matchFeatures
マッチする特徴の検出
構文
説明
indexPairs = matchFeatures(features1,features2)binaryFeatures オブジェクトまたは行列でなければなりません。
[ はさらに、indexPairs,matchmetric] = matchFeatures(features1,features2)indexPairs によってインデックス付けされたマッチする特徴間の距離を返します。
[ は、前の構文にある引数の任意の組み合わせに加えて、名前と値の引数を 1 つ以上使用してオプションを指定します。たとえば、indexPairs,matchmetric] = matchFeatures(features1,features2,Name=Value)matchFeatures(__,Method="Exhaustive") は、マッチング法を Exhaustive に設定します。
例
局所近傍と Harris 法アルゴリズムを使用してイメージのペア間で対応する関心点を見つけます。
ステレオ イメージを読み取ります。
I1 = im2gray(imread("viprectification_deskLeft.png")); I2 = im2gray(imread("viprectification_deskRight.png"));
コーナーを検出します。
points1 = detectHarrisFeatures(I1); points2 = detectHarrisFeatures(I2);
近傍特徴を抽出します。
[features1,valid_points1] = extractFeatures(I1,points1); [features2,valid_points2] = extractFeatures(I2,points2);
特徴をマッチします。
indexPairs = matchFeatures(features1,features2);
各イメージの対応する点の位置を取得します。
matchedPoints1 = valid_points1(indexPairs(:,1),:); matchedPoints2 = valid_points2(indexPairs(:,2),:);
対応する点を可視化します。誤ったマッチもいくつかありますが、2 つのイメージ間の平行移動の効果がわかります。
figure; showMatchedFeatures(I1,I2,matchedPoints1,matchedPoints2);

2 つのイメージを読み取ります。
I1 = imread("cameraman.tif");
I2 = imresize(imrotate(I1,-20),1.2);SURF 特徴量を見つけます。
points1 = detectSURFFeatures(I1); points2 = detectSURFFeatures(I2);
特徴を抽出します。
[f1,vpts1] = extractFeatures(I1,points1); [f2,vpts2] = extractFeatures(I2,points2);
マッチする点の位置を取得します。
indexPairs = matchFeatures(f1,f2) ; matchedPoints1 = vpts1(indexPairs(:,1)); matchedPoints2 = vpts2(indexPairs(:,2));
マッチする点を表示します。データにはまだ多少の外れ値が含まれていますが、マッチする特徴の表示により回転とスケーリングの効果を確認できます。
figure; showMatchedFeatures(I1,I2,matchedPoints1,matchedPoints2); legend("matched points 1","matched points 2");

入力引数
名前と値の引数
オプションの引数のペアを Name1=Value1,...,NameN=ValueN として指定します。ここで、Name は引数名で、Value は対応する値です。名前と値の引数は他の引数の後に指定しなければなりませんが、ペアの順序は重要ではありません。
R2021a より前では、コンマを使用して名前と値をそれぞれ区切り、Name を引用符で囲みます。
例: Method="Exhaustive" は、マッチング法を Exhaustive に設定します。
マッチング法。"Exhaustive" または "Approximate" として指定します。手法は、features1 と features2 の間での最近傍の検出方法を指定します。2 つの特徴ベクトル間の距離が MatchThreshold パラメーターによって設定されたしきい値より小さい場合、これらの特徴ベクトルがマッチします。
"Exhaustive" |
|
"Approximate" | 効率的で適切な最近傍探索を使用します。大規模な特徴セットにはこの手法を使用します。[3] |
マッチングのしきい値。(0,100] の範囲のスカラーのパーセント値として指定します。既定値は、バイナリ特徴ベクトルの場合は 10.0、または非バイナリ特徴ベクトルの場合は 1.0 に設定されます。マッチングのしきい値は、最も強いマッチを選択するために使用できます。しきい値は、完全マッチからの距離をパーセントで表します。
2 つの特徴ベクトル間の距離が MatchThreshold によって設定されたしきい値より小さい場合、これらの特徴ベクトルがマッチします。特徴間の距離が MatchThreshold の値より大きい場合、関数はマッチを除外します。より多くのマッチを返すには、この値を大きくします。
入力が binaryFeatures オブジェクトの場合は通常、マッチングのしきい値を大きくする必要があります。FREAK、ORB、または BRISK 記述子を抽出するときに、関数 extractFeatures は binaryFeatures オブジェクトを返します。
比率のしきい値。(0,1] の範囲のスカラーの比率値として指定します。あいまいなマッチを除外する最大比率を使用します。より多くのマッチを返すには、この値を大きくします。
特徴のマッチング メトリクス。"SAD" または "SSD" として指定します。
"SAD" | 差の絶対値の和 |
"SSD" | 差の二乗和 |
このプロパティは、入力特徴セット features1 と features2 が binaryFeatures オブジェクトではない場合に適用されます。特徴を binaryFeatures オブジェクトとして指定している場合、関数はハミング距離を使用して類似度メトリクスを計算します。
一意のマッチ。false または true として指定します。features1 と features2 間の一意のマッチのみを返すようにするには、この値を true に設定します。
Unique を false に設定すると、関数は features1 と features2 間のすべてのマッチを返します。features1 の複数の特徴が features2 の 1 つの特徴にマッチする場合があります。
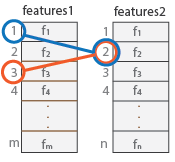
Unique を true に設定すると、関数は順方向と逆方向のマッチングを実行して、一意のマッチを選択します。features1 を features2 にマッチさせた後、features2 を features1 にマッチさせて、最適一致を保持します。
出力引数
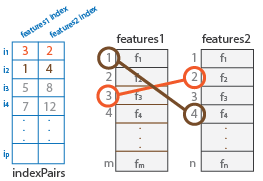
マッチする特徴間の距離。p 行 1 列のベクトルとして返されます。距離の値は、選択されたメトリクスに基づきます。matchmetric の i 番目の要素は、それぞれ indexPairs 出力行列の i 行目に対応します。Metric が SAD または SSD に設定されている場合、計算前に特徴ベクトルが単位ベクトルに正規化されます。
参照
[1] Lowe, David G. "Distinctive Image Features from Scale-Invariant Keypoints." International Journal of Computer Vision. Volume 60, Number 2, pp. 91–110.
[2] Muja, M., and D. G. Lowe. "Fast Matching of Binary Features. "Conference on Computer and Robot Vision. CRV, 2012.
[3] Muja, M., and D. G. Lowe. "Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration." International Conference on Computer Vision Theory and Applications.VISAPP, 2009.
[4] Rublee, E., V. Rabaud, K. Konolige and G. Bradski. "ORB: An efficient alternative to SIFT or SURF." In Proceedings of the 2011 International Conference on Computer Vision, 2564–2571. Barcelona, Spain, 2011.
拡張機能
バージョン履歴
R2011a で導入