新しいイメージを分類するためのニューラル ネットワークの再学習
この例では、事前学習済みの SqueezeNet ニューラル ネットワークに再学習させて、新しいイメージ コレクションを分類する方法を説明します。
ニューラル ネットワークを新しいタスクに合うように適応させ、学習した重みを開始点として使用することで、新しいデータセットを事前学習済みのネットワークに再学習させることができます。ネットワークを新しいデータに適応させるには、最後のいくつかの層 (ネットワーク ヘッドと呼ばれる) を置き換えて、ニューラル ネットワークが新しいタスクの各クラスの予測スコアを出力するようにします。
ニューラル ネットワークに再学習させるための手法はいくつかあります。
ゼロから再学習 — 同じネットワーク アーキテクチャを使用して、ニューラル ネットワークにゼロから学習させます。
転移学習 — 事前学習済みのニューラル ネットワークの重みを固定し、ネットワーク ヘッドの再学習のみを行います。
微調整 — ニューラル ネットワークの重みの一部またはすべてについて再学習を行い、必要に応じて事前学習済みの重みの学習を遅くします。
通常、事前学習済みのニューラル ネットワークの転移学習や微調整を行う方が、ニューラル ネットワークにゼロから学習させるよりも必要なデータが少なくて済み、はるかに簡単で時間がかかりません。
次の図は、ニューラル ネットワークに再学習させる一般的なプロセスを示しています。

この例では、転移学習を使用して SqueezeNet ニューラル ネットワークに再学習させます。このネットワークは、100 万個を超えるイメージで学習しており、イメージを 1,000 個のオブジェクト カテゴリ (キーボード、マグ カップ、鉛筆、多くの動物など) に分類できます。このネットワークは広範囲にわたるイメージについての豊富な特徴表現を学習しています。このネットワークは、イメージを入力として受け取り、各クラスの予測スコアを出力します。
学習データの読み込み
MathWorks™ Merch データセットを抽出します。これは、5 つの異なるクラスに属する 75 個の MathWorks の商品イメージが格納された小さなデータセットです。データは、これら 5 つのクラスに対応するサブフォルダーにイメージが置かれる配置になっています。
folderName = "MerchData"; unzip("MerchData.zip",folderName);
イメージ データストアを作成します。イメージ データストアを使用すると、イメージ データの大規模なコレクション (メモリに収まらないデータなど) を格納し、ニューラル ネットワークの学習時にイメージをバッチ単位で効率的に読み取ることができます。抽出したイメージがあるフォルダーを指定し、サブフォルダー名がイメージ ラベルに対応していることを示します。
imds = imageDatastore(folderName, ... IncludeSubfolders=true, ... LabelSource="foldernames");
いくつかのサンプル イメージを表示します。
numImages = numel(imds.Labels); idx = randperm(numImages,16); I = imtile(imds,Frames=idx); figure imshow(I)

クラス名とクラス数を表示します。
classNames = categories(imds.Labels)
classNames = 5×1 cell
{'MathWorks Cap' }
{'MathWorks Cube' }
{'MathWorks Playing Cards'}
{'MathWorks Screwdriver' }
{'MathWorks Torch' }
numClasses = numel(classNames)
numClasses = 5
データを学習データセット、検証データセット、テスト データセットに分割します。イメージの 70% は学習に使用し、15% は検証に使用し、15% はテストに使用します。関数 splitEachLabel は、イメージ データストアを 3 つの新しいデータストアに分割します。
[imdsTrain,imdsValidation,imdsTest] = splitEachLabel(imds,0.7,0.15,"randomized");事前学習済みのネットワークの読み込み
事前学習済みのニューラル ネットワークを新しいタスクに適応させるには、最後のいくつかの層 (ネットワーク ヘッド) を置き換えて、新しいタスクの各クラスの予測スコアを出力するようにします。次の図は、 個のクラスの予測を行うニューラル ネットワークのアーキテクチャの概要を示し、 個のクラスの予測を出力するようにネットワークを編集する方法を示しています。
![Diagram showing how to replace layers for transfer learning. It shows image input data flowing through a series of layers labeled "backbone". The output of the backbone is labeled "extracted features. The extracted features are passed subsequent layers labeled "Head", which has an output vector [y1,,...,yK]. Separate from the network, there are layers labeled "New Head" which consist of a fully connected layer of size K* and a softmax layer. This has an output vector of [y1,...,yK*]. There is a double sided arrow that indicates to swap the part labeled "Head" with the part labeled "New Head".](../../examples/nnet/win64/RetrainNeuralNetworkToClassifyNewImagesExample_03.png)
imagePretrainedNetwork 関数を使用して、事前学習済みの SqueezeNet ニューラル ネットワークをワークスペースに読み込みます。新しいデータの再学習の準備ができているニューラル ネットワークを返すには、クラスの数を指定します。クラスの数を指定すると、imagePretrainedNetwork 関数は、指定された数のクラスごとに予測スコアを出力するようにニューラル ネットワークを適応させます。
他の事前学習済みネットワークを試すこともできます。Deep Learning Toolbox™ には、さまざまなサイズ、速度、精度をもつさまざまな事前学習済みネットワークが用意されています。これらの追加ネットワークには、通常、サポート パッケージが必要です。選択したネットワークのサポート パッケージがインストールされていない場合、関数によってダウンロード用リンクが表示されます。詳細については、事前学習済みの深層ニューラル ネットワークを参照してください。
net = imagePretrainedNetwork( "squeezenet",NumClasses=numClasses)
"squeezenet",NumClasses=numClasses)net =
dlnetwork with properties:
Layers: [68×1 nnet.cnn.layer.Layer]
Connections: [75×2 table]
Learnables: [52×3 table]
State: [0×3 table]
InputNames: {'data'}
OutputNames: {'prob_flatten'}
Initialized: 1
View summary with summary.
analyzeNetwork 関数を使用してネットワーク アーキテクチャを表示します。入力層、および学習可能なパラメーターをもつ最後の層に注意してください。
analyzeNetwork(net)
入力層はニューラル ネットワークの入力サイズを示します。
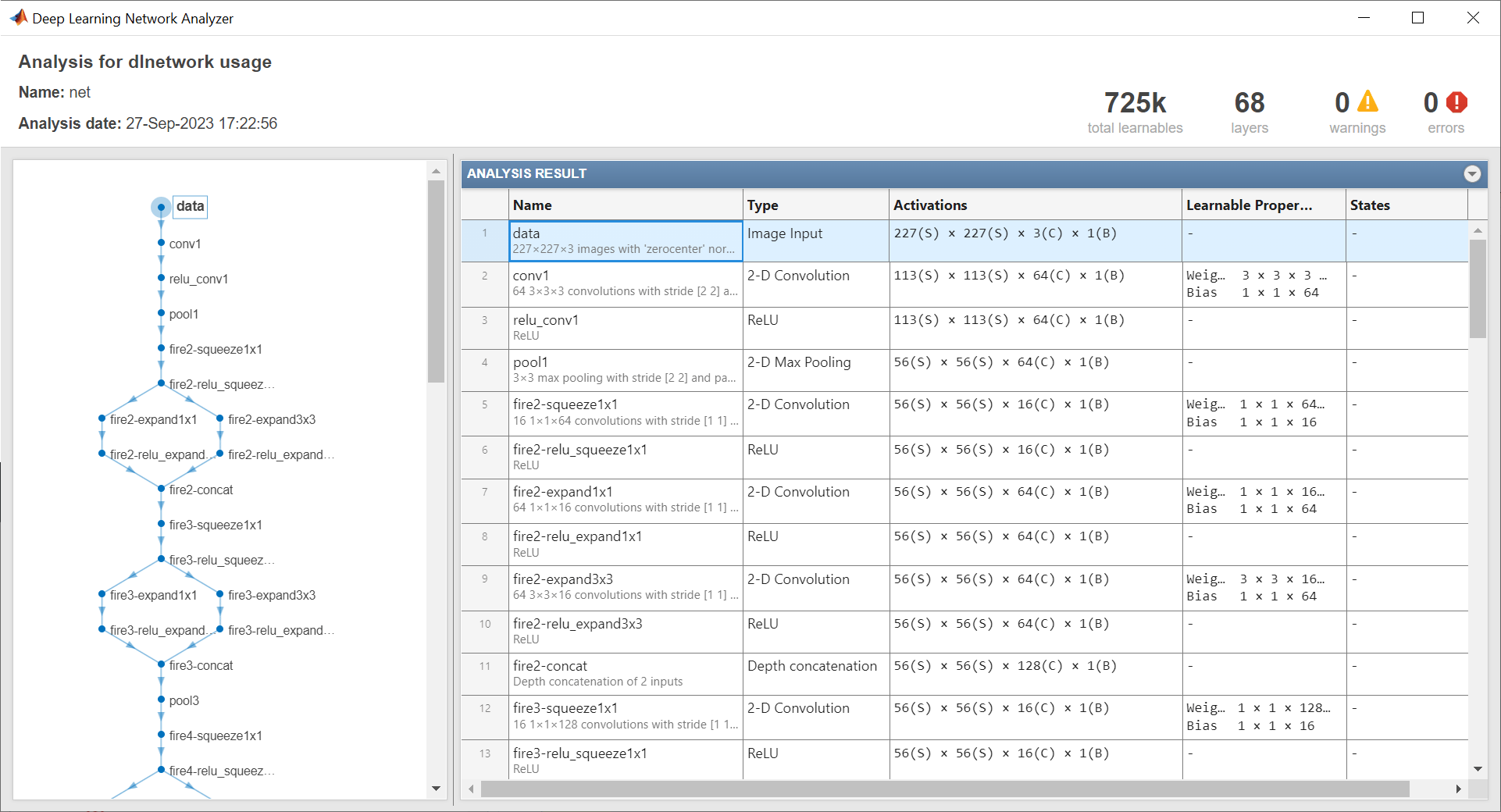
ニューラル ネットワークの入力サイズを入力層から取得します。この例にサポート ファイルとして添付されている networkInputSize 関数は、入力層から入力サイズを抽出します。この関数にアクセスするには、例をライブ スクリプトとして開きます。
inputSize = networkInputSize(net)
inputSize = 1×3
227 227 3
ネットワーク ヘッドの学習可能なパラメーターの層 (学習可能なパラメーターをもつ最後の層) は再学習が必要です。この層は通常、クラス数と一致する出力サイズをもつ全結合層または畳み込み層です。
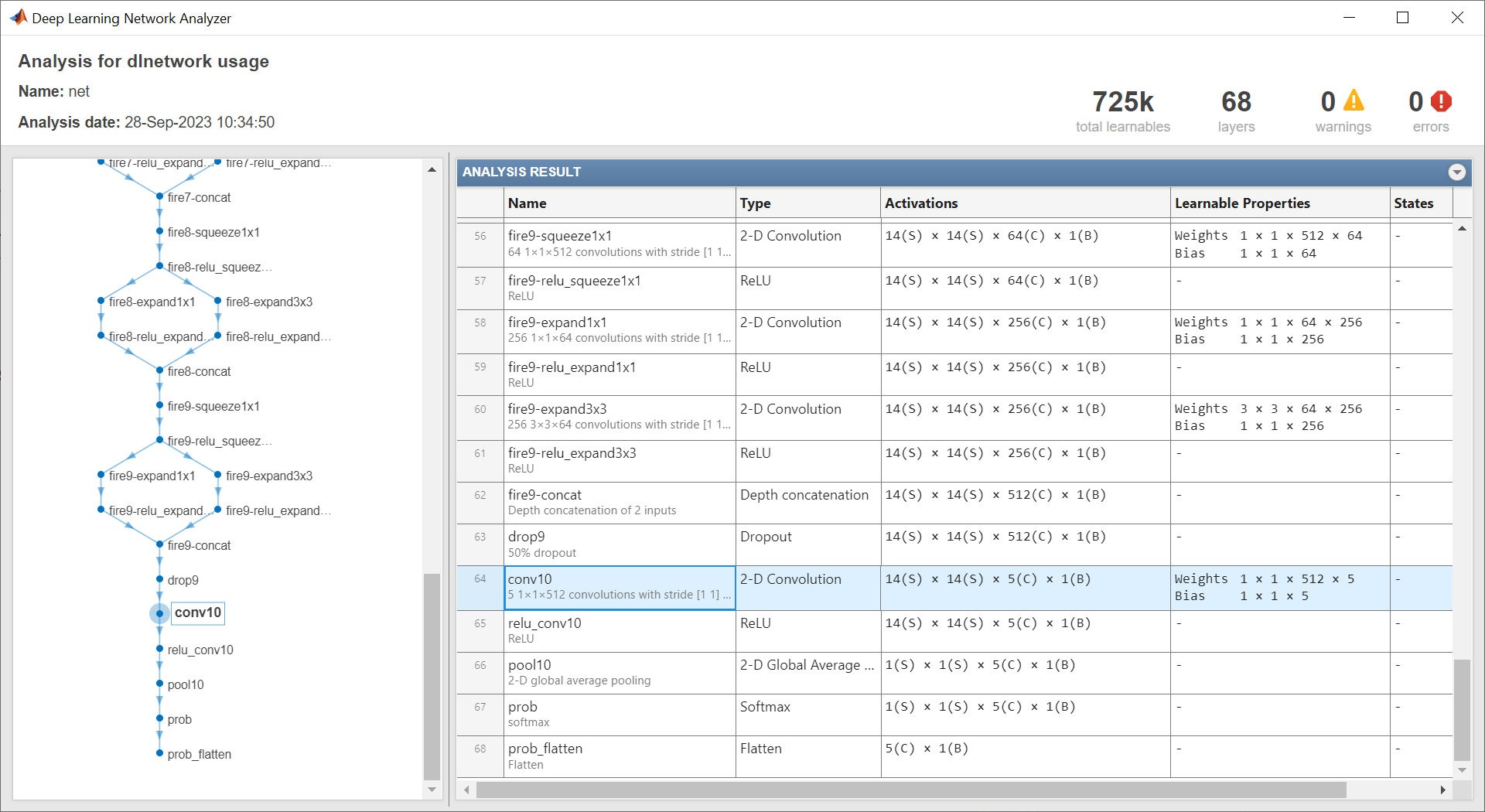
この例にサポート ファイルとして添付されている networkHead 関数は、ネットワーク ヘッド内の学習可能なパラメーターの層の層名と学習可能なパラメーター名を返します。この関数にアクセスするには、例をライブ スクリプトとして開きます。
[layerName,learnableNames] = networkHead(net)
layerName = "conv10"
learnableNames = 2×1 string
"conv10/Weights"
"conv10/Bias"
転移学習の場合、ネットワーク内で最初の方にある層の学習率を 0 に設定することで、それらの層の重みを凍結できます。学習中、trainnet 関数はこれらの凍結された層のパラメーターを更新しません。この関数は凍結された層の勾配を計算しないため、重みを凍結するとネットワークの学習が大幅に高速化されます。データセットが小さい場合、ネットワーク層を凍結すると、それらの層が新しいデータセットに過適合するのを防ぐことができます。
この例にサポート ファイルとして添付されている freezeNetwork 関数を使用して、最後の学習可能なパラメーターの層は凍結せずに、ネットワークの重みを凍結します。この関数にアクセスするには、例をライブ スクリプトとして開きます。
net = freezeNetwork(net,LayerNamesToIgnore=layerName);
ヒント: 最初の方にある層の重みを凍結する代わりに、これらの層の更新レベルを下げて、新しい分類ヘッドの更新レベルを上げることができます。これは微調整と呼ばれます。これを行うには、setLearnRateFactor 関数を使用して、新しい分類ヘッド内の学習可能なパラメーターの学習率係数を増やします。その後、trainingOptions の InitialLearnRate 引数を使用して、全体の学習率を下げます。
学習用データの準備
データストア内のイメージのサイズはさまざまです。学習イメージのサイズを自動的に変更するには、拡張イメージ データストアを使用します。データ拡張は、ネットワークで過適合が発生したり、学習イメージの正確な詳細が記憶されたりすることを防止するのにも役立ちます。学習イメージに対して実行するそのような追加の拡張演算として、学習イメージを縦軸に沿ってランダムに反転させる演算や、水平方向および垂直方向に最大 30 ピクセルだけランダムに平行移動させる演算を指定します。
pixelRange = [-30 30]; imageAugmenter = imageDataAugmenter( ... RandXReflection=true, ... RandXTranslation=pixelRange, ... RandYTranslation=pixelRange); augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain, ... DataAugmentation=imageAugmenter);
他のデータ拡張を実行せずに検証イメージとテスト イメージのサイズを自動的に変更するには、追加の前処理演算を指定せずに拡張イメージ データストアを使用します。
augimdsValidation = augmentedImageDatastore(inputSize(1:2),imdsValidation); augimdsTest = augmentedImageDatastore(inputSize(1:2),imdsTest);
学習オプションの指定
学習オプションを指定します。オプションの中から選択するには、経験的解析が必要です。実験を実行してさまざまな学習オプションの構成を調べるには、実験マネージャーアプリを使用できます。
この例では、次のオプションを使用します。
Adam オプティマイザーを使用して学習させます。
5 回の反復ごとに検証データを使用してネットワークを検証します。データセットが大きい場合、検証によって学習の速度が低下しないようにするには、この値を増やします。
学習の進行状況をプロットで表示し、精度メトリクスを監視します。
詳細出力を無効にします。
options = trainingOptions("adam", ... ValidationData=augimdsValidation, ... ValidationFrequency=5, ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=false);
ニューラル ネットワークの学習
関数trainnetを使用してニューラル ネットワークに学習させます。分類には、クロスエントロピー損失を使用します。既定では、関数 trainnet は利用可能な GPU がある場合にそれを使用します。GPU を使用するには、Parallel Computing Toolbox™ ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。そうでない場合、関数 trainnet は CPU を使用します。実行環境を指定するには、ExecutionEnvironment 学習オプションを使用します。
net = trainnet(augimdsTrain,net,"crossentropy",options);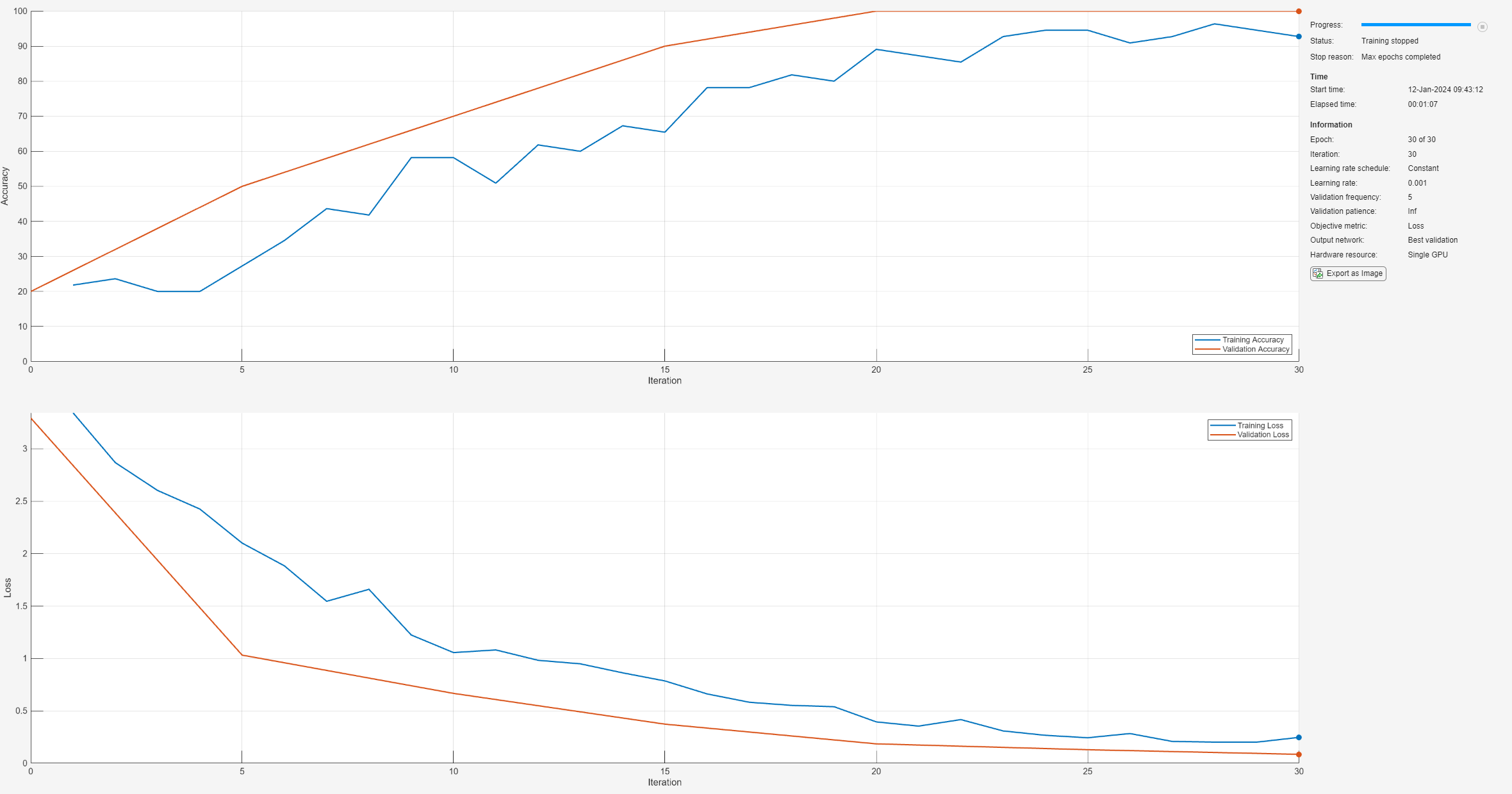
ニューラル ネットワークのテスト
テスト イメージを分類します。複数の観測値を使用して予測を行うには、関数 minibatchpredict を使用します。予測スコアをラベルに変換するには、関数 scores2label を使用します。関数 minibatchpredict は利用可能な GPU がある場合に自動的にそれを使用します。
YTest = minibatchpredict(net,augimdsTest); YTest = scores2label(YTest,classNames);
混同チャートで分類精度を可視化します。
TTest = imdsTest.Labels; figure confusionchart(TTest,YTest)
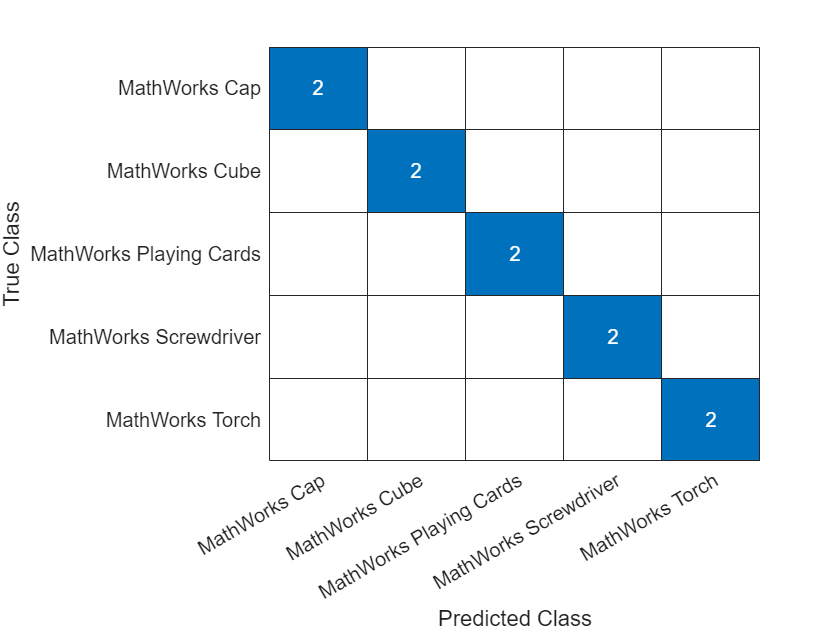
テスト データの分類精度を評価します。精度は、正しい予測の割合です。
acc = mean(TTest==YTest)
acc = 1
新しいデータでの予測の実行
JPEG ファイルからイメージを読み取り、サイズを変更し、single データ型に変換します。
im = imread("MerchDataTest.jpg");
im = imresize(im,inputSize(1:2));
X = single(im);イメージを分類します。単一の観測値を使用して予測を行うには、predict 関数を使用します。サポートされている GPU を計算に使用できる場合は、まずデータを gpuArray オブジェクトに変換します。
if canUseGPU X = gpuArray(X); end scores = predict(net,X); [label,score] = scores2label(scores,classNames);
予測されたラベルと対応するスコアを含むイメージを表示します。
figure imshow(im) title(string(label) + " (Score: " + gather(score) + ")")

参考
imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet