YOLO v4 入門
You Only Look Once version 4 (YOLO v4) オブジェクト検出ネットワークは one-stage オブジェクト検出ネットワークであり、バックボーン、ネック、およびヘッドの 3 つの部分で構成されています。
バックボーンには、COCO データ セットまたは ImageNet データ セットで学習させた VGG16 または CSPDarkNet53 などの事前学習済み畳み込みニューラル ネットワークを使用できます。YOLO v4 ネットワークのバックボーンは、入力イメージから特徴マップを計算する特徴抽出ネットワークとして機能します。
ネックはバックボーンとヘッドを接続します。これは、空間ピラミッドプーリング (SPP) モジュールとパス アグリゲーション ネットワーク (PAN) で構成されます。ネックは、バックボーン ネットワークのさまざまな層からの特徴マップを連結し、それらを入力としてヘッドに送信します。
ヘッドは、集約された特徴を処理して、境界ボックス、オブジェクトらしさのスコア、および分類スコアを予測します。YOLO v4 ネットワークは、YOLO v3 などの one-stage オブジェクト検出器を検出ヘッドとして使用します。
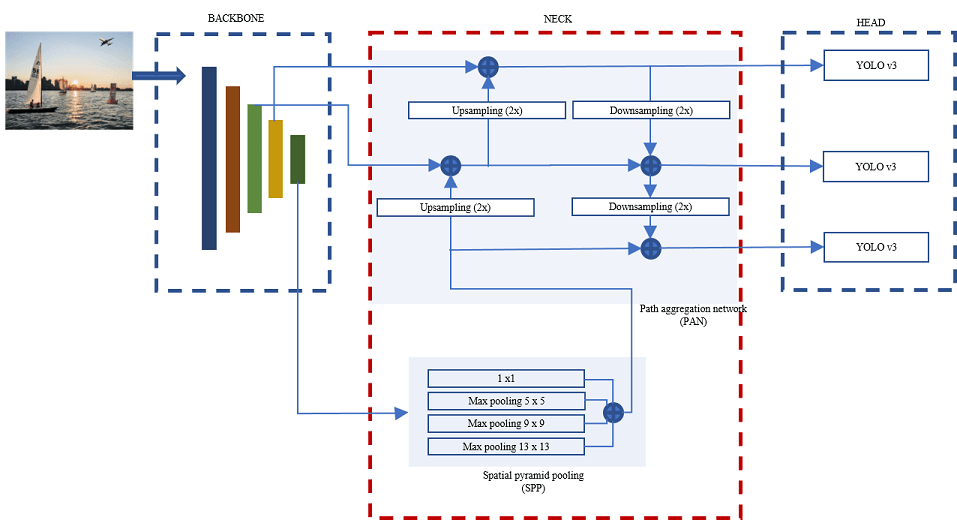
YOLO v4 ネットワークは、入力イメージから特徴を抽出するためのバックボーンとして CSPDarkNet-53 を使用します。バックボーンには 5 つの残差ブロック モジュールがあり、残差ブロック モジュールからの特徴マップ出力は YOLO v4 ネットワークのネックで融合されます。
ネックの SPP モジュールは、低解像度特徴マップの最大プーリング出力を連結して、最も代表的な特徴を抽出します。SPP モジュールは、最大プーリング操作に 1×1、5×5、9×9、および 13×13 のサイズのカーネルを使用します。ストライド値は 1 に設定されます。特徴マップを連結すると、バックボーン特徴の受容野が大きくなり、小さなオブジェクトを検出するネットワークの精度が向上します。SPP モジュールから連結された特徴マップは、PAN を使用して高解像度の特徴マップと融合されます。PAN は、低レベルの特徴と高レベルの特徴を組み合わせるために、アップサンプリング演算とダウンサンプリング演算を使用して、ボトムアップ パスとトップダウン パスを設定します。
PAN モジュールは、予測に使用する集約された特徴マップのセットを出力します。YOLO v4 ネットワークは 3 つの検出ヘッドをもちます。各検出ヘッドは、最終的な予測を計算する YOLO v3 ネットワークです。YOLO v4 ネットワークは、境界ボックス、分類スコア、オブジェクトらしさのスコアを予測するために、19×19、38×38、および 76×76 のサイズの特徴マップを出力します。
Tiny YOLO v4 ネットワークは、ネットワーク層を少なくした YOLO v4 ネットワークの軽量バージョンです。Tiny YOLO v4 ネットワークは、特徴ピラミッド ネットワークをネックとして使用し、2 つの YOLO v3 検出ヘッドをもちます。ネットワークは、予測を計算するために、13×13 および 26×26 のサイズの特徴マップを出力します。
YOLO v4 を使用したオブジェクトの予測
YOLO v4 はアンカー ボックスを使用して、イメージ内のオブジェクトのクラスを検出します。アンカー ボックスの詳細については、アンカー ボックスによるオブジェクトの検出を参照してください。YOLO v3 と同様に、YOLO v4 は各アンカー ボックスについて、次の 3 つの属性を予測します。
Intersection over Union (IoU) — 各アンカー ボックスのオブジェクトらしさのスコアを予測します。
アンカー ボックスのオフセット — アンカー ボックスの位置を調整します。
クラス確率 — 各アンカー ボックスに割り当てられるクラス ラベルを予測します。
次の図は、特徴マップ内の各位置の事前定義されたアンカー ボックス (破線で表示) と、オフセット適用後の調整された位置を示します。クラスと一致したアンカー ボックスは色付きで表示されます。

ネットワークに学習させる際に、事前定義されたアンカー ボックス (別名 "推測" ボックス) とクラスを指定しなければなりません。
YOLO v4 オブジェクト検出ネットワークの作成
YOLO v4 深層学習ネットワークをプログラムで作成するには、yolov4ObjectDetector オブジェクトを使用します。事前学習済みの YOLO v4 深層学習ネットワーク csp-darknet53-coco および tiny-yolov4-coco を使用して、yolov4ObjectDetector オブジェクトを作成し、イメージ内のオブジェクトを検出できます。これらのネットワークは COCO データ セットで学習させています。csp-darknet53-coco は 3 つの検出ヘッドをもつ YOLO v4 ネットワークであり、tiny-yolov4-coco は 2 つの検出ヘッドをもつ Tiny YOLO v4 ネットワークです。これらの YOLO v4 事前学習済みネットワークをダウンロードするには、Computer Vision Toolbox™ Model for YOLO v4 Object Detection サポート パッケージをインストールしなければなりません。
YOLO v4 ネットワークを使用したオブジェクトの学習と検出
ラベル付きデータセットで YOLO v4 オブジェクト検出ネットワークに学習させるには、関数 trainYOLOv4ObjectDetector を使用します。ネットワークに学習させるために使用するデータ セットのクラス名と事前定義されたアンカー ボックスを指定しなければなりません。
学習関数は、学習済みネットワークを yolov4ObjectDetector オブジェクトとして返します。その後、関数 detect を使用して、学習済みの YOLO v4 オブジェクト検出器でテスト イメージ内の未知のオブジェクトを検出できます。YOLO v4 オブジェクト検出器を作成し、オブジェクト検出用に学習させる方法については、YOLO v4 深層学習を使用したオブジェクトの検出の例を参照してください。
アンカー ボックスの指定
学習で使用するアンカー ボックスの形状、サイズ、数は、YOLO v4 オブジェクト検出ネットワークの効率と精度に影響を与えます。アンカー ボックスは、学習データ内のオブジェクトのサイズとアスペクト比を厳密に表すものでなければなりません。学習データは、グラウンド トゥルース イメージとラベルの両方を含まなければなりません。学習イメージのサイズはネットワーク入力サイズと同じでなければならず、境界ボックスのラベルは学習イメージのサイズに対応していなければなりません。
YOLO v4 ネットワーク内の各検出ヘッドには、同じ数のアンカー ボックスを割り当てなければなりません。各検出ヘッドに割り当てるアンカー ボックスのサイズは、検出ヘッドから出力される特徴マップのサイズに対応していなければなりません。大きなアンカー ボックスは低解像度の特徴マップを使用する検出ヘッドに割り当て、小さなアンカー ボックスは高解像度の特徴マップを使用する検出ヘッドに割り当てなければなりません。
たとえば、次の手順では、特徴マップ サイズがそれぞれ 19×19、38×38、および 76×76 の 3 つの検出ヘッドをもつ YOLO v4 ネットワークに学習させるためにアンカー ボックスを指定する方法を示します。
各検出ヘッド用に 4 つのアンカー ボックスを指定すると仮定します。したがって、ネットワークの学習に使用するアンカー ボックスの総数は 12 個でなければなりません。関数
estimateAnchorBoxesを使用すると、指定した学習データのアンカー ボックスを自動的に推定できます。numAnchors = 12; [anchors] = estimateAnchorBoxes(trainingData,numAnchors);
各アンカー ボックスの面積を計算し、降順に並べ替えます。
area = anchors(:,1).*anchors(:,2); [~,idx] = sort(area,"descend"); sortedAnchors = anchors(idx,:)YOLO v4 ネットワークには 3 つの検出ヘッドがあるため、それぞれ 4 つのアンカー ボックスから成るセットを 3 つ作成します。
anchorBoxes = {sortedAnchors(1:4,:) sortedAnchors(5:8,:) sortedAnchors(9:12,:)};関数
yolov4ObjectDetectorを使用して、YOLO v4 オブジェクト検出ネットワークを作成します。クラスと並べ替え済みのアンカー ボックスを指定します。関数は、アンカー ボックスの最初のセットを最初の検出ヘッドに割り当て、2 番目のセットを 2 番目の検出ヘッドに割り当てます (以降も同様)。最初の 4 つのアンカー ボックスは大きな領域を持っているため、最初の検出ヘッドに割り当てなければなりません。最初の検出ヘッドは、19×19 の低解像度の特徴マップを出力します。次の 4 つのアンカー ボックスは、38×38 のサイズの特徴マップを出力する 2 番目の検出ヘッドに割り当てなければなりません。最後の 4 つのアンカー ボックスは、76×76 の最高解像度の特徴マップを出力する 3 番目の検出ヘッドに割り当てます。detector = yolov4ObjectDetector("csp-darknet53-coco","car",anchorBoxes);
関数
trainYOLOv4ObjectDetectorを使用して検出器に学習させます。detector = trainYOLOv4ObjectDetector(trainingData,detector,trainingOptions);
転移学習
転移学習を実行するには、事前学習済みの畳み込みニューラル ネットワーク (CNN) を YOLO v4 深層学習ネットワークのベース ネットワークとして使用します。アンカー ボックスと新しいオブジェクト クラスを指定して、新しいデータ セットで学習させる YOLO v4 深層学習ネットワークを構成します。yolov4ObjectDetector オブジェクトを使用して、ResNet-50 などの事前学習済み CNN からカスタム YOLO v4 検出ネットワークを作成します。次に、関数 trainYOLOv4ObjectDetector を使用してネットワークに学習させます。
カスタム YOLO v4 オブジェクト検出器の作成方法については、Create Custom YOLO v4 Object Detectorを参照してください。
深層学習用学習データのラベル付け
イメージ ラベラー、ビデオ ラベラー、またはグラウンド トゥルース ラベラー (Automated Driving Toolbox) アプリを使用して、対話形式でピクセルにラベル付けし、ラベル データを学習用にエクスポートできます。オブジェクト検出用の軸方向に整列したまたは回転した四角形の関心領域 (ROI)、イメージ分類用のシーン ラベル、セマンティック セグメンテーション用のピクセルにラベルを付けるためにアプリを使用することもできます。いずれかのラベラーによってエクスポートされたグラウンド トゥルース オブジェクトから学習データを作成するには、関数 objectDetectorTrainingData または関数 pixelLabelTrainingData を使用します。詳細については、オブジェクト検出およびセマンティック セグメンテーション用の学習データを参照してください。
参照
[1] Bochkovskiy, Alexey, Chien-Yao Wang, and Hong-Yuan Mark Liao. “YOLOv4: Optimal Speed and Accuracy of Object Detection.” ArXiv:2004.10934 [Cs, Eess], April 22, 2020. https://arxiv.org/abs/2004.10934.
[2] Redmon, Joseph, Santosh Divvala, Ross Girshick, and Ali Farhadi. "You only look once: Unified, real-time object detection." In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 779–788. Las Vegas, NV: USA: IEEE, 2016. https://doi.org/10.1109/CVPR.2016.91.
[3] Simon, Martin, Stefan Milz, Karl Amende, and Horst-Michael Gross. "Complex-yolo: Real-time 3d object detection on point clouds." arXiv preprint arXiv:1803.06199 (2018).
参考
アプリ
- イメージ ラベラー | グラウンド トゥルース ラベラー (Automated Driving Toolbox) | ビデオ ラベラー | ディープ ネットワーク デザイナー (Deep Learning Toolbox)
オブジェクト
関数
トピック
- YOLO v4 深層学習を使用したオブジェクトの検出
- アンカー ボックスによるオブジェクトの検出
- オブジェクト検出器の選択
- 深層学習を使用したオブジェクト検出入門
- オブジェクト検出のための YOLOX 入門
- MATLAB による深層学習 (Deep Learning Toolbox)
- 事前学習済みの深層ニューラル ネットワーク (Deep Learning Toolbox)