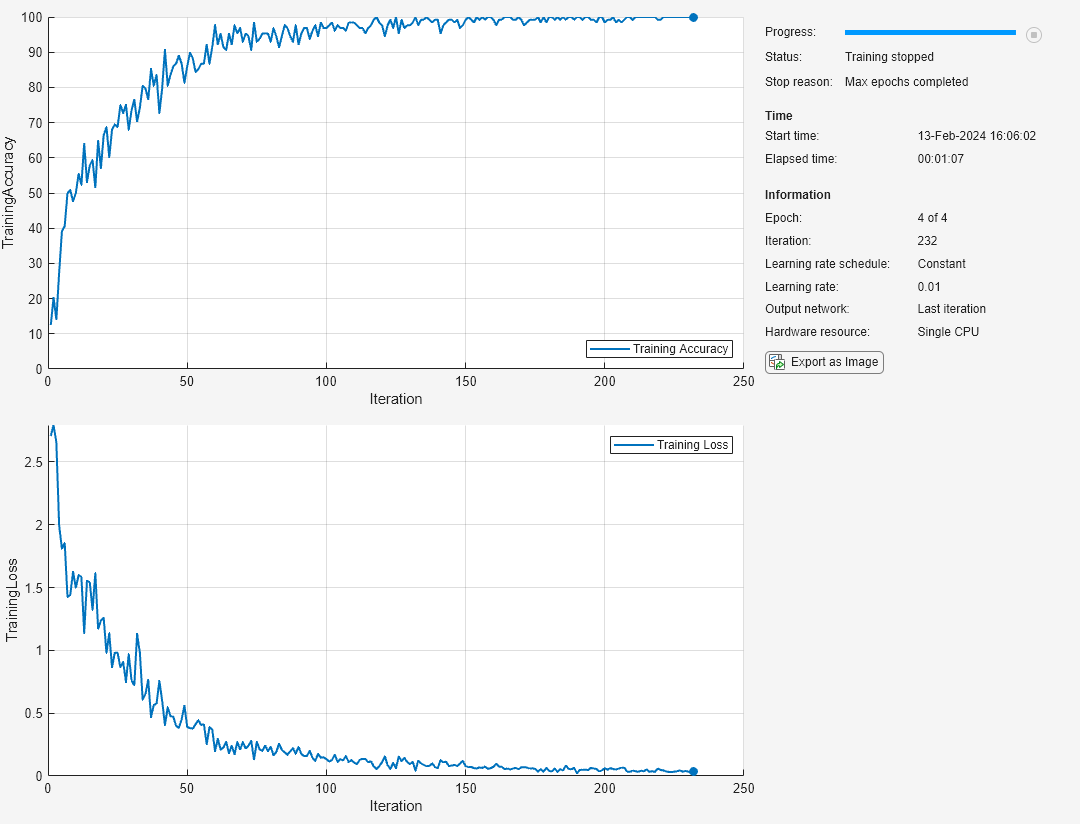
ラベル付きテスト セットを使用してネットワークをテストします。単一ラベルの分類では、精度を評価します。精度は、ネットワークが正しく予測するラベルの割合です。
accuracy = testnet(net,imdsTest,"accuracy")accuracy = 98.3200
学習済みのネットワークを使用して分類スコアを予測し、scores2label 関数を使用してラベルを予測に変換します。
scoresTest = minibatchpredict(net,imdsTest); YTest = scores2label(scoresTest,classNames);
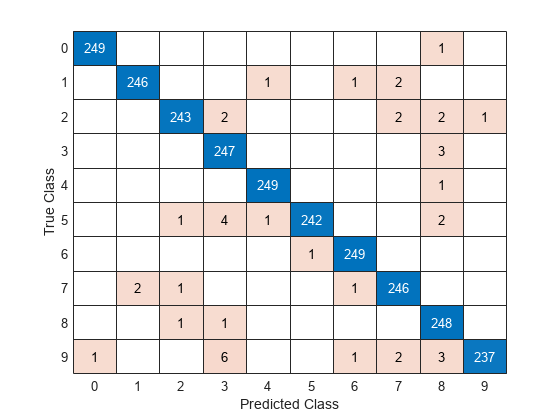
混同チャートで予測を可視化します。
confusionchart(imdsTest.Labels,YTest)
数値特徴量のデータ セット (空間次元や時間次元のない表形式データなど) がある場合、特徴入力層を使用して深層ニューラル ネットワークに学習させることができます。
CSV ファイル "transmissionCasingData.csv" からトランスミッション ケーシング データを読み取ります。
filename = "transmissionCasingData.csv"; tbl = readtable(filename,TextType="String");
関数 convertvars を使用して、予測のラベルを categorical に変換します。
labelName = "GearToothCondition"; tbl = convertvars(tbl,labelName,"categorical");
カテゴリカル特徴量を使用してネットワークに学習させるには、最初にカテゴリカル特徴量を数値に変換しなければなりません。まず、関数 convertvars を使用して、すべてのカテゴリカル入力変数の名前を格納した string 配列を指定することにより、カテゴリカル予測子を categorical に変換します。このデータ セットには、"SensorCondition" と "ShaftCondition" という名前の 2 つのカテゴリカル特徴量があります。
categoricalPredictorNames = ["SensorCondition" "ShaftCondition"]; tbl = convertvars(tbl,categoricalPredictorNames,"categorical");
カテゴリカル入力変数をループ処理します。各変数について、関数 onehotencode を使用して categorical 値を one-hot 符号化ベクトルに変換します。
for i = 1:numel(categoricalPredictorNames) name = categoricalPredictorNames(i); tbl.(name) = onehotencode(tbl.(name),2); end
table の最初の数行を表示します。カテゴリカル予測子が複数の列に分割されていることに注意してください。
head(tbl)
SigMean SigMedian SigRMS SigVar SigPeak SigPeak2Peak SigSkewness SigKurtosis SigCrestFactor SigMAD SigRangeCumSum SigCorrDimension SigApproxEntropy SigLyapExponent PeakFreq HighFreqPower EnvPower PeakSpecKurtosis SensorCondition ShaftCondition GearToothCondition
________ _________ ______ _______ _______ ____________ ___________ ___________ ______________ _______ ______________ ________________ ________________ _______________ ________ _____________ ________ ________________ _______________ ______________ __________________
-0.94876 -0.9722 1.3726 0.98387 0.81571 3.6314 -0.041525 2.2666 2.0514 0.8081 28562 1.1429 0.031581 79.931 0 6.75e-06 3.23e-07 162.13 0 1 1 0 No Tooth Fault
-0.97537 -0.98958 1.3937 0.99105 0.81571 3.6314 -0.023777 2.2598 2.0203 0.81017 29418 1.1362 0.037835 70.325 0 5.08e-08 9.16e-08 226.12 0 1 1 0 No Tooth Fault
1.0502 1.0267 1.4449 0.98491 2.8157 3.6314 -0.04162 2.2658 1.9487 0.80853 31710 1.1479 0.031565 125.19 0 6.74e-06 2.85e-07 162.13 0 1 0 1 No Tooth Fault
1.0227 1.0045 1.4288 0.99553 2.8157 3.6314 -0.016356 2.2483 1.9707 0.81324 30984 1.1472 0.032088 112.5 0 4.99e-06 2.4e-07 162.13 0 1 0 1 No Tooth Fault
1.0123 1.0024 1.4202 0.99233 2.8157 3.6314 -0.014701 2.2542 1.9826 0.81156 30661 1.1469 0.03287 108.86 0 3.62e-06 2.28e-07 230.39 0 1 0 1 No Tooth Fault
1.0275 1.0102 1.4338 1.0001 2.8157 3.6314 -0.02659 2.2439 1.9638 0.81589 31102 1.0985 0.033427 64.576 0 2.55e-06 1.65e-07 230.39 0 1 0 1 No Tooth Fault
1.0464 1.0275 1.4477 1.0011 2.8157 3.6314 -0.042849 2.2455 1.9449 0.81595 31665 1.1417 0.034159 98.838 0 1.73e-06 1.55e-07 230.39 0 1 0 1 No Tooth Fault
1.0459 1.0257 1.4402 0.98047 2.8157 3.6314 -0.035405 2.2757 1.955 0.80583 31554 1.1345 0.0353 44.223 0 1.11e-06 1.39e-07 230.39 0 1 0 1 No Tooth Fault
データ セットのクラス名を表示します。
classNames = categories(tbl{:,labelName})classNames = 2×1 cell
{'No Tooth Fault'}
{'Tooth Fault' }
テスト用のデータを確保します。データの 85% から成る学習セットとデータの残りの 15% から成るテスト セットにデータを分割します。データを分割するには、この例にサポート ファイルとして添付されている関数 trainingPartitions を使用します。このファイルにアクセスするには、例をライブ スクリプトとして開きます。
numObservations = size(tbl,1); [idxTrain,idxTest] = trainingPartitions(numObservations,[0.85 0.15]); tblTrain = tbl(idxTrain,:); tblTest = tbl(idxTest,:);
関数 trainnet がサポートする形式にデータを変換します。予測子とターゲットをそれぞれ数値配列と categorical 配列に変換します。特徴量を入力する場合、ネットワークは、観測値に対応する行と特徴量に対応する列をもつデータを必要とします。データのレイアウトがこれとは異なる場合、このレイアウトになるようにデータを前処理するか、データ形式を使用してレイアウト情報を指定します。詳細については、深層学習のデータ形式を参照してください。
predictorNames = ["SigMean" "SigMedian" "SigRMS" "SigVar" "SigPeak" "SigPeak2Peak" ... "SigSkewness" "SigKurtosis" "SigCrestFactor" "SigMAD" "SigRangeCumSum" ... "SigCorrDimension" "SigApproxEntropy" "SigLyapExponent" "PeakFreq" ... "HighFreqPower" "EnvPower" "PeakSpecKurtosis" "SensorCondition" "ShaftCondition"]; XTrain = table2array(tblTrain(:,predictorNames)); TTrain = tblTrain.(labelName); XTest = table2array(tblTest(:,predictorNames)); TTest = tblTest.(labelName);
特徴入力層を使用してネットワークを定義し、特徴の数を指定します。また、z スコア正規化を使用してデータを正規化するように入力層を構成します。
numFeatures = size(XTrain,2);
numClasses = numel(classNames);
layers = [
featureInputLayer(numFeatures,Normalization="zscore")
fullyConnectedLayer(16)
layerNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];学習オプションを指定します。
L-BFGS ソルバーを使用して学習させます。このソルバーは、ネットワークが小さくデータがメモリに収まるタスクに適しています。
CPU を使用して学習させます。ネットワークとデータが小さいため、CPU の方がより適しています。
学習の進行状況をプロットに表示します。
詳細出力を非表示にします。
options = trainingOptions("lbfgs", ... ExecutionEnvironment="cpu", ... Plots="training-progress", ... Verbose=false);
関数 trainnet を使用してネットワークに学習させます。分類には、クロスエントロピー損失を使用します。
net = trainnet(XTrain,TTrain,layers,"crossentropy",options);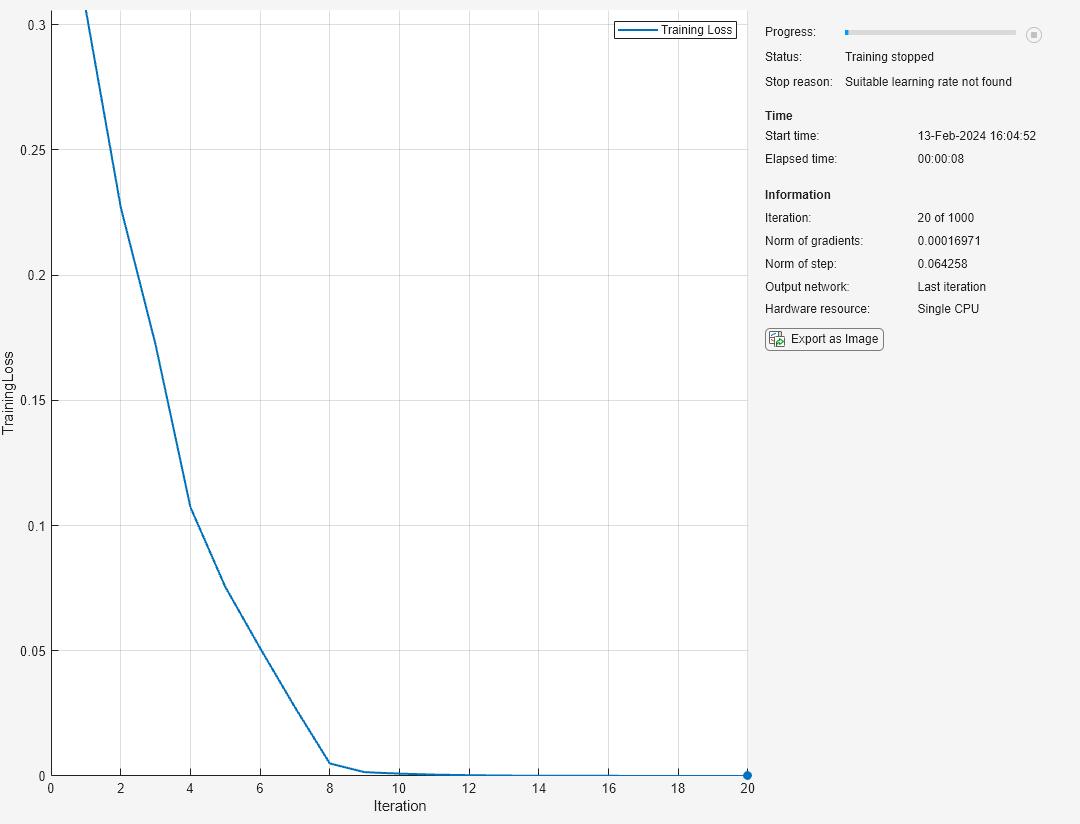
ラベル付きテスト セットを使用してネットワークをテストします。単一ラベルの分類では、精度を評価します。精度は、ネットワークが正しく予測するラベルの割合です。
accuracy = testnet(net,XTest,TTest,"accuracy")accuracy = 100
学習済みネットワークを使用してテスト データのラベルを予測します。学習済みネットワークを使用して分類スコアを予測し、scores2label 関数を使用して予測結果をラベルに変換します。
scoresTest = minibatchpredict(net,XTest); YTest = scores2label(scoresTest,classNames);
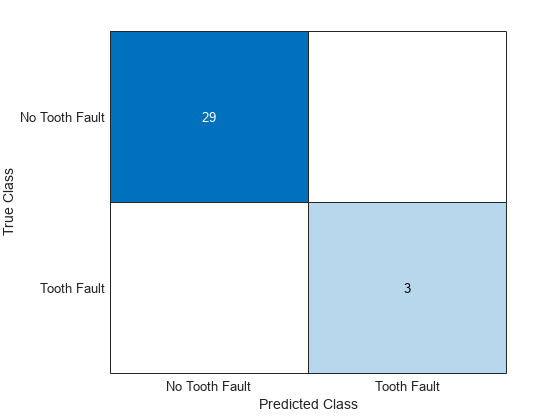
混同チャートで予測を可視化します。
confusionchart(TTest,YTest)
入力引数
出力引数
詳細
ヒント
回帰タスクにおいて、
trainingOptions関数のNormalizeTargets引数を使用してターゲットを正規化することは、多くの場合、学習の安定化と高速化に役立ちます。詳細については、回帰用の畳み込みニューラル ネットワークの学習を参照してください。ほとんどの場合、予測子またはターゲットに
NaN値が含まれていると、それらはネットワークを通じて伝播され、学習は収束に失敗します。数値配列をデータストアに変換するには、
ArrayDatastoreオブジェクトを使用します。データのタイプが混在するニューラル ネットワークで層を結合する場合、データを結合層 (連結層や追加層など) に渡す前に再構築しなければならない場合があります。データを再構築するには、フラット化層を使用して空間次元をチャネル次元にフラット化するか、データを再構築および形状変更する
FunctionLayerオブジェクトまたはカスタム層を作成します。