YOLO v2 入門
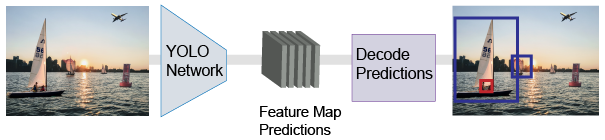
You-Only-Look-Once (YOLO) v2 オブジェクト検出器は、single stage オブジェクトの検出ネットワークを使用します。YOLO v2 は、畳み込みニューラル ネットワーク (Faster R-CNN) を含む領域などの、2 段階の深層学習オブジェクト検出器より高速です。
YOLO v2 モデルは、入力イメージに対して深層学習 CNN を実行し、ネットワーク予測を生成します。オブジェクト検出器は予測を復号化し、境界ボックスを生成します。
YOLO v2 は、アンカー ボックスを使用してイメージ内のオブジェクトのクラスを検出します。詳細については、アンカー ボックスによるオブジェクトの検出を参照してください。YOLO v2 は、各アンカー ボックスに対して次の 3 つの属性を予測します。
Intersection over Union (IoU) — 各アンカー ボックスのオブジェクトらしさのスコアを予測します。
アンカー ボックスのオフセット — アンカー ボックスの位置を調整します。
クラス確率 — 各アンカー ボックスに割り当てられるクラス ラベルを予測します。
次の図は、特徴マップ内の各位置の事前定義されたアンカー ボックス (破線) と、オフセットの適用後の調整された位置を示します。クラスと一致したボックスは色付きで表示されます。

事前学習済みの YOLO v2 検出器を使用したオブジェクトの検出
事前学習済みの YOLO v2 ネットワークを使用してオブジェクトを検出するには、まず、サポートされている事前学習済みネットワークの名前を指定して yolov2ObjectDetector オブジェクトを作成します。次の事前学習済みネットワークが用意されています。
darknet19-coco— DarkNet-19 をベースにした YOLO v2 ネットワーク。tiny-yolov2-coco— フィルターと畳み込み層が少ない小さな YOLO v2 ネットワーク。
この 2 つのネットワークは COCO データ セットで学習させており、COCO データ セットから 80 個のクラスを検出できます。これらの YOLO v2 事前学習済みネットワークをダウンロードするには、Computer Vision Toolbox™ Model for YOLO v2 Object Detection サポート パッケージをインストールしなければなりません。
事前学習済みの YOLO v2 オブジェクト検出器を作成した後、detect 関数を使用してオブジェクトを検出します。
事前学習済みの YOLO v2 検出器を使用した転移学習の実行
事前学習済みの YOLO v2 検出器で転移学習を実行します。ネットワークの名前 ("darknet19-coco" または "tiny-yolov2-coco") を指定するか、事前学習済みの YOLO v2 ネットワークを含む dlnetwork オブジェクトを指定して、事前学習済みの yolov2ObjectDetector オブジェクトを作成します。転移学習用に YOLO v2 ネットワークを構成するには、アンカー ボックスと新しいオブジェクト クラスも指定します。ネットワークにマルチスケール学習を実行させる場合は、TrainingImageSizes プロパティを設定して複数の学習イメージ サイズを指定します。
事前学習済みの YOLO v2 検出器とラベル付き学習データを使用して転移学習を実行するには、trainYOLOv2ObjectDetector 関数を使用します。
転移学習を行った後、detect 関数を使用してオブジェクトを検出します。
カスタム YOLO v2 ネットワークの学習
YOLO v2 ネットワーク アーキテクチャをさらに詳細に制御する必要がある場合は、カスタム YOLO v2 ネットワークを作成できます。次の手順に従って、事前学習済みの特徴抽出ネットワークをカスタム YOLO v2 ネットワークに変換できます。例については、カスタム YOLO v2 オブジェクト検出ネットワークの作成を参照してください。
imagePretrainedNetwork(Deep Learning Toolbox) 関数を使用して、MobileNet v2 などの事前学習済み CNN を読み込みます。ベース ネットワークから特徴抽出層を選択します。この層は検出ヘッドへの入力です。
ベースの特徴抽出ネットワーク、および特徴抽出層の名前を指定して、
yolov2ObjectDetectorオブジェクトを作成します。また、ネットワークに学習させるための入力として、クラスの名前とアンカー ボックスを指定します。YOLO v2 オブジェクト検出器の動作を調整するには、追加のプロパティを設定します。ネットワークにマルチスケール学習を実行させる場合は、
TrainingImageSizeプロパティを設定して複数の学習イメージ サイズを指定します。小さなオブジェクトの検出精度を向上させるには、
ReorganizeLayerSourceプロパティを指定して再編成分岐を追加します。
yolov2ObjectDetectorオブジェクトは、特徴抽出層より後ろのすべての層をベース ネットワークから削除します。また、このオブジェクトは、深さ連結層で終わる検出ヘッド、および生の CNN 出力をオブジェクト検出結果の生成に必要な形式に変換するyolov2TransformLayerを組み立てます。最後に、このオブジェクトは特徴抽出層の出力を検出ヘッドに接続します。次の図に検出ヘッドの層を示します。オプションで再編成分岐を含めると、オブジェクトはネットワークに
spaceToDepthLayerとdepthConcatenationLayer(Deep Learning Toolbox) を追加します。空間から深さへの変換層は、ベース ネットワークから低レベルの特徴を抽出します。深さ連結層は、検出ヘッドから得られた高レベルの特徴を低レベルの特徴と結合します。次の図に、再編成分岐を含むように変更されたネットワークを示します。
ヒント
通常、事前学習済みのネットワークから始めると、ベース ネットワークを層ごとに組み立てるよりも、はるかに速く簡単に構築を行えます。ただし、ベース ネットワークを組み立てる必要がある場合は、対話形式のディープ ネットワーク デザイナー (Deep Learning Toolbox) アプリ、または addLayers (Deep Learning Toolbox) や connectLayers (Deep Learning Toolbox) などの関数を使用できます。
カスタム YOLO v2 ネットワークを作成した後、trainYOLOv2ObjectDetector 関数を使用して、ラベル付きデータ セットでネットワークに学習させます。例については、YOLO v2 深層学習を使用したオブジェクトの検出を参照してください。
ネットワークに学習させた後、detect 関数を使用してオブジェクトを検出します。
コード生成
YOLO v2 オブジェクト検出器 (yolov2ObjectDetector オブジェクトを使用して作成) を使用した CUDA® コードの生成方法の詳細については、YOLO v2 を使用したオブジェクト検出のコードの生成を参照してください。
深層学習用学習データのラベル付け
イメージ ラベラー、ビデオ ラベラー、またはグラウンド トゥルース ラベラー (Automated Driving Toolbox) アプリを使用して、対話形式でピクセルにラベル付けし、ラベル データを学習用にエクスポートできます。アプリは、オブジェクト検出用の四角形の関心領域 (ROI)、イメージ分類用のシーン ラベル、セマンティック セグメンテーション用のピクセルにラベルを付けるためにも使用できます。いずれかのラベラーでエクスポートされたグラウンド トゥルース オブジェクトから学習データを作成するには、関数 objectDetectorTrainingData または関数 pixelLabelTrainingData を使用できます。詳細については、オブジェクト検出およびセマンティック セグメンテーション用の学習データを参照してください。
参照
[1] Redmon, Joseph, and Ali Farhadi. “YOLO9000: Better, Faster, Stronger.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6517–25. Honolulu, HI: IEEE, 2017. https://doi.org/10.1109/CVPR.2017.690.
[2] Redmon, Joseph, Santosh Divvala, Ross Girshick, and Ali Farhadi. "You only look once: Unified, real-time object detection." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 779–788. Las Vegas, NV: CVPR, 2016.
参考
アプリ
- イメージ ラベラー | グラウンド トゥルース ラベラー (Automated Driving Toolbox) | ビデオ ラベラー | ディープ ネットワーク デザイナー (Deep Learning Toolbox)
オブジェクト
yolov2ObjectDetector|yolov2TransformLayer|spaceToDepthLayer|depthConcatenationLayer(Deep Learning Toolbox)
関数
trainYOLOv2ObjectDetector|analyzeNetwork(Deep Learning Toolbox)
トピック
- YOLO v2 深層学習を使用したオブジェクトの検出
- YOLO v2 を使用したオブジェクト検出のコードの生成
- オブジェクト検出器の選択
- アンカー ボックスによるオブジェクトの検出
- MATLAB による深層学習 (Deep Learning Toolbox)
- 事前学習済みの深層ニューラル ネットワーク (Deep Learning Toolbox)