カスケード型オブジェクト検出器入門
検出器に学習させる理由
vision.CascadeObjectDetector System object™ には、顔の正面、横顔、鼻、目、および上半身を検出するための事前学習済みの分類器がいくつか付属しています。ただし、アプリケーションによってはこれらの分類器では不十分な場合もあります。Computer Vision Toolbox™ には、カスタム分類器に学習させるための関数 trainCascadeObjectDetector が用意されています。
検出できるオブジェクトのタイプ
Computer Vision Toolbox のカスケード型オブジェクト検出器では、縦横比があまり変化しないオブジェクト カテゴリを検出できます。縦横比が一定であるオブジェクトには、顔、一時停止標識、特定方向から見た自動車などがあります。
vision.CascadeObjectDetector System object は、イメージ上でウィンドウをスライドさせてイメージ内のオブジェクトを検出します。その後、カスケード分類器を使用して、ウィンドウに対象オブジェクトが含まれるかどうかを判断します。さまざまなスケールでオブジェクトを検出するためにウィンドウのサイズは変わりますが、縦横比は固定されています。ほとんどの 3 次元オブジェクトでは縦横比が変わるため、検出器は、面外の回転により非常に大きな影響を受けます。したがって、オブジェクトのすべての向きを使って検出器に学習させなければなりません。1 つの検出器ですべての向きを処理できるように学習させることはできません。
カスケード分類器の仕組み
カスケード分類器は複数のステージで構成されています。それぞれのステージは弱学習器のアンサンブルです。弱学習器は "決定株" と呼ばれるシンプルな分類器です。各ステージの学習にはブースティングという手法が使用されます。"ブースティング" は、弱学習器による決定の加重平均を取ることで、非常に正確な分類器に学習させる機能を提供します。
分類器の各ステージにより、スライディング ウィンドウの現在の位置で定義される領域にポジティブまたはネガティブのラベルが付けられます。"ポジティブ" はオブジェクトが見つかったことを、"ネガティブ" はオブジェクトが見つからなかったことを示します。ラベルがネガティブの場合には、この領域の分類が完了し、検出器はウィンドウを次の位置にスライドさせます。ラベルがポジティブの場合は、分類器がその領域を次のステージに渡します。検出器は、最後のステージで領域がポジティブと分類された場合、現在のウィンドウ位置で見つかったオブジェクトを報告します。
これらのステージは、できるだけ早期にネガティブ サンプルを棄却するように設計されています。ここでは大部分のウィンドウには対象オブジェクトが含まれないことを仮定しています。逆に、真陽性は稀であるため、時間をかけて確認する必要があります。
"真陽性" は、ポジティブ サンプルが正しく分類された場合に生じます。
"偽陽性" は、ネガティブ サンプルが誤って正として分類された場合に生じます。
"偽陰性" は、ポジティブ サンプルが誤って負として分類された場合に生じます。
検出器が適切に機能するためには、カスケードの各ステージで偽陰性率が低く設定されていなければなりません。あるステージでオブジェクトが誤って負と判断されると分類処理が停止するため、この誤りを修正することはできません。ただし、各ステージの偽陽性率は高い値に設定できます。検出器でオブジェクトでないものが正と判断されても、その誤りはその後のステージで修正できます。
カスケード分類器の全体的な偽陽性率は です。ここで、 は範囲 (0 1) にある各ステージの偽陽性率を、 はステージ数をそれぞれ示します。同様に、全体的な真陽性率は であり、 は範囲 (0 1] にある各ステージの真陽性率を示します。したがって、ステージ数を増やすと全体的な偽陽性率が下がりますが、全体的な真陽性率も下がります。
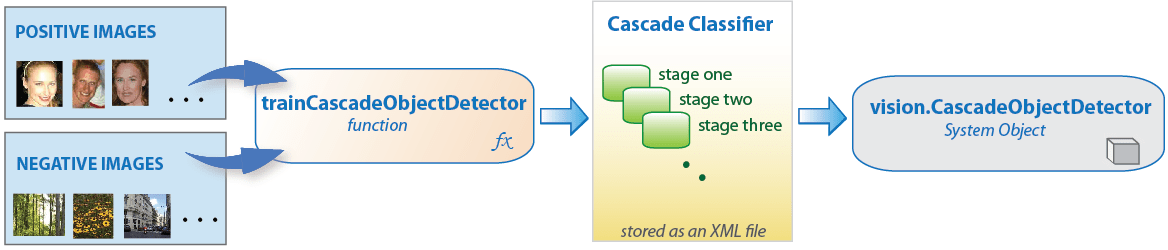
trainCascadeObjectDetector を使用したカスケード分類器の作成
カスケード分類器の学習には一連のポジティブ サンプルと一連のネガティブ イメージが必要です。ポジティブ サンプルとして使用する、関心領域が指定された一連のポジティブ イメージを提供しなければなりません。イメージ ラベラーを使用して、対象オブジェクトに境界ボックスでラベルを付けることができます。イメージ ラベラーは、ポジティブ サンプルとして使用される table を出力します。また、関数でネガティブ サンプルを自動的に生成するための一連のネガティブ イメージも提供しなければなりません。検出器の精度が適切な水準に達するよう、ステージ数、特徴のタイプおよびその他の関数パラメーターを設定します。

パラメーター設定の考慮事項
学習に使用するステージ数、偽陽性率、真陽性率、特徴のタイプがそれぞれ最適になるような関数パラメーターを選択します。パラメーターの設定時には以下のトレードオフを考慮してください。
| 条件 | 考慮事項 |
|---|---|
| 学習セットが大きい (千単位)。 | ステージ数を増やして各ステージの偽陽性率を高い値に設定します。 |
| 学習セットが小さい。 | ステージ数を減らして各ステージの偽陽性率を低い値に設定します。 |
| オブジェクトを検知できない確率を減らす。 | 真陽性率を大きくします。ただし、真陽性率が高い場合、各ステージで必要な偽陽性率が得られず、検出器で誤検知が多発する可能性があります。 |
| 誤検知の数を減らす。 | ステージ数を増やすか、各ステージの偽警報率を減らします。 |
学習に使用できる特徴のタイプ
必要なオブジェクト検出のタイプに適した特徴を選択してください。trainCascadeObjectDetector は、次の 3 種類の特徴をサポートしています。Haar、ローカル バイナリ パターン (LBP)、勾配方向ヒストグラム (HOG) です。Haar 特徴および LBP 特徴は、スケールの細かいテクスチャの表現に向いているため、顔の検出によく使用されます。HOG 特徴は、人や自動車などのオブジェクトの検出によく使用されます。これらはオブジェクトの全体的な形状をキャプチャするのに便利です。たとえば、以下に示す HOG 特徴の可視化では、自転車の外郭がわかります。

場合によっては、パラメーターを調整するために関数 trainCascadeObjectDetector を何度か実行しなければなりません。時間を節約するために、データの小さいサブセットに対して LBP または HOG 特徴を使用できます。Haar 特徴を使用した検出器の学習には長い時間がかかります。その後、Haar 特徴を実行して精度が向上したかどうかを確認できます。
ポジティブ サンプルの指定
ポジティブ サンプルを簡単に作成するには、イメージ ラベラー アプリを使用できます。イメージ ラベラーでは、対話形式で四角形の関心領域 (ROI) を指定して、ポジティブ サンプルに簡単にラベルを付けることができます。

また、次の 2 つの方法のいずれかを使用してポジティブ サンプルを手動で指定することもできます。最初の方法では、大きいイメージ内に四角形の領域を指定します。これらの領域には対象オブジェクトが含まれています。2 番目の方法では、対象オブジェクトをイメージからトリミングし、これを個別のイメージとして保存します。その後、イメージ全体を領域として指定できます。さらに、既存のサンプルに回転やノイズを加えたり、輝度やコントラストを変更して、追加のポジティブ サンプルを生成することもできます。
ネガティブ イメージの指定
ネガティブ サンプルは明示的に指定されません。代わりに、関数 trainCascadeObjectDetector は、ユーザーが指定した、対象オブジェクトが含まれないネガティブ イメージから自動的にネガティブ サンプルを生成します。関数は新しい各ステージに学習させる前に、ネガティブ イメージで既に学習済みのステージから構成される検出器を実行します。これらのイメージから検出されたオブジェクトはすべて誤検知であり、ネガティブ サンプルとして使用されます。この方法では、カスケードの新しい各ステージが、その前のステージで生じた誤りを正すように学習が行われます。
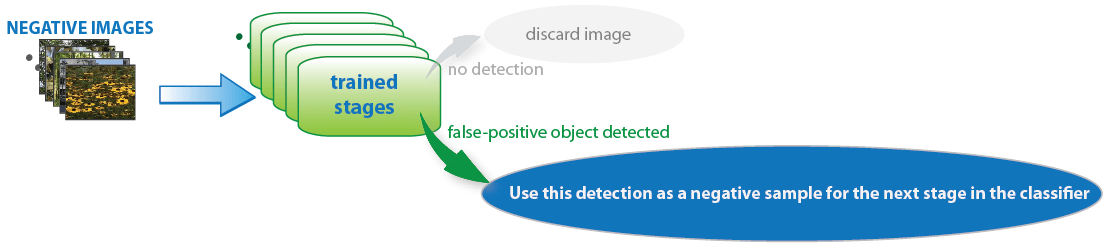
ステージを追加するにつれて検出器の全体的な偽陽性率が下がるため、ネガティブ サンプルの生成は難しくなります。そのため、ネガティブ イメージをできる限り多く提供すると役に立ちます。学習の精度を高めるには、対象オブジェクトに通常関連のある背景を含むネガティブ イメージを提供してください。また、対象オブジェクトに似た外観をもつ、オブジェクトではないものを含むネガティブ イメージも含めます。たとえば、一時停止標識検出器に学習させる場合、一時停止標識に類似した交通標識や形を含むネガティブ イメージを含めてください。
ステージ数の選択
ステージ数を減らすと各ステージの偽陽性率が下がり、ステージ数を増やすと各ステージの偽陽性率が上がるため、これはトレードオフとなります。偽陽性率が低いステージは、より多くの弱学習器を含むため、複雑度が高くなります。一方、偽陽性率が高いステージには、より少数の弱学習器が含まれます。一般に、ステージが増えるにつれて全体的な偽陽性率は指数的に小さくなるため、シンプルなステージを多く含める方が得策です。たとえば、各ステージの偽陽性率が 50% である場合、2 ステージ構成のカスケード分類器の全体的な偽陽性率は 25% になります。3 ステージ構成の場合には、これが 12.5% になり、その後も同様に率が減少します。ただし、ステージ数が大きいほど、分類器に必要な学習データの量は増大します。また、ステージ数を増やすと偽陰性率も高くなります。この増加により、ポジティブ サンプルを誤って棄却する確率が上がります。偽陽性率 (FalseAlarmRate) とステージ数 (NumCascadeStages) は、全体的な偽陽性率が許容範囲内に収まるように設定してください。その後、この 2 つのパラメーターを実験的に調整できます。
学習が早期終了する場合もあります。たとえば、ステージ数パラメーターを 20 に設定したにもかかわらず、7 ステージ後に学習が停止したとします。その場合、関数で十分な数のネガティブ サンプルが生成されなかった可能性があります。関数を再実行してステージ数を 7 に設定しても、同じ結果は得られません。各ステージで使用される正とネガティブ サンプルの数は新しいステージ数に合わせて再計算されるため、結果はステージごとに異なります。
検出器の学習所要時間
良質の検出器の学習には数千単位の学習サンプルが必要です。大量の学習データを処理するには数時間から数日に及ぶ長い時間がかかります。学習中は、関数によって各ステージの学習にかかった時間が MATLAB® のコマンド ウィンドウに表示されます。学習所要時間は指定した特徴のタイプによって異なります。Haar 特徴を使用すると、LBP や HOG 特徴を使用した場合よりもずっと多くの時間がかかります。
トラブルシューティング
ポジティブ サンプルが足りなくなった場合の対処方法
関数 trainCascadeObjectDetector は、各ステージの学習に使用されるポジティブ サンプルの数を自動的に決定します。この数は、ユーザーが提供したポジティブ サンプルの総数と、TruePositiveRate および NumCascadeStages パラメーターの値に基づいています。
各ステージの学習に使用可能なポジティブ サンプルの数は、真陽性率に依存します。この率は、ポジティブ サンプルのうち関数で負として分類することのできるサンプルの割合を指定します。いずれかのステージで負として分類されたサンプルが、その後のステージに進むことはありません。たとえば、TruePositiveRate を 0.9 に設定し、使用可能なサンプルのすべてが第 1 ステージの学習に使用されたとします。その場合、ポジティブ サンプルの 10% が負として棄却されるため、第 2 ステージの学習に使用できるのはポジティブ サンプル全体の 90% だけになります。学習を継続した場合、各ステージの学習に使用できるサンプル数は徐々に減り続けます。したがって、後続の各ステージでは、より少数のポジティブ サンプルを使用して、さらに困難な分類問題を解かなければなりません。ステージが進むにつれて使用できるサンプル数が少なくなると、後のステージでデータの過適合が生じる可能性が大きくなります。
各ステージの学習には同数のサンプルを使用するのが理想的です。そのためには、各ステージの学習に使用されるポジティブ サンプルの数が、使用可能なポジティブ サンプルの総数未満でなければなりません。唯一の例外として、TruePositiveRate の値にポジティブ サンプル総数を乗算した値が 1 未満の場合には、ポジティブ サンプルが負として棄却されることはなくなります。
関数では、次の式を使用して各ステージで使用するポジティブ サンプルの数を計算します。
number of positive samples = floor(totalPositiveSamples / (1 + (NumCascadeStages - 1) * (1 - TruePositiveRate)))
TruePositiveRate の値を大きくすることも可能です。ステージ数を減らすオプションもありますが、その場合は全体の偽警報率が増加する可能性があります。 ネガティブ サンプルが足りなくなった場合の対処
関数は各ステージで使用されるネガティブ サンプルの数を計算します。これは各ステージで使用されるポジティブ サンプルの数に、NegativeSamplesFactor の値を乗算して求められます。
ポジティブ サンプルの場合と同様に、計算されたネガティブ サンプル数を特定のステージで必ずしも使用できるとは限りません。関数 trainCascadeObjectDetector は、ネガティブ イメージからネガティブ サンプルを生成します。ただし、新しいステージに進むにつれてカスケード分類器の全体的な偽警報率が下がるため、ネガティブ サンプルが見つかる確率も下がります。
あるステージで学習に使用できるネガティブ サンプル数が、計算されたネガティブ サンプル数の 10% を上回っていれば、学習は継続されます。ネガティブ サンプルの数が足りなくなると学習は停止され、関数から警告が出力されます。また、その時点までに学習の済んだステージを含む分類器も出力されます。学習が停止した場合は、ネガティブ イメージをさらに追加するのが最良の対処法です。あるいは、ステージ数を減らしたり、偽陽性率を高く設定することもできます。
例



一時停止標識検出器の学習
MAT ファイルからポジティブ サンプル データを読み込みます。このファイルにはグラウンド トゥルースが含まれています。いくつかのオブジェクト カテゴリに対する境界ボックスの table として指定します。このグラウンド トゥルースは、イメージ ラベラー アプリからラベル付けしてエクスポートされています。
load("stopSignsAndCars.mat");一時停止標識のイメージの前に絶対パスを付けます。
stopSigns = fullfile(toolboxdir("vision"),"visiondata",stopSignsAndCars{:,1});
データストアを作成して、一時停止標識のグラウンド トゥルース データを読み込みます。
imds = imageDatastore(stopSigns); blds = boxLabelDatastore(stopSignsAndCars(:,2));
イメージ データストアとボックス ラベル データストアを組み合わせます。
positiveInstances = combine(imds,blds);
MATLAB® パスにイメージ フォルダーのパスを追加します。
imDir = fullfile(matlabroot,"toolbox","vision","visiondata","stopSignImages"); addpath(imDir);
ネガティブ イメージのフォルダーを指定します。
negativeFolder = fullfile(matlabroot,"toolbox","vision","visiondata","nonStopSigns");
ネガティブ イメージを含む imageDatastore オブジェクトを作成します。
negativeImages = imageDatastore(negativeFolder);
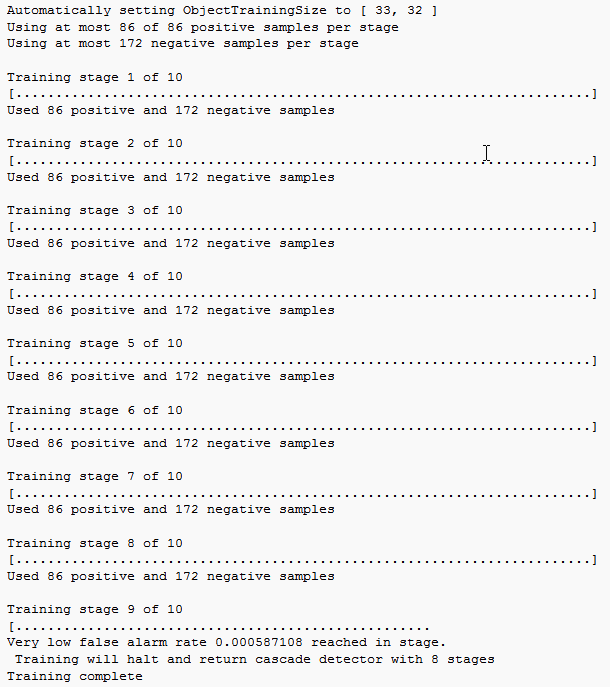
HOG 特徴を使用して "stopSignDetector.xml" という名前のカスケード型オブジェクト検出器に学習させます。メモ: コマンドの実行には数分かかる場合があります。
trainCascadeObjectDetector("stopSignDetector.xml",positiveInstances,negativeFolder,FalseAlarmRate=0.01,NumCascadeStages=3);Automatically setting ObjectTrainingSize to [35, 32] Using at most 42 of 42 positive samples per stage Using at most 84 negative samples per stage --cascadeParams-- Training stage 1 of 3 [........................................................................] Used 42 positive and 84 negative samples Time to train stage 1: 0 seconds Training stage 2 of 3 [........................................................................] Used 42 positive and 84 negative samples Time to train stage 2: 0 seconds Training stage 3 of 3 [........................................................................] Used 42 positive and 84 negative samples Time to train stage 3: 1 seconds Training complete
新たに学習させた分類器を使用して、イメージ内の一時停止標識を検出します。
detector = vision.CascadeObjectDetector("stopSignDetector.xml");テスト イメージを読み取ります。
img = imread("stopSignTest.jpg");テスト イメージ内の一時停止標識を検出します。
bbox = step(detector,img);
境界ボックスの四角形を挿入し、マークしたイメージを返します。
detectedImg = insertObjectAnnotation(img,"rectangle",bbox,"stop sign");
検出した一時停止標識を表示します。
figure imshow(detectedImg)

パスからイメージ フォルダーを削除します。
rmpath(imDir);