深層学習用のデータストア
深層学習データ セットに対するアクセスや変更を行うには、データストア オブジェクトを使用できます。既にデータストアについて熟知しており、アプリケーションに適したデータストアを選択したい場合は、データストアの選択を参照してください。データストアを使用する深層学習タスクを高速化する方法の詳細については、Optimize Datastores for Deep Learning Performanceを参照してください。
データストアとは
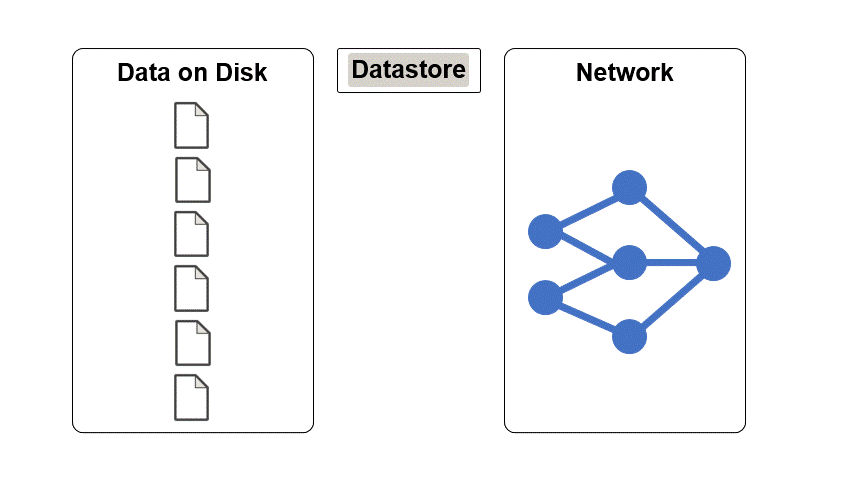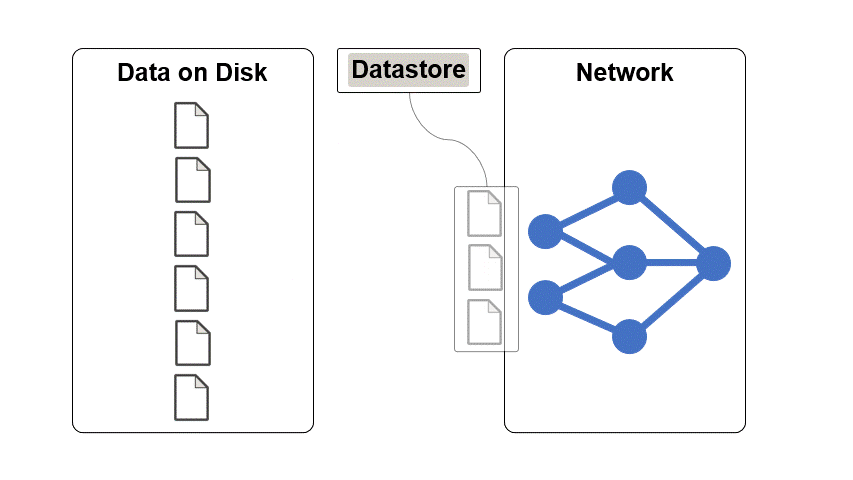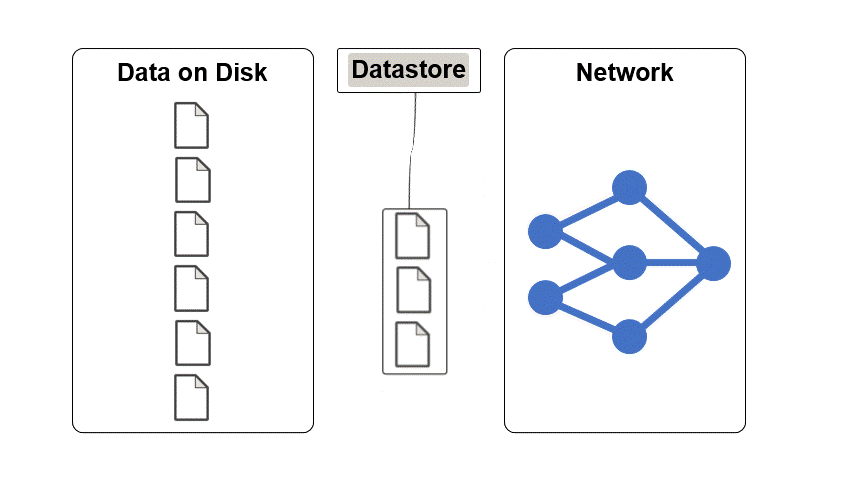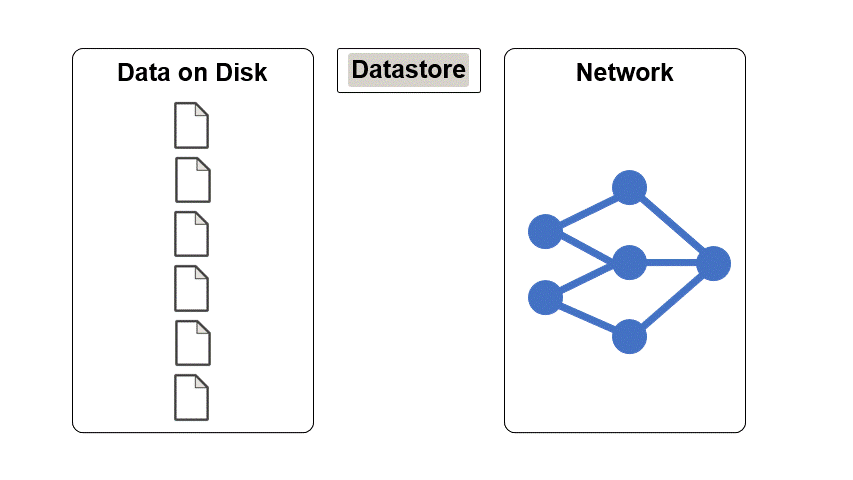
データストアは、単一のファイルまたはファイルやデータの集合を読み取るためのオブジェクトです。データストアのプロパティは、データを記述し、データストアからデータを読み取る方法を指定します。
データストアを使用して深層学習データ セットを操作する利点は、次のとおりです。
メモリ使用量の削減 — データストアを作成しても、データはメモリに読み込まれません。ソフトウェアは必要なときにのみデータをメモリに読み込むため、メモリ不足に陥ることなく、より大きなデータ セットを使用できます。
便利なバッチ処理 — データストアを使用すると、データをミニバッチで簡単に反復処理できます。
記述するコード量の削減 — データ セットの読み込み、変換、分割、および結合を行うコードを記述する代わりに、組み込みのデータストアの便利な関数を使用できます。
非常に小さなデータ セットで作業する場合は、データを MATLAB® に直接読み込むのが適切かもしれませんが、大規模なデータ セットや、複数の入力または出力をもつネットワークなどのより複雑なネットワークの場合は、データストアを使用します。
データストアの作成と読み取りの方法
深層学習に使用するデータを選択します。次のコードは、50 種類のアルファベットの手書き文字を示すイメージを含む Omniglot 学習データ セット[1]をダウンロードします。
downloadFolder = tempdir; url = "https://github.com/brendenlake/omniglot/raw/master/python/images_background.zip"; filename = fullfile(downloadFolder,"images.zip"); dataFolder = fullfile(downloadFolder,"images_background"); if ~exist(dataFolder,"dir") fprintf("Downloading Omniglot training data set (4.5 MB)... ") websave(filename,url) unzip(filename,downloadFolder) fprintf("Done.\n") end
dataFolder 内のすべてのファイルとサブフォルダーを含む imageDatastore オブジェクトを作成します。別の種類のデータがある場合は、別の組み込みデータストアを選択してください。詳細については、データストアの選択を参照してください。
imds = imageDatastore(dataFolder,IncludeSubfolders=true);
データストアがイメージにアクセスできることを確認するには、read 関数を使用してデータストアからイメージを読み取り、表示します。
I = read(imds); imshow(I)
read の後続の呼び出しでは、直前の呼び出しのエンドポイントから引き続き読み取ります。データが読み取られていない状態にデータストアをリセットするには、reset 関数を使用します。
reset(imds)
学習、検証、推論のためのデータストアの使用
データストアは、学習、検証、推論のための有効な入力です。
学習と検証
trainnet 関数を使用して学習させる場合、データストアを学習データのソースとして使用できます。検証にデータストアを使用するには、trainingOptions 関数を使用して ValidationData
データストアが学習または検証のための有効な入力となるためには、データストアの read 関数が cell 配列または table のいずれかとしてデータを返さなければなりません (数値配列を出力できる ImageDatastore オブジェクトと、table を出力する必要があるカスタム ミニバッチ データストアは例外)。
単一の入力があるネットワークの場合、データストアによって返される table または cell 配列に 2 つの列がなければなりません。最初の列のデータはネットワークへの入力 (予測子) を表し、2 番目の列のデータは学習ターゲットを表します。データの各列は個別の観測を表します。ImageDatastore の場合のみ、trainnet および trainingOptions は整数配列および整数配列の 1 列の cell 配列として返されるデータをサポートします。
data = read(ds)
data =
4×2 cell array
{224×224×3 double} {[2]}
{224×224×3 double} {[7]}
{224×224×3 double} {[9]}
{224×224×3 double} {[9]}ほとんどの組み込みのデータストアは、ネットワークで必要とされるレイアウトでデータを出力します。trainnet 関数を使用してネットワークに学習させる際、データのレイアウトがネットワークで必要とされるレイアウトと異なる場合、trainingOptions 関数の InputDataFormats および TargetDataFormats 引数を使用して、データのレイアウトが異なることを示します。通常、これらのオプションを調整することは、入力データとターゲット データを前処理するよりも簡単です。
たとえば、行と列がそれぞれチャネルとタイム ステップに対応するシーケンス データがある場合、入力データ形式を "CTB" (チャネル、時間、バッチ) として指定します。
trainingOptions("adam", ... InputDataFormats="CTB");
trainnet 関数に必要なデータ レイアウトの詳細については、データストアのカスタマイズを参照してください。
予測
minibatchpredict 関数を使用した推論の場合、データストアの read 関数が予測子に対応する列を返す限り、データストアは有効です。minibatchpredict 関数は最初の numInputs 個の列を使用し、後続の列を無視します。ここで、numInputs はネットワーク入力層の数です。
データストアの変換
変換されたデータストアは、データを読み取るときに、特定のデータ変換を基となるデータストアに適用します。変換されたデータストアを作成するには、transform 関数を使用して、基となるデータストアおよび変換処理について指定します。
1 行のコードで表現できる単純な変換の場合、無名関数のハンドルを transform の @fcn 引数として指定できます。詳細については、無名関数を参照してください。たとえば、transform 関数を使用して、変換されたデータストアを作成できます。このデータストアは、データストアからイメージを読み取るときに imresize 関数を適用してイメージのサイズを変更します。
imageSize = [244 244]; tds = transform(imds,@(I) imresize(I,imageSize))
複数の前処理演算を伴うより複雑な変換の場合、独自の関数に変換の完全なセットを定義します。次に、関数のハンドルを transform の引数 @fcn として指定します。transform 関数を使用してカスタム前処理関数を適用する方法を示す例については、image-to-image 回帰用のデータストアの準備を参照してください。
transform に指定された関数ハンドルは、基になるデータストアの関数 read によって返される形式と同じ形式の入力データを受け入れなければなりません。
データストアの統合
combine 関数は、複数のデータストアを相互に関連付けます。結合されたデータストアの関数 read を呼び出すと、基になる N 個の基になるデータストアすべてからデータのバッチ 1 つが読み取られます。返される観測値の数は同じでなければなりません。結合されたデータストアから読み取りを行うと、学習と検証に適した N 列の cell 配列で、結果が水平方向に連結されて返されます。
たとえば、image-to-image 回帰ネットワークに学習させる場合、2 つのイメージ データストアを組み合わせることによって学習データ セットを作成できます。次のサンプル コードは、imdsX および imdsY という名前の 2 つのイメージ データストアの組み合わせを示します。組み合わせが行われたデータストア imdsTrain はデータを 2 列の cell 配列として返します。
imdsTrain = combine(imdsX,imdsY); images = read(imdsTrain)
images =
1×2 cell array
{105×105 logical} {105×105 logical}combine 関数を使用してデータストアを結合する方法の例については、メモリ外のシーケンス データを使用したネットワークの学習を参照してください。
データストアを使用した複数の入出力をもつネットワークの学習
複数の入力層または複数の出力をもつネットワークに学習させるには、combine 関数と transform 関数を使用して、(numInputs + numOutputs) 列の cell 配列を出力するデータストアを作成します。ここで、numInputs はネットワーク入力の数、numOutputs はネットワーク出力の数です。最初の numInputs 個の列は各入力の予測子を指定し、最後の numOutputs 個の列は応答を指定します。ニューラル ネットワークの InputNames プロパティと OutputNames プロパティによって、それぞれ入力と出力の順序が決まります。
以下の表に、データストア ds に対して read 関数を呼び出した場合の出力の例を示します。
| ニューラル ネットワーク アーキテクチャ | データストア出力 | cell 配列出力の例 | table 出力の例 |
|---|---|---|---|
| 1 つの入力層と 1 つの出力 | 2 列の table または cell 配列。 最初の列と 2 番目の列は、それぞれ予測子とターゲットを指定します。 table の要素は、スカラー、行ベクトルであるか、数値配列が格納された 1 行 1 列の cell 配列でなければなりません。 カスタム ミニバッチ データストアは、table を出力しなければなりません。 | 1 つの入力と 1 つの出力があるニューラル ネットワークの cell 配列: data = read(ds) data =
4×2 cell array
{224×224×3 double} {[2]}
{224×224×3 double} {[7]}
{224×224×3 double} {[9]}
{224×224×3 double} {[9]} | 1 つの入力と 1 つの出力があるニューラル ネットワークの table: data = read(ds) data =
4×2 table
Predictors Response
__________________ ________
{224×224×3 double} 2
{224×224×3 double} 7
{224×224×3 double} 9
{224×224×3 double} 9
|
| 複数の入力層と複数の出力 | ( 最初の 入力と出力の順序は、ニューラル ネットワークの | 2 つの入力と 2 つの出力があるニューラル ネットワークの cell 配列。 data = read(ds) data =
4×4 cell array
{224×224×3 double} {128×128×3 double} {[2]} {[-42]}
{224×224×3 double} {128×128×3 double} {[2]} {[-15]}
{224×224×3 double} {128×128×3 double} {[9]} {[-24]}
{224×224×3 double} {128×128×3 double} {[9]} {[-44]} | サポートなし |
結合されたデータストアを使用して複数の入力をもつネットワークに学習させる方法を示す例については、イメージ データおよび特徴データにおけるネットワークの学習を参照してください。複数の入力と出力をもつネットワークの詳細については、多入力および多出力ネットワークを参照してください。
データストアの選択
多くの用途では、組み込みデータストアで開始するのが最も簡単な方法です。使用可能な組み込みデータストアの詳細は、ファイル形式またはアプリケーション用のデータストアの選択を参照してください。ただし、ネットワークの学習、検証、および推論の直接入力として使用できるのは、一部の種類の組み込みデータストアのみです。
| データストア | 説明 | 例 |
|---|---|---|
ImageDatastore | イメージ データ用のデータストア | |
augmentedImageDatastore | 学習イメージのサイズ変更および拡張を行うためのデータストア データストアは非確定的 | |
PixelLabelDatastore (Computer Vision Toolbox) | ピクセル ラベル データのデータストア |
|
boxLabelDatastore (Computer Vision Toolbox) | 境界ボックス ラベル データ用のデータストア |
|
randomPatchExtractionDatastore (Image Processing Toolbox) | イメージベースのデータからランダム パッチを抽出するためのデータストア データストアは非確定的 |
|
blockedImageDatastore (Image Processing Toolbox) | メモリに収まらない大きなイメージを含む、イメージ データのブロック単位の読み取りと処理のためのデータストア |
|
blockedPointCloudDatastore (Lidar Toolbox) | メモリに収まらない大きな点群を含む、点群データのブロック単位の読み取りと処理のためのデータストア | |
denoisingImageDatastore (Image Processing Toolbox) | イメージ ノイズ除去の深層ニューラル ネットワークに学習させるためのデータストア データストアは非確定的 |
|
audioDatastore (Audio Toolbox) | オーディオ データ用のデータストア | |
signalDatastore (Signal Processing Toolbox) | 信号データ用のデータストア |
|
他の組み込みデータストアを深層学習の入力として使用することもできますが、それらのデータストアから読み取ったデータを深層学習ネットワークに必要な形式に前処理しなければなりません。組み込みのデータストアと transform 関数および combine 関数を使用すると、深層学習の学習と予測タスクの大部分にデータストアを使用できます。読み取りデータに必要な形式の詳細については、データストアのカスタマイズを参照してください。また、データストアから読み取ったデータを前処理する方法の詳細については、データストアの変換およびデータストアの統合を参照してください。
用途によっては、データに当てはまる組み込みデータストア タイプが存在しないことがあります。このような場合は、カスタム データストアを作成できます。詳細については、カスタム データストアの開発を参照してください。カスタム データストアの関数 read が必要な形式でデータを返す限り、すべてのカスタム データストアが深層学習インターフェイスに対する入力として有効です。
量子化では多くの組み込みデータストアをサポートしています。詳細については、Prepare Data for Quantizing Networksを参照してください。
参照
[1] Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum. “Human-Level Concept Learning through Probabilistic Program Induction.” Science 350, no. 6266 (December 11, 2015): 1332–38. https://doi.org/10.1126/science.aab3050.
参考
transform | combine | read | trainnet | trainingOptions | dlnetwork