深層学習を使用した複数ラベル イメージ分類
この例では、複数ラベル イメージ分類用に、転移学習を使用して深層学習モデルに学習させる方法を説明します。
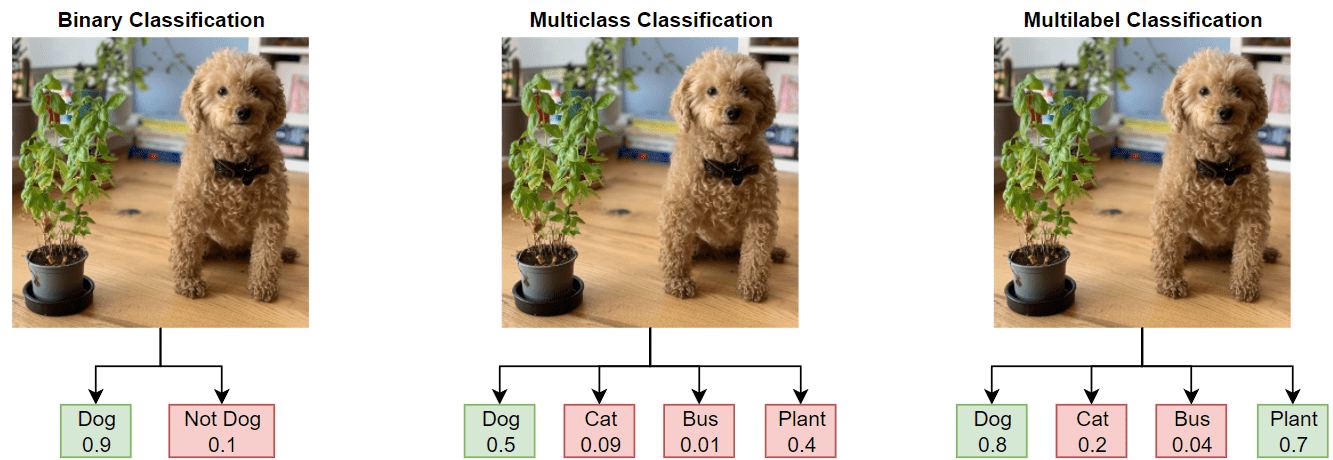
バイナリ分類または複数クラス分類の場合、深層学習モデルは、イメージが 2 つ以上のクラスのいずれか 1 つに属するものとして分類を行います。ネットワークの学習で使用されるデータは、多くの場合、明瞭かつ焦点が合っているイメージで構成されており、フレーム内には 1 つの被写体のみが含まれ、バックグラウンド ノイズやクラッターが存在しません。そのようなデータは、展開されたときにネットワークが受け取るデータのタイプを正確に表していないことがよくあります。また、バイナリ分類や複数クラス分類では、各イメージに 1 つのラベルしか適用できないため、不正確なラベル付けや誤解を招くラベル付けが発生します。
この例では、複数ラベル イメージ分類用に、自然環境のオブジェクトを含む現実的なデータ セットである COCO データ セットを使用して深層学習モデルに学習させます。COCO のイメージは複数のラベルをもつため、犬と猫を表すイメージは 2 つのラベルをもちます。
複数ラベル分類では、バイナリ分類や複数クラス分類とは対照的に、深層学習モデルによって各クラスの確率が予測されます。このモデルは、"猫" と "猫以外"、"犬" と "犬以外" といったように、クラスごとに複数の独立したバイナリ分類器をもちます。
事前学習済みのネットワークの読み込み
事前学習済みの ResNet-50 ネットワークを読み込みます。Deep Learning Toolbox Model for ResNet-50 Network サポート パッケージがインストールされていない場合、ダウンロード用リンクが表示されます。ResNet-50 は、100 万個を超えるイメージについて学習済みであり、イメージを 1,000 個のオブジェクト カテゴリ (キーボード、マウス、鉛筆、多くの動物など) に分類できます。この例では、複数ラベル分類用に、転移学習を使用して ResNet-50 の事前学習済みのネットワークの再学習を行います。使用可能なすべてのネットワークについては、事前学習済みの深層ニューラル ネットワークを参照してください。
事前学習済みのネットワークを読み込み、12 個のクラスを分類するようにネットワークを適応させます。
numClasses = 12;
net = imagePretrainedNetwork("resnet50",NumClasses=numClasses);イメージ入力サイズを抽出します。
inputSize = net.Layers(1).InputSize;
データの準備
https://cocodataset.org/#download で [2017 Train images]、[2017 Val images]、および [2017 Train/Val annotations] のリンクをクリックし、COCO 2017 の学習イメージと検証イメージをダウンロードして解凍します。"COCO" という名前のフォルダーにデータを保存します。COCO 2017 データ セットは Coco Consortium によって収集されたものです。インターネット接続の速度によっては、ダウンロード プロセスに時間がかかることがあります。
COCO データ セットのサブセットでネットワークに学習させます。この例では、異なる 12 個のカテゴリ (犬、猫、鳥、馬、羊、牛、熊、キリン、シマウマ、象、鉢植え、ソファー) を認識するようにネットワークに学習させます。
categoriesTrain = ["dog" "cat" "bird" "horse" "sheep" "cow" "bear" "giraffe" "zebra" "elephant" "potted plant" "couch"];
学習データの場所を指定します。
dataFolder = fullfile(tempdir,"COCO"); labelLocationTrain = fullfile(dataFolder,"annotations_trainval2017","annotations","instances_train2017.json"); imageLocationTrain = fullfile(dataFolder,"train2017");
この例の最後に定義されているサポート関数 prepareData を使用して、学習用のデータを準備します。
関数
jsondecodeを使用して、ファイルlabelLocationTrainからラベルを抽出します。目的のクラスに属するイメージを見つけます。
重複を除いたイメージ数を調べます。多くのイメージはクラス ラベルを複数もつため、イメージ リストの複数のカテゴリに登場します。
イメージ ID を各カテゴリのイメージ ID のリストと比較し、one-hot 符号化されたカテゴリ ラベルを作成します。
イメージとその拡張スキームを含む拡張イメージ データストアを作成します。
[dataTrain,encodedLabelTrain] = prepareData(labelLocationTrain,imageLocationTrain,categoriesTrain,inputSize,true); numObservations = dataTrain.NumObservations
numObservations = 30492
この学習データには、12 個のクラスに属する 30,492 個のイメージが含まれています。各イメージは、12 個の各クラスに属するかどうかを表すバイナリ ラベルをもちます。
学習データ同じ方法で検証データを準備します。
labelLocationVal = fullfile(dataFolder,"annotations_trainval2017","annotations","instances_val2017.json"); imageLocationVal = fullfile(dataFolder,"val2017"); [dataVal,encodedLabelVal] = prepareData(labelLocationVal,imageLocationVal,categoriesTrain,inputSize,false);
データの検査
各クラスのラベルの数を表示します。
numObservationsPerClass = sum(encodedLabelTrain,1);
figure
bar(numObservationsPerClass)
ylabel("Number of Observations")
xticklabels(categoriesTrain)
イメージごとのラベルの平均数を表示します。
numLabelsPerObservation = sum(encodedLabelTrain,2); mean(numLabelsPerObservation)
ans = 1.1352
figure histogram(numLabelsPerObservation) hold on ylabel("Number of Observations") xlabel("Number of Labels") hold off

学習オプション
学習に使用するオプションを指定します。SGDM ソルバーを使用して、初期学習率 0.0005 で学習させます。ミニバッチのサイズを 32 に設定し、最大 10 エポック学習させます。検証データを指定し、5 回続けて評価しても検証損失が減少しなかったときに学習を停止させるように設定します。学習の進行状況をプロットに表示し、平方根平均二乗誤差を監視します。
options = trainingOptions("sgdm", ... InitialLearnRate=0.0005, ... MiniBatchSize=32, ... MaxEpochs=10, ... Verbose= false, ... ValidationData=dataVal, ... ValidationFrequency=100, ... ValidationPatience=5, ... Metrics="rmse", ... Plots="training-progress");
ネットワークの学習
この例の実行時間を節約するには、doTraining を false に設定し、学習済みのネットワークを読み込んで dlnetwork オブジェクトに変換します。
自分でネットワークに学習させるには、doTraining を true に設定し、trainnet関数を使用してニューラル ネットワークに学習させます。複数ラベル分類の場合は、バイナリクロスエントロピー損失を使用します。学習プロットには RMSE と損失が表示されます。この例では、損失の方がネットワーク パフォーマンスの評価に役立ちます。既定では、関数 trainnet は利用可能な GPU がある場合にそれを使用します。GPU での学習には、Parallel Computing Toolbox™ ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。そうでない場合、関数 trainnet は CPU を使用します。実行環境を指定するには、ExecutionEnvironment 学習オプションを使用します。
doTraining = false; if doTraining trainedNet = trainnet(dataTrain,net,"binary-crossentropy",options); else filename = matlab.internal.examples.downloadSupportFile("nnet", ... "data/multilabelImageClassificationNetwork.zip"); filepath = fileparts(filename); dataFolder = fullfile(filepath,"multilabelImageClassificationNetwork"); unzip(filename,dataFolder); load(fullfile(dataFolder,"multilabelImageClassificationNetwork.mat")); trainedNet = dag2dlnetwork(trainedNet); end

モデル パフォーマンスの評価
検証データでモデル パフォーマンスを評価します。
このモデルは、入力イメージに各クラスが含まれる確率を予測します。これらの確率を使用してイメージのクラスを予測するには、しきい値を定義しなければなりません。このモデルは、確率がしきい値を超えるかどうかによって、イメージにクラスが含まれるかどうかを予測します。
しきい値によって、偽陽性と偽陰性の比率が制御されます。しきい値を大きくすると偽陽性の数が減り、しきい値を小さくすると偽陰性の数が減ります。必要とされるしきい値は用途によって異なります。この例では、しきい値を 0.5 に設定します。
thresholdValue = 0.5;
minibatchpredict関数を使用して予測を行い、検証データのクラス スコアを計算します。
scores = minibatchpredict(trainedNet,dataVal);
しきい値を使用して、このスコアを一連の予測クラスに変換します。
YPred = double(scores >= thresholdValue);
F1 スコア
モデル パフォーマンスを評価するには、一般に、"適合率" ("陽性の予測値" とも呼ばれます) および "再現率" ("感度" とも呼ばれます) という 2 つのメトリクスを使用します。
マルチラベル タスクの場合、各クラスについて適合率と再現率を個別に計算してその平均を計算するか (これは "マクロ平均化" と呼ばれます)、真陽性、偽陽性、偽陰性の総数を計算し、それらの値を使用して全体的な適合率と再現率を計算します (これは "マイクロ平均化" と呼ばれます)。この例では、マイクロ適合率とマイクロ再現率の値を使用します。
適合率と再現率を組み合わせて 1 つのメトリクスにするには、F1 スコア [1] を計算します。F1 スコアは、一般に、モデルの精度の評価に使用されます。
値 1 は、モデルが良好に機能していることを意味します。サポート関数 F1Score を使用して、検証データに関するマイクロ平均化された F1 スコアを計算します。
FScore = F1Score(encodedLabelVal,YPred)
FScore = 0.8158
ジャッカード指数
パフォーマンスの評価に役立つ別のメトリクスとして、"ジャッカード指数" ("Intersection over Union" とも呼ばれます) があります。このメトリクスは、ラベルの総数に対する正しいラベルの割合を比較します。サポート関数 jaccardIndex を使用して、検証データのジャッカード指数を計算します。
jaccardScore = jaccardIndex(encodedLabelVal,YPred)
jaccardScore = 0.7092
混同行列
各クラスについて、クラスのレベルでパフォーマンスを調べるには、予測ラベルと真のバイナリ ラベルを使用して混同チャートを計算します。
figure tiledlayout("flow") for i = 1:numClasses nexttile confusionchart(encodedLabelVal(:,i),YPred(:,i)); title(categoriesTrain(i)) end

しきい値の調査
しきい値がモデル評価メトリクスにどのように影響するかを調べます。複数のしきい値について、F1 スコアとジャッカード指数を計算します。また、サポート関数 performanceMetrics を使用して、複数のしきい値について適合率と再現率を計算します。
thresholdRange = 0.1:0.1:0.9; metricsName = ["F1-score","Jaccard Index","Precision","Recall"]; metrics = zeros(4,length(thresholdRange)); for i = 1:length(thresholdRange) YPred = double(scores >= thresholdRange(i)); metrics(1,i) = F1Score(encodedLabelVal,YPred); metrics(2,i) = jaccardIndex(encodedLabelVal,YPred); [precision, recall] = performanceMetrics(encodedLabelVal,YPred); metrics(3,i) = precision; metrics(4,i) = recall; end
結果をプロットします。
figure tiledlayout("flow") for i = 1:4 nexttile plot(thresholdRange,metrics(i,:),"-*") title(metricsName(i)) xlabel("Threshold") ylabel("Score") end

新しいデータを使用した予測
COCO データ セットから取得したものではない新しいイメージで、ネットワーク パフォーマンスをテストします。この結果によって、基となる複数の分布によってモデルがイメージを一般化できるかどうかがわかります。
imageNames = ["testMultilabelImage1.png" "testMultilabelImage2.png"];
各イメージについてラベルを予測し、その結果を表示します。
figure tiledlayout(1,2) images = []; labels = []; scores =[]; for i = 1:2 img = imread(imageNames(i)); img = imresize(img,inputSize(1:2)); images{i} = img; scoresImg = predict(trainedNet,single(img))'; YPred = categoriesTrain(scoresImg >= thresholdValue); nexttile imshow(img) title(YPred) labels{i} = YPred; scores{i} = scoresImg; end

ネットワークの予測の調査
ネットワークの予測をさらに調べるには、可視化手法を使用して、クラスの予測時にネットワークがイメージのどの領域を使用しているかを強調表示します。Grad-CAM は、ネットワークにより決定される畳み込みの特徴についての分類スコアの勾配を使用する可視化手法です。この手法を使用すると、各クラス ラベルについてイメージのどの部分が最も重要であるかを理解できます。この勾配が大きくなる場所は、最終的なスコアがデータに最も依存する場所を示します。
最初のイメージを調べます。このネットワークはイメージ内の猫とソファーを正しく識別しています。しかし、このネットワークは犬を識別できていません。
imageIdx = 1;
testImage = images{imageIdx};各クラスのスコアを含むテーブルを生成します。
tbl = table(categoriesTrain',scores{imageIdx},VariableNames=["Class", "Score"]);
disp(tbl) Class Score
______________ __________
"dog" 0.18477
"cat" 0.88647
"bird" 6.2184e-05
"horse" 0.0020663
"sheep" 0.00015361
"cow" 0.00077924
"bear" 0.0016855
"giraffe" 2.5157e-06
"zebra" 8.097e-05
"elephant" 9.5033e-05
"potted plant" 0.0051869
"couch" 0.80556
このネットワークは、このイメージに猫とソファーが含まれていると確信していますが、イメージに犬が含まれているかどうかについてはあまり確信がありません。Grad-CAM を使用して、それぞれの真のクラスについてネットワークがイメージのどの部分を使用しているかを確認します。
targetClasses = ["dog","cat","couch"]; targetClassesIdx = find(ismember(categoriesTrain,targetClasses));
各クラス ラベルについて Grad-CAM マップを生成します。
reductionLayer = "sigmoid";
map = gradCAM(trainedNet,testImage,targetClassesIdx,ReductionLayer=reductionLayer);Grad-CAM の結果をイメージに重ね合わせてプロットします。
figure tiledlayout("flow") nexttile imshow(testImage) for i = 1:length(targetClasses) nexttile imshow(testImage) hold on title(targetClasses(i)) imagesc(map(:,:,i),AlphaData=0.5) hold off end colormap jet

Grad-CAM マップを見ると、ネットワークがイメージ内のオブジェクトを正しく識別していることがわかります。
サポート関数
データの準備
サポート関数 prepareData は、マルチラベル分類の学習用および予測用の COCO データを準備します。
関数
jsondecodeを使用して、ファイルlabelLocationからラベルを抽出します。目的のクラスに属するイメージを見つけます。
重複を除いたイメージ数を調べます。多くのイメージは所与のラベルを複数もつため、イメージ リストの複数のカテゴリに登場します。
イメージ ID を各カテゴリのイメージ ID のリストと比較し、one-hot 符号化されたカテゴリ ラベルを作成します。
データと one-hot 符号化されたラベルを組み合わせてテーブルを作成します。
イメージを含む拡張イメージ データストアを作成します。グレースケール イメージを RGB イメージに変換します。
関数 prepareData は、サポート ファイルとして添付されている関数 COCOImageID を使用します。この関数にアクセスするには、この例をライブ スクリプトとして開きます。
function [data, encodedLabel] = prepareData(labelLocation,imageLocation,categoriesTrain,inputSize,doAugmentation) miniBatchSize = 32; % Extract labels. strData = fileread(labelLocation); dataStruct = jsondecode(strData); numClasses = length(categoriesTrain); % Find images that belong to the subset categoriesTrain using % the COCOImageID function, attached as a supporting file. images = cell(numClasses,1); for i=1:numClasses images{i} = COCOImageID(categoriesTrain(i),dataStruct); end % Find the unique images. imageList = [images{:}]; imageList = unique(imageList); numUniqueImages = numel(imageList); % Encode the labels. encodedLabel = zeros(numUniqueImages,numClasses); imgFiles = strings(numUniqueImages,1); for i = 1:numUniqueImages imgID = imageList(i); imgFiles(i) = fullfile(imageLocation + "\" + pad(string(imgID),12,"left","0") + ".jpg"); for j = 1:numClasses if ismember(imgID,images{j}) encodedLabel(i,j) = 1; end end end % Define the image augmentation scheme. imageAugmenter = imageDataAugmenter( ... RandRotation=[-45,45], ... RandXReflection=true); % Store the data in a table. dataTable = table(Size=[numUniqueImages 2], ... VariableTypes=["string" "double"], ... VariableNames=["File_Location" "Labels"]); dataTable.File_Location = imgFiles; dataTable.Labels = encodedLabel; % Create a datastore. Transform grayscale images into RGB. if doAugmentation data = augmentedImageDatastore(inputSize(1:2),dataTable, ... ColorPreprocessing="gray2rgb", ... DataAugmentation=imageAugmenter); else data = augmentedImageDatastore(inputSize(1:2),dataTable, ... ColorPreprocessing="gray2rgb"); end data.MiniBatchSize = miniBatchSize; end
F1 スコア
サポート関数 F1Score は、マイクロ平均化された F1 スコア [1] を計算します。
function score = F1Score(T,Y) % TP: True Positive % FP: False Positive % TN: True Negative % FN: False Negative TP = sum(T .* Y,"all"); FP = sum(Y,"all")-TP; TN = sum(~T .* ~Y,"all"); FN = sum(~Y,"all")-TN; score = TP/(TP + 0.5*(FP+FN)); end
ジャッカード指数
サポート関数 jaccardIndex は、ジャッカード指数 (Intersection over Union とも呼ばれます) を次式で計算します。
,
ここで、"T" と "Y" はターゲットと予測に対応します。ジャッカード指数は、ラベルの総数に対する正しいラベルの割合を比較します。
function score = jaccardIndex(T,Y) intersection = sum((T.*Y)); union = T+Y; union(union < 0) = 0; union(union > 1) = 1; union = sum(union); % Ensure the accuracy is 1 for instances where a sample does not belong to any class % and the prediction is correct. For example, T = [0 0 0 0] and Y = [0 0 0 0]. noClassIdx = union == 0; intersection(noClassIdx) = 1; union(noClassIdx) = 1; score = mean(intersection./union); end
適合率と再現率
モデル評価には、一般に、適合率 (陽性の予測値とも呼ばれます) および再現率 (感度とも呼ばれます) という 2 つのメトリクスを使用します。
サポート関数 performanceMetrics は、マイクロ平均化された適合率と再現率の値を計算します。
function [precision, recall] = performanceMetrics(T,Y) % TP: True Positive % FP: False Positive % TN: True Negative % FN: False Negative TP = sum(T .* Y,"all"); FP = sum(Y,"all")-TP; TN = sum(~T .* ~Y,"all"); FN = sum(~Y,"all")-TN; precision = TP/(TP+FP); recall = TP/(TP+FN); end
参考文献
[1] Sokolova, Marina, and Guy Lapalme. "A Systematic Analysis of Performance Measures for Classification Tasks." Information Processing & Management 45, no. 4 (2009): 427–437.
参考
gradCAM | imagePretrainedNetwork | trainnet | trainingOptions | dlnetwork