深層学習用イメージ前処理とイメージ拡張の入門
"データの前処理" は、目的のデータの特徴を正規化または強調する一連の確定的な演算で構成されます。たとえば、固定された範囲にデータを正規化したり、ネットワーク入力層に必要なサイズにデータを再スケーリングできます。前処理は、学習、検証、および推論に使用されます。
深層学習のワークフローでは、前処理は 2 つのステージで発生することがあります。
通常、前処理は、ネットワークに渡されるデータを準備する前に完了する個別の手順として発生します。元のデータを読み込み、前処理演算を適用して、結果をディスクに保存します。この方法の利点は、前処理のオーバーヘッドが必要になるのは 1 回のみで、その後ネットワークの学習を試行する際には前処理されたイメージが開始点として既に用意されていることです。
データをデータストアに読み込むと、関数
transformおよび関数combineを使用して、学習中に前処理を適用することもできます。詳細については、深層学習用のデータストア (Deep Learning Toolbox)を参照してください。変換後のイメージはメモリに格納されません。この方法は、前処理演算に大量の計算が必要ではなく、ネットワークの学習速度に顕著な影響を与えない場合に、学習データの 2 つ目のコピーをディスクに書き込むことを回避するのに便利です。
"データ拡張" は、ネットワークの学習中に学習データに適用されるランダム化された演算で構成されます。拡張を行うと、学習データの実質的な量が増加し、ネットワークをデータの一般的な歪みに対して不変にするのに役立ちます。たとえば、学習データに人工的なノイズを追加してネットワークをノイズに対して不変にすることができます。
学習データを拡張するには、まずデータをデータストアに読み込みます。いくつかの組み込みデータストアは、特定の用途の場合に特定の限られた拡張をデータに適用します。関数 transform および関数 combine を使用して、データストア内のデータに対して独自の拡張演算を適用することもできます。学習中、データストアによって各エポックの学習データにランダムに摂動が与えられるため、エポックごとにわずかに異なるデータセットが使用されます。詳細については、イメージの深層学習向け前処理とボリュームの深層学習向け前処理を参照してください。
イメージの前処理と拡張
一般的なイメージ前処理演算には、ノイズ除去、エッジ保存平滑化、色空間変換、コントラスト強調、モルフォロジーなどがあります。
イメージ データを拡張し、イメージの取得時のばらつきをシミュレーションします。たとえば、最も一般的なタイプのイメージ拡張演算は、シーンに対するカメラの向きのばらつきをシミュレーションする、回転や平行移動などの幾何学的変換です。色のジッターは、シーンでのライティング条件と色のばらつきをシミュレーションします。人工的なノイズは、センサーの電気変動およびアナログからデジタルへの変換の誤差によって生じる歪みをシミュレーションします。ブレは、フォーカスの合っていないレンズまたはシーンに対するカメラの動きをシミュレーションします。
次の表に示す演算やツールボックスのその他の機能を使用して、イメージ データを処理および拡張できます。これらの変換を作成および適用する方法を説明する例については、深層学習ワークフローのためのイメージの拡張を参照してください。
| 前処理のタイプ | 説明 | 関数のサンプル | 出力のサンプル |
|---|---|---|---|
| イメージのサイズ変更 | 固定の倍率、または目標のサイズにイメージのサイズを変更する |
| |
| イメージのトリミング | 中心またはランダムな位置からイメージを目標のサイズにトリミングする |
| |
| イメージのワーピング | ランダムな反転、回転、スケール、せん断、および平行移動をイメージに適用する |
| |
| 色のジッター | カラー イメージのイメージ色相、彩度、明るさ、コントラストをランダムに調整する |
| |
| ノイズのシミュレーション | ランダムなガウス ノイズ、ポアソン ノイズ、ごま塩ノイズ、または乗法性ノイズを追加する |
| |
| ブレのシミュレーション | ガウス ノイズまたは指向性運動によるブレを追加する |
| |
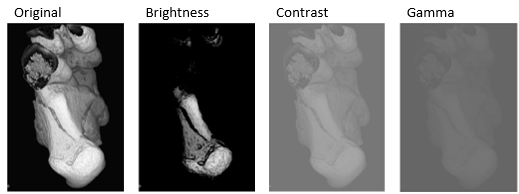
| ジッターの強度 | グレースケール イメージとボリュームの明度、コントラスト、またはガンマ補正をランダムに調整する |
|
|





セマンティック セグメンテーションのためのピクセル ラベル イメージの前処理と拡張
セマンティック セグメンテーション データは、イメージ、および categorical 配列として表される対応するピクセル ラベルで構成されます。詳細については、深層学習を使用したセマンティック セグメンテーション入門を参照してください。
イメージ ラベラー アプリおよびビデオ ラベラー アプリを使用して、対話形式でピクセルにラベル付けし、ラベル データをニューラル ネットワークの学習用にエクスポートできます。Automated Driving Toolbox™ がある場合、グラウンド トゥルース ラベラー (Automated Driving Toolbox) アプリを使用してラベル付きグラウンド トゥルース学習データを作成することもできます。
セマンティック セグメンテーション用にイメージを変換する場合、対応するピクセル ラベル付きイメージに対して同一の変換を実行しなければなりません。表に示す関数、およびカテゴリカル入力をサポートするその他の関数を使用して、ピクセル ラベル イメージを処理できます。これらの変換を作成および適用する方法を説明する例については、セマンティック セグメンテーションのためのピクセル ラベルの拡張を参照してください。
| 前処理のタイプ | 説明 | 関数のサンプル | 出力のサンプル |
|---|---|---|---|
| ピクセルのラベルのサイズ変更 | 固定の倍率、または目標のサイズにピクセル ラベル イメージのサイズを変更する |
| |
| ピクセル ラベルのトリミング | 中心またはランダムな位置からピクセル ラベル イメージを目標のサイズにトリミングする |
| |
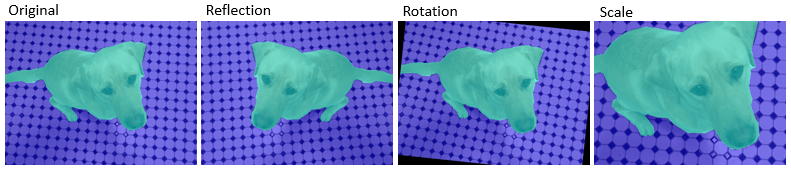
| ピクセル ラベルのワープ | ランダムな反転、回転、スケール、せん断、および平行移動をピクセル ラベル イメージに適用する |
|


オブジェクト検出のための境界ボックスの前処理と拡張
オブジェクト検出データは、イメージ、およびイメージ内のオブジェクトの位置と特性を示す境界ボックスで構成されます。詳細については、深層学習を使用したオブジェクト検出入門を参照してください。
イメージ ラベラー アプリとビデオ ラベラー アプリを使用して、ROI に対話形式でラベルを付け、ニューラル ネットワークに学習させるためのラベル データをエクスポートできます。Automated Driving Toolbox がある場合、グラウンド トゥルース ラベラー (Automated Driving Toolbox) アプリを使用してラベル付きグラウンド トゥルース学習データを作成することもできます。
イメージを変換する場合、対応する境界ボックスに対して同一の変換を実行しなければなりません。表に示す演算を使用して境界ボックスを処理できます。これらの変換を作成および適用する方法を説明する例については、オブジェクト検出のための境界ボックスの拡張を参照してください。
| 前処理のタイプ | 説明 | 関数のサンプル | 出力のサンプル |
|---|---|---|---|
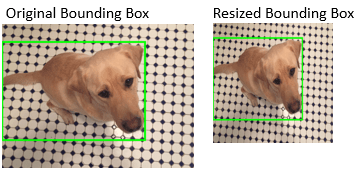
| 境界ボックスのサイズ変更 | 固定の倍率、または目標のサイズに境界ボックスのサイズを変更する |
| |
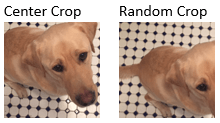
| 境界ボックスのトリミング | 中心またはランダムな位置から境界ボックスを目標のサイズにトリミングする |
| |
| 境界ボックスのワーピング | 反転、回転、スケール、せん断、および平行移動を境界ボックスに適用する |
|