診断特徴デザイナー
機械の診断と予測のために、測定データまたはシミュレーション データから特徴を対話的に抽出、可視化、ランク付けする
説明
診断特徴デザイナー アプリを使うと、多機能グラフィカル インターフェイスを使用して、予知保全ワークフローの特徴設計の部分を実行できるようになります。特徴を対話的に設計および比較してから、定格システムからのデータと故障システムからのデータの区別に最も適した特徴を決定します。最も効果的な特徴は、最終的に故障の診断と予知のための状態インジケーターとなります。
このアプリを使用して、次のことを実行できます。
個々のファイル、アンサンブル ファイル、またはアプリ外部のファイルを参照するアンサンブル データストアから、測定データまたはシミュレーション データをインポートする。適切なツールボックスがインストールされ、ライセンスが付与されていれば、信号ラベラーおよびアナログ入力レコーダー (Data Acquisition Toolbox)からデータをインポートし、診断特徴デザイナーに直接エクスポートすることもできます。
データを対話的に可視化して、インポートするアンサンブル変数またはアプリ内で計算するアンサンブル変数をプロットする。プロット内のデータを状態ラベルでグループ化すると、メンバー データが定格システムと故障システムのどちらに由来するのかを明確に示すことができます。
時間同期平均化信号または次数スペクトルなどの新しい変数を導出する。アプリは、1 つのコマンドですべてのアンサンブル メンバーに対して処理を実行します。
変数から特徴を生成し、ヒストグラムを使用してその有効度を可視化する。特徴には、信号統計、非線形メトリクス、回転機メトリクス、スペクトル メトリクスが含まれます。独自のカスタム特徴を作成することもできます。
特徴をランク付けして、データ内の動作の違いを区別する上で最適な特徴を判定する。
ラベル付けされた特徴またはシステム応答データを使用して教師ありのランク付けを行い、定格動作と故障動作を区別する可能性が最も高い特徴を判定します。
データに状態変数またはラベルがない場合は、教師なしのランク付けを行い、他の特徴との最適なクラスタリングを示し、さまざまな故障状態または動作状態を示す可能性が最も高い特徴を判定します。
故障に至るまで実行されたデータから抽出された特徴を使用して予知ランク付けを行い、残存耐用期間 (RUL) を示す可能性が最も高い特徴を判定します。
特徴の効果について理解を深めアルゴリズムの学習に役立てるため、最も効果的な特徴を分類学習器または回帰学習器に直接エクスポートする。
MATLAB® 関数で特徴の計算を再現、カスタマイズ、自動化できるように、選択した特徴に対するコードを生成する。ストリーミング データをサポートするコードと Simulink® ブロックを生成することもできます。
アプリの使用を開始するには、MATLAB ワークスペースで使用できるシステムからのデータが必要です。アプリにインポートするデータの整理の詳細については、診断特徴デザイナー用のシステム データの整理を参照してください。
予知保全のための状態インジケーターの詳細については、監視、故障検出、予測のための状態インジケーターを参照してください。
診断特徴デザイナー アプリを開く
MATLAB ツールストリップ: [アプリ] タブの [制御システム設計と解析] で、アプリ アイコンをクリックします。
MATLAB コマンド プロンプト: 「
diagnosticFeatureDesigner」と入力します。
例
パラメーター
特徴デザイナー タブ
MATLAB ワークスペースからアプリにソース データをインポートして、新規のアプリ セッションを開始します。データは table、timetable、cell 配列、または行列からインポートできます。複数のアンサンブル メンバーのデータを組み合わせた単一のソースからデータをインポートしたり、個別のソースから個々のアンサンブル メンバーをインポートしたりできます。Signal Processing Toolbox™ で作成されたラベル付き信号セット、および Data Acquisition Toolbox™ のアナログ入力レコーダー (Data Acquisition Toolbox)を使用して記録された信号をインポートできます。また、アプリが外部のデータ ファイルを操作できるようにする情報の含まれた、アンサンブル データストアをインポートすることもできます。
ファイルには、実際の、またはシミュレートされた時間領域測定データ、スペクトル モデルまたはスペクトル table、変数名、状態変数と動作変数、および前に生成した特徴を含めることができます。診断特徴デザイナーはすべてのメンバー データを単一のアンサンブル データセットに組み合わせます。このデータセットでは各変数が、個々のメンバーの値をすべて含む集合的信号あるいは集合的モデルとなります。
データのインポートの詳細については、診断特徴デザイナーへのデータのインポートを参照してください。
データ アンサンブルに関する用語の詳細については、詳細を参照してください。
アプリにインポートするデータの整理の詳細については、診断特徴デザイナー用のシステム データの整理を参照してください。
[自動特徴] を使用して、特徴セットを自動的に生成してランク付けします。1 つ以上の信号またはスペクトルを選択すると、[自動特徴] は、変数の型に適切な事前定義された特徴セットを計算します。1 つ以上の特徴セットから選択できます。
標準 — 信号特徴、スペクトル特徴、一部の時間-周波数特徴を含むコアの特徴
詳細設定 — 残差信号やトレンド除去済みの時系列など、より複雑な計算を必要とする特徴
回転機 — 回転機向けの特殊な特徴
自動計算には以下が含まれます。
スペクトルや時系列信号などの特徴抽出に使用する中間変数の導出
展開された変数セットからの特徴抽出
特徴をランク付けし、上位ランクの特徴のヒストグラムをプロット。
詳細については、診断特徴デザイナーでの特徴の自動生成を参照してください。
アプリ セッション中に生成するすべてのプロットに対し、既定のプロット オプションを指定します。これらのオプションは、最初のプロットを生成する前でも、セッション中任意の時点でも設定することができます。新しい設定は、オプションの設定後に生成したプロットにのみ適用され、それ以前に生成したプロットには適用されません。個々のプロットに対する [プロット オプション] は、以降のプロットに対し指定された既定値を変更することなく一時的にオーバーライドできます。[プロット オプション] をクリックすると、以下のペインでオプションを設定できるダイアログ ボックスが開きます。
一般 — これらのオプションは、信号とスペクトルのすべてのプロットに適用されます。
グループ化 — データを状態変数のラベルによってグループ化します。アプリはラインの太さを使用してラベル グループを区別します。たとえば、状態変数が
healthyとdegradedのラベルをもつfaultCodeである場合、アプリはhealthyラベルをもつメンバー データにある太さを使用し、degradedラベルをもつメンバー データに別の太さを使用します。特定のラベル グループのメンバーを強調表示するには、プロットの凡例のラベルをクリックします。曲線数 — プロットするメンバーの数を指定します。アンサンブル メンバーの数が多く、メンバーのサブセットのみをプロットする場合は、このオプションを設定します。このオプションを使用するとプロット時間が短縮され、個々のメンバーの動作が評価しやすくなります。
スペクトル — これらのオプションはスペクトル プロットにのみ適用されます。
マークするピーク数 — マークするピークの数を指定します。最も重要なピークのみを強調表示するためにマークされるスペクトル ピークの数を制限するには、このオプションを設定します。
アンサンブル概要 — これらのオプションは、アンサンブル全体の平均と標準偏差を表示する特別なプロットである、アンサンブル概要のプロットのみに適用されます。
標準偏差の数 — アンサンブル概要のプロットで表示される標準偏差の数を指定します。
最小境界と最大境界を表示 — アンサンブルの実際の最小値と最大値の境界を表示するかどうかを指定します。
アンサンブル変数または特徴テーブルのプロットを生成します。プロットを生成するには、まず、データ ブラウザーから変数または特徴テーブルを選択します。プロット ギャラリーには、互換性のあるプロット タイプのアイコンが表示されます。次の表で、入力タイプ別のプロット タイプについて説明します。
| 入力タイプ | プロット タイプ | 説明 | カスタマイズできる場所 |
|---|---|---|---|
| 信号 | 信号トレース | 時間、または周波数を表さない別の独立変数によってプロットされたアンサンブル信号データ。 | [信号トレース] タブ |
| アンサンブル概要 | アンサンブル全体の平均値、標準偏差、最小/最大の境界。 | [アンサンブル概要] タブ | |
| スペクトル | パワー スペクトル | 周波数別にプロットされたアンサンブル信号強度。 | [パワー スペクトル] タブ |
| 次数スペクトル | 次数別にプロットされたアンサンブル信号強度。主回転周波数に対する特定の周波数の比率です。 | [次数スペクトル] タブ | |
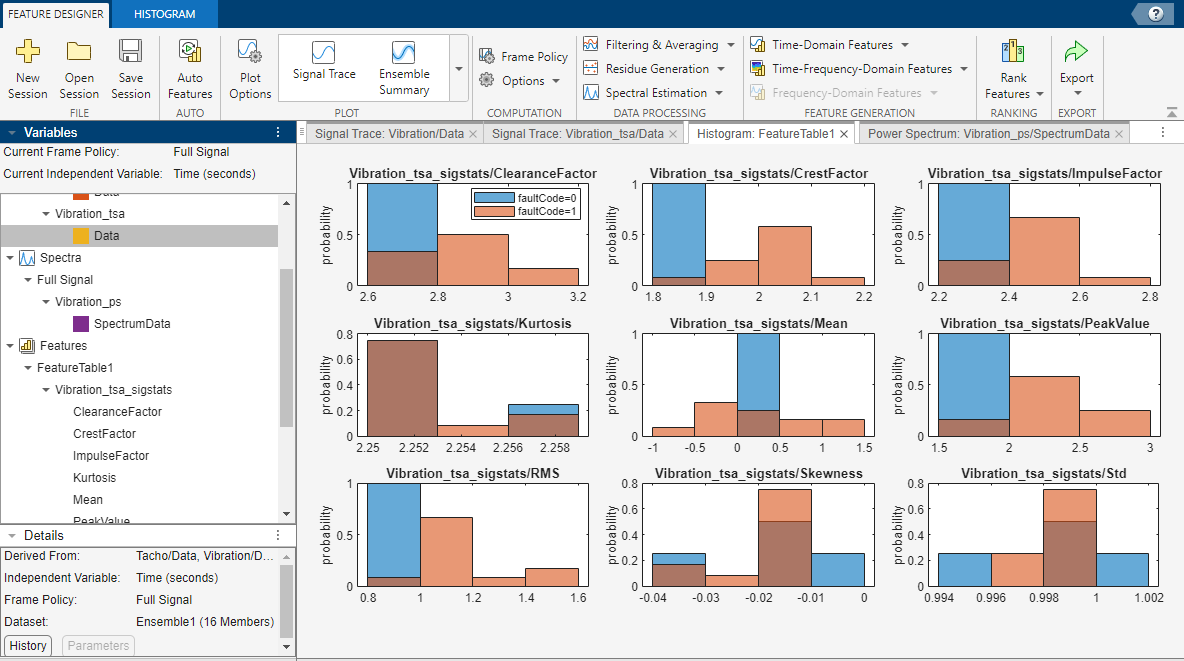
| 特徴テーブル | ヒストグラム | 状態ラベル別に色分けした棒グラフで可視化した、特徴の有効度。効果的な特徴は、状態を明確に分離します。 | |
| 特徴テーブル ビュー | 各アンサンブル メンバーの特徴値とその状態ラベルを含むテーブル。 | N/A | |
| 特徴トレース | 各メンバーの特徴値。このプロットは、フレームベースのデータから計算された予知特徴 (RUL の場合) に特に役立ちます。 | 特徴セレクター |
信号全体を一度にではなく、信号の連続したセグメントに対してデータ処理を実行する場合は、フレーム ポリシーを指定します。フレーム ポリシーは、フレーム サイズとフレーム レートで構成されています。フレーム サイズは、フレーム データを収集する間隔です。フレーム レートは、フレームの開始時間の間の時間間隔です。
フレームベースの処理の詳細については、データ処理モードおよびフレーム ポリシーを参照してください。
次の設定の一方または両方を変更する場合は、オプションを指定します。
独立変数の選択 — 使用する独立変数 (IV) の選択。データをインポートする際、信号に対して複数の独立変数を指定できます。たとえば、信号が時間ベースの場合、サンプル インデックスの独立変数も必要になる場合があります。インポートの完了後、アプリが特定のプロットまたは計算に使用する独立変数を変更できます。[オプション] 、 [独立変数の選択] の順に選択すると、利用可能な独立変数のリストが表示されます。選択することで、該当するすべての信号またはスペクトルの IV が変更されます。代替 IV の指定の詳細については、診断特徴デザイナーへのデータのインポートの「代替 IV としてのサンプル インデックスの指定」を参照してください。
並列計算の使用 — アンサンブル メンバーの並列処理。並列計算を使用すると、大規模なアンサンブルの処理時間を大幅に短縮できます。このオプションは、Parallel Computing Toolbox™ をインストールしてライセンスを取得している場合にのみ使用できます。
データを新しい信号またはスペクトルに処理するオプションを選択します。これらの新しい変数を、他の処理オプションへの入力、あるいは特徴生成への入力として使用します。ほとんどの処理オプションは、各アンサンブル メンバーで動作します。アンサンブルレベルの処理を実行して、アンサンブルの全体の動作状況を表示することもできます。オプションを選択するたびに、仕様の新しいタブが開きます。オプションを選択すると、一般的な [データ処理] タブがまだ開いていない場合は、そのタブも開きます。[データ処理] タブには、入力変数に関する情報が表示されます。
処理する信号またはスペクトルを指定するには、データ処理のオプションを選択する前に、[変数] ペインから変数を選択します。オプションのタブを開いた後に信号を変更するには、オプションのタブを閉じて、[変数] ペインまたは [データ処理] タブの [信号] リストから新しい信号を選択します。
[変数] ペインで、複数の互換性がある変数 (信号またはスペクトルなど、同じ型の変数) を選択することで、複数の変数に対して一度に同じ処理を実行できます。処理操作の選択後に、変数を追加することもできます。処理タブで、最初の変数の選択と互換性のあるすべての変数を一覧表示する、[その他の信号] または [その他のスペクトル] メニューから選択します。
処理パラメーターを設定した後、以下のいずれかを実行できます。
処理を直ちに実行する ([適用] をクリック)、または
実行を後回しにし、複数の操作を含むリストに追加して、後で一括処理する ([計算の追加] をクリック)。操作は独立していなければなりません。たとえば、信号からスペクトルを計算した後に、その新しいスペクトル上で周波数領域の操作を実行することはできません。
[データ処理の計算] パネルに、操作の名前が記録されます。処理リストが完成したら、[すべて適用] をクリックします。
類似した個別の計算リストを使用して、複数の操作によって特徴を処理できます。
処理オプションと各オプションに設定できるパラメーターの詳細については、次を参照してください。
フィルター処理と平均化
残差の生成
スペクトル推定
信号から特徴を抽出するためのオプションを選択します。オプションを選択するたびに、仕様の新しいタブが開きます。オプションを選択すると、より一般的でありながら、カテゴリに特化された特徴のタブも開きます (まだ開いていない場合)。このタブには、入力信号に関する情報が表示されます。
特徴を抽出する信号を指定するには、特徴のオプションを選択する前に、[変数] ペインから変数を選択します。オプションのタブを開いた後に信号を変更するには、オプションのタブを閉じて、[変数] ペインまたは [特徴] タブの [信号] リストから新しい信号を選択します。
特徴パラメーターを設定した後、以下のいずれかを実行できます。
抽出を直ちに実行する ([適用] をクリック)、または
実行を後回しにし、複数の操作を含むリストに追加して、後で一括処理する ([計算の追加] をクリック)。
[特徴抽出の計算] パネルには、操作の名前が記録されます。処理リストが完成したら、[すべて適用] をクリックします。
類似した個別の計算リストを使用すると、複数の操作によってデータを処理できます。
時間領域で特徴を計算します。[信号の特徴] は、すべての信号に適用されます。[時系列の特徴] は、定常時系列から抽出された特徴です。[モデルベースの特徴] は、自己回帰 (AR) モデルを使用して抽出された特徴です。[回転機の特徴] は、ギア装置に適用される特殊なメトリクスです。[非線形の特徴] は、振動信号での無秩序動作を特徴づけるメトリクスを提供します。[カスタム特徴] は、アプリにカスタム関数を追加して定義する特徴です。既存の MATLAB 関数を追加するか、テンプレートを使用して新しい関数を作成し、組み込みのアプリの特徴とともに特徴を生成してランク付けできます。
特徴の信号ソースを指定するには、時間領域の特徴のオプションを選択する前に、[変数] ペインから信号変数を選択します。オプションのタブを開いた後に信号を変更するには、オプションのタブを閉じて、[変数] ペインまたは [時間領域の特徴] タブの [信号] リストから新しい信号を選択します。
時間領域の特徴のオプションと、各オプションに設定できるパラメーターの詳細については、次を参照してください。
時間-周波数の特徴は、時間とともに周波数が変化する信号 (つまり非定常信号) を特徴付けます。そのような信号は、ハードウェアに劣化や故障がある機械から発生することがあります。アプリでは、時間-周波数の特徴のオプションが 2 つ用意されています。
スペクトログラムの特徴 — スペクトログラム解析に基づく特徴。このような特徴には、以下が含まれます。
[スペクトル尖度] メトリクス。信号の "スペクトル尖度" (SK) は、静的なガウス ノイズのみが存在する場合は小さい値を取り、過渡状態が発生する周波数ではより大きい正の値を取ります。この機能により SK は、回転機械システムの故障に関連する信号を検出および抽出するための強力なツールとなります。アプリでは、[クレスト ファクター]、[インパルス係数]、[クリアランス係数]、および [ピーク値] の各特徴を SK 信号から抽出できます。スペクトル尖度および [ウィンドウのサイズ] の設定の詳細については、
pkurtosisを参照してください。アプリで抽出される SK 信号のメトリクスの詳細については、信号の特徴の対応する定義を参照してください。[スペクトル エントロピー]。信号の "スペクトル エントロピー" (SE) は、時間の経過に伴って変化する、そのスペクトル パワー分布の尺度です。値の大きな変化は、故障を示す可能性があります。スペクトル エントロピーの詳細については、
pentropyを参照してください。
EMD の特徴 — 経験的モード分解 (EMD) に基づく特徴。信号の "経験的モード分解" は、信号の周波数成分の予測不可能性についてのランダム性の尺度です。値の増加は、故障の存在を示す可能性があります。アプリでは、[クレスト ファクター]、[インパルス係数]、[クリアランス係数]、[ピーク値]、および [エネルギー] の各特徴を、EMD 計算により作成される IMF 信号から抽出できます。経験的モード分解、および [IMF の数] の設定の詳細については、
emdを参照してください。アプリで抽出される EMD のメトリクスの詳細については、信号の特徴の対応する定義を参照してください。
特徴の信号ソースを指定するには、時間-周波数領域の特徴のオプションを選択する前に、[変数] ペインから信号変数を選択します。オプションのタブを開いた後に信号を変更するには、オプションのタブを閉じて、[変数] ペインまたは [時間-周波数領域の特徴] タブの [信号] メニューから新しい信号を選択します。
周波数領域で特徴を計算します。[スペクトルの特徴] は、指定された周波数範囲全体にわたるピーク振幅など、すべてのスペクトルに適用される一般的なメトリクスです。[ベアリングの故障の特徴]、[ギアの噛み合いの故障の特徴]、および [カスタムの故障の特徴] は、システム コンポーネントの、故障が起こり得る特性周波数の範囲を満たす特定の故障帯域内のスペクトル動作に焦点を当てた、回転機に特化したメトリクスです。[カスタム特徴] は、アプリにカスタム関数を追加して定義する特徴です。既存の MATLAB 関数を追加するか、テンプレートを使用して新しい関数を作成し、組み込みのアプリの特徴とともに特徴を生成してランク付けできます。
周波数領域の特徴の詳細については、次を参照してください。
[特徴のランク付け] タブを開き、選択した特徴テーブルに、教師ありのランク付け、教師なしのランク付け、予知ランク付けのいずれかを実行します。詳細については、特徴のランク付けタブを参照してください。
特徴またはデータ セット全体をエクスポートして、それらを使用するか、アプリの外部で共有します。MATLAB 関数または Simulink ブロックで特徴計算を再現するコードを生成します。
特徴をエクスポートする場合、どちらのオプションでも特徴のリストが開きます。
まだ特徴をランク付けしていない場合、このリストは名前で並べ替えられ、既定ではエクスポートによってすべての特徴がマークされます。特定の特徴のみをエクスポートする場合には、選択を絞り込むことができます。
特徴を既にランク付けした場合、このリストは特徴のランク付けタブの [並べ替え] の指定に従って並べ替えられます。[上位の特徴の選択] を使用すると、指定した特徴の数に基づき、最もランクの高い特徴のみがエクスポートされます。[特徴の並べ替え基準] リストで
[名前]を選択すると、並べ替え順序をアルファベット順に変更できます。どちらの並べ替え順序でも、エクスポートする特徴を個別に選択または選択解除できます。
MATLAB ワークスペースにエクスポートする場合、特徴にコマンド ライン手法を使用できます。分類学習器または回帰学習器にエクスポートする場合、選択した特徴を入力として使用する新しい機械学習セッションを開きます。
コード生成の場合、最初のオプション
[特徴の関数の生成]を使用すると、特徴テーブル、ランク付けアルゴリズム、特徴数の単純な仕様セットを使用して MATLAB コードを生成できます。ランク付けのみに基づいて特徴のコードを生成する場合や、すべての特徴のコードを生成する場合は、このオプションを使用します。[データのストリーミング形式] を選択すると、MATLAB Coder™ と互換性があり、ストリーミング データ アプリケーションをサポートする関数がアプリで生成されます。
2 番目のコード生成オプション
[次の関数を生成...]を使用すると、関数に含める項目の選択をカスタマイズできます。たとえば、入力テキストや出力テキストなどの基準に基づいて、選択内容をフィルター処理できます。選択した特徴で使用されていない信号とスペクトルを含めることができます。[次の関数を生成...]を選択すると、生成したすべての信号、特徴、およびランク付けの table を選択できるリストが開きます。また、[次の関数を生成...]を選択すると、[コード生成] タブも開き、リストをフィルター処理できます。フィルターを使用して、フィルター基準を満たす項目のみを表示します。さまざまなフィルターを使用して、必要な出力を選択できます。フィルターに関係なくすべての選択項目を確認するには、[選択した項目で並べ替え] をクリックします。このオプションは、利用可能なすべての出力のリストを表示し、選択した項目を一番上に表示します。詳細については、コードの生成タブ を参照してください。フレームベースのデータを指定した場合 (オプション を参照)、
[次の関数を生成...]をクリックすると、まず、使用したフレーム仕様の選択リストが開きます。生成されたコード内の項目は、すべてが完全な信号で動作するか、すべてが同じフレーム仕様を使用する必要があります。最後のオプションの
[特徴抽出 Simulink ブロックの生成]を使用すると、[特徴の関数の生成]で生成する同じストリーミング形式のコードを組み込んだ Simulink がエクスポートされます。アプリでコードまたは Simulink を生成する方法の詳細については、MATLAB の生成コードを使用した自動特徴抽出、診断特徴デザイナーでの MATLAB 関数の生成、およびデータをストリーミングするための特徴抽出関数と Simulink モデルのエクスポートを参照してください。
[エクスポート] オプションの詳細については、次を参照してください。
信号トレース タブ、アンサンブル概要タブ、パワー スペクトル タブ、および、次数スペクトル プロット タブ
[パナー] を使用して、指定した "x" 軸の範囲のデータ セグメントに焦点を絞り、プロット スケールを変更します。[パナー] は、メイン プロットの下にストリップ プロットを提供します。メイン プロットのセクションに焦点を絞るには、ハンドルを動かします。プロットのスケールを変更するには、[スケール] でオプションの 1 つを選択します。
[ビュー] セクションの最初の列のオプションを使用して、[プロット オプション] 仕様の既定値をオーバーライドします。利用可能なオプションは、プロット タイプによって異なります。たとえば、[曲線数] は信号トレースとスペクトル プロットの両方に使用できるオプションであり、[マークするピーク数] はスペクトル プロットのみに使用できるオプションです。
プロット タブでこれらの設定を変更すると、現在のプロットに対してのみ変更されます。これらのオプションの詳細については、プロット オプションを参照してください。
複数の変数のプロットの実行中に、変数を同じ [-1, 1] スケールで表示する場合は、[Y 軸の正規化] を使用します。変数内の相対的な信号振幅は変化しません。
信号プロットまたはスペクトル プロットでは、カーソルをメンバー トレースに合わせると、個々のメンバーが強調表示されます。[信号情報の表示] を選択すると、強調表示した変数メンバーとそのメンバーの状態ラベルの両方が右下隅に表示されます。
[データ カーソル] を選択すると、[信号情報の表示] で 2 つのカーソル間の距離も表示されます。詳細については、データ カーソル を参照してください。
複数の変数を一緒にプロットする方法を指定します。
すべてのトレースを重ね合わせ、単一の "y" 軸スケールを使用する単一のプロットを作成する場合は、オンにします。
それぞれが固有の "y" 軸スケーリングで垂直に表示される個別のプロットを作成する場合は、オフにします。
[データ カーソル] を選択して、信号の重要な点の値を表示します。[データ カーソル] は、ピーク値など、対象とする点の上に重ねて表示する水平バーと垂直バーです。カーソルは x 位置と y 位置を表示します。カーソル間の距離を表示するには、[信号情報の表示] を選択します。バーが一緒に動くようにロックするには、間隔をロックするオプションのいずれかを選択します。
ヒストグラム タブ
[特徴の選択] をクリックして、プロットする特徴を選択できるリストを開きます。たとえば、生成した多数の特徴の中から、単一のプロット パネルのサブセットに絞り込む場合は、[特徴の選択] を使用します。
特徴の選択の詳細については、特徴セレクターを参照してください。
特徴ヒストグラムのベースとなる状態変数を選択します。特徴ヒストグラムは、その状態変数に対して異なるラベルをもつデータ グループの分離を色で可視化します。
例: faultCode
[ビンの幅]、[ビン化方法]、[ビンの数]、および [ビンの範囲] を使用して、ヒストグラム分解能を指定します。ビンの設定は特徴テーブルのすべてのヒストグラムに適用されます。
ビンの設定は独立していません。アプリのヒストグラム アルゴリズムは、優先順位を利用して、何を使用するかを決定します。
既定では [ビン化方法] の指定がビンの幅を決定する。
[ビンの幅] の指定が、指定された [ビン化方法] をオーバーライドする。
ビンの幅および独立した [ビンの範囲] がビンの数を決定する。[ビンの数] の指定は、[グループ化] の値が
[なし]の場合にのみ有効です。[正規化] の指定が "y" 軸の表すものを決定する。既定では、ヒストグラムは "y" 軸に確率を使用し、対応する範囲をすべての特徴について 0 ~ 1 とします。複数のヒストグラムを同じスケールで表示すると、視覚的に比較しやすくなります。他の軸設定は [正規化] メニューから選択します。これらの方式には生のカウント数や CDF などの統計メトリクスが含まれます。
ヒストグラムの解釈とカスタマイズの詳細については、特徴のヒストグラムの生成とカスタマイズを参照してください。
特徴のランク付けタブ
各特徴が健全な動作と不健全な動作または劣化の動作を区別するのにどの程度効果的であるかを評価するための教師ありのランク付け手法を選択します。診断特徴デザイナーには、分類と回帰の両方の用途向けのランク付け手法が用意されています。
分類のランク付け: 異なる条件ラベルをもつデータをどの程度うまく分離するかについて各特徴をランク付けします。
回帰のランク付け: 数値応答データをうまく予測するかについて各特徴をランク付けします。
メニューには、2 クラスのランク付け手法と複数クラス/回帰のランク付け手法の 2 つの主要セクションがあります。
2 クラスの手法 — 状態変数 (CV) のラベルが 2 つだけ (
“healthy”と“faulty”、または0と1など) の場合は 2 クラスの手法を使用します。2 クラスの手法の既定値は[T 検定]です。複数クラスおよび回帰の手法
状態変数のラベルが 3 つ以上 (
“healthy”、“faultCode1”、“faultCode2”、または0、1、2など) の場合は複数クラスの手法を使用します。複数クラスの手法の既定のランク付けは[1 因子 ANOVA]です。複数クラスの手法は 2 クラスの用途にも使用できます。状態変数に数値応答データが含まれている場合は回帰の手法を使用します。既定の手法は
[MRMR]です。これらの回帰のランク付け手法は分類のランク付けにも使用できます。
CV の内容を使用して、適用できる可能性が高いランク付けのタイプ (分類または回帰) がアプリで判別されます。ただし、条件ラベルまたは応答値を含む場合がある数値データについては、このタブでランク付けのタイプを変更できます。
次の表は、ランク付けの選択肢をまとめたものです。
| ランク付けのタイプ* | メソッド | 基準 | リンク |
|---|---|---|---|
| 2 クラスの分類 | T 検定 | 平均差 | ttest2 |
| エントロピー | 相対エントロピー | relativeEntropy | |
| バタチャリア | 達成可能な分類誤差 | bhattacharyyaDistance | |
| ROC | ROC 曲線とランダムな分類器の傾きの間の面積 | perfcurve | |
| ウィルコクソン | ウィルコクソン検定の結果 | ranksum | |
| 複数クラスの分類 | 1 因子 ANOVA | 1 因子分散分析 | anova1 |
| クラスカル・ワリス | クラスカル・ワリス検定のカイ二乗統計量 | kruskalwallis | |
| 回帰 | MRMR | Minimum Redundancy Maximum Relevance アルゴリズム | fsrmrmr または fscmrmr |
| ReliefF | ReliefF (分類) または RReliefF (回帰) アルゴリズム | relieff | |
| *この表にある複数クラスの分類の手法は 2 クラスの分類にも使用できます。同様に、回帰の手法はいずれの分類タイプにも使用できます。 | |||
手法を選択すると、そのランク付け手法と一致する名前の新しいタブがアクティブになります。手法を選択してアクティブになったタブの詳細については、ランク付け手法タブを参照してください。
既に特徴をランク付けしている場合は、それらを別の手法で再度ランク付けし、得られたランクをまとめて表示できます。
教師なし分類のランク付け手法を選択すると、ラベル付けされたデータがない場合に各特徴がどの程度効果的に機能するかを評価できます。教師なしのランク付けには 2 つのオプションが用意されています。
ラプラシアン スコア — スコアは、特徴が他の特徴とどの程度密集して明確なグループを形成しているかを反映します。
分散 — スコアは特徴の分散を反映します。分散が小さい特徴には、モデルに追加できる有用な情報が少ないという傾向があります。
手法を選択すると、そのランク付け手法と一致する名前の新しいタブがアクティブになります。このタブの詳細については、ランク付け手法タブを参照してください。
教師なしのランク付けスコアリングの詳細については、以下を参照してください。
ラプラシアン —
fsulaplacian分散 —
var
教師なしランク付けは、診断特徴デザイナーでは利用できますが、分類学習器では利用できません。特徴を分類学習器にエクスポートしてモデルに学習させる場合は、ラベルを含むアンサンブル データを使用する必要があります。
予知ランク付け手法を選択すると、故障に至るまで実行されたデータがある場合に、各特徴がアンサンブル メンバーの劣化をどの程度効果的に追跡するかを評価できます。上位ランクの特徴は、残存耐用期間 (RUL) の予測に最適です。
アプリには 3 つの予知ランク付け手法が用意されており、いずれも 0 ~ 1 までのスケールで特徴をスコアリングします。[単調性] は常に使用できます。それ以外の [トレンド可能性] と [予知可能性] の 2 つの手法は、フレームベースのデータを使用している場合にのみ使用できます。フレームベースのデータではデータ セグメントが小さいため、劣化によって引き起こされる小さな変化を追跡できます。
"単調性" は、システムが故障に近づく際に特徴のトレンドがもつ特性。システムが徐々に故障に近づくにつれ、適切な状態インジケーターは単調増加または単調減少のトレンドをもちます。詳細については、
monotonicityを参照してください。"トレンド可能性" は、故障に至るまで実行された複数の実験で測定された、特徴の軌跡間に見られる類似性の尺度。状態インジケーター候補のトレンド可能性は、測定値間の最小絶対相関として定義されます。詳細については、
trendabilityを参照してください。"予知可能性" は、故障時の特徴の変動性を、その初期値と最終値間の範囲と比較した尺度。予知可能性の高い特徴は、その初期値と最終値間の範囲と比較して故障時の変動が小さくなります。詳細については、
prognosabilityを参照してください。
手法を選択すると、そのランク付け手法と一致する名前の新しいタブがアクティブになります。手法を選択してアクティブになったタブの詳細については、ランク付け手法のタブを参照してください。
アプリでの予知ランク付けの使用例については、診断特徴デザイナーを使用した劣化システムの特徴の予知ランク付けを参照してください。
使用するランク付けアルゴリズムのラベルを提供する状態変数を選択します。
各ランク付け手法の結果を比較する場合に、並べ替えるランク付け手法を指定します。1 つのランク付け手法を使用すると、アプリはその手法のランク付けスコアで示される重要度の順に結果を表示します。複数の手法の結果を比較する場合は、[並べ替え] を変更して、並べ替え順序を切り替える手法を変更します。
次のいずれかの削除操作を実行するために、これらのパラメーターを指定します。[ランク付け手法] または [次より下位ランクの特徴] の選択により、アプリでどちらの操作を実行するかを決定します。
ランク付け手法からスコアを削除 — [ランク付け手法] を選択し、ランク付けの table から削除するランク付け手法を指定した後で、[削除] をクリックします。たとえば、複数のランク付けの結果を比較する際に、特徴の選択に影響しないランク付けを除外して表示を簡略化する場合に、このパラメーターを使用します。
ランクの低い特徴をアプリから削除 — [ランク付け手法] で指定されたランク付け手法について、指定ランクより低いすべての特徴を削除するには、[次より下位ランクの特徴] を選択した後で、[削除] をクリックします。たとえば、20 個の特徴があり、指定したランク付け手法に従って上位 5 個の特徴のみを保持する場合、[次より下位ランクの特徴] を 5 に設定します。アプリにより、最も低い 15 個の特徴が削除されます。
ランク付けの基準となる手法を変更するには、まず [ランク付け手法] を選択して手法を指定した後で、[次より下位ランクの特徴] を選択します。メソッドを除去するのではなく特徴を削除するには、[次より下位ランクの特徴] を選択して [削除] しなければなりません。
特徴をエクスポートして、それらを使用するか、アプリの外部で共有します。MATLAB 関数または Simulink ブロックで特徴計算を再現するコードを生成します。
どちらのオプションでも、ランク付けで並べ替えた選択可能なリストを開いて選択できます。MATLAB ワークスペースにエクスポートする場合、特徴にコマンド ライン手法を使用できます。分類学習器または回帰学習器にエクスポートする場合、選択した特徴を入力として使用する機械学習セッションを開きます。
アプリからデータ セット全体をエクスポートする場合は、[特徴デザイナー] タブから [エクスポート] を使用します。
また、選択した変数と特徴の計算を再現するコードまたは Simulink ブロックを生成することもできます。[特徴のランク付け] タブから [特徴の関数の生成] を使用してコードを生成すると、ランク付け手法の既定値は [並べ替え] で指定した手法になります。コード生成の詳細については、[特徴デザイナー] タブのエクスポートのセクションに記載されているコード生成オプションの説明を参照してください。
ランク付け手法タブ
相関の重要度の設定により、類似した情報をより高いランクの特徴に伝達する特徴を除外できます。このスクリーニングにより、上位ランクの特徴が多様になります。
スクリーニングの基準は、特徴が上位ランクの特徴との間でもつ一連の相互相関係数です。2 つの特徴間で相互相関が高いということは、どちらの特徴も同じように条件グループを分離しており、冗長な情報を提供していることを意味します。既定値の 0 を使用すると、アプリは特徴の冗長性をランク付けスコアに組み込みません。相関の重要度の値を大きくすると、特徴の相互相関が特徴のランク付けスコアに与える影響が大きくなります。このように影響度が大きくなることで、冗長な特徴のスコアが徐々に低下します。
正規化の方式は、各特徴のメンバー全体で独立した正規化を実行します。正規化により、より直接的に特徴を比較できます。選択した方式の定義式は、選択した方式の直下に表示されます。
このオプションは、教師ありのランク付けとラプラシアン スコアによる教師なしのランク付けでのみ使用できます。
状態変数タイプ (CV) が数値である場合に、分類の手法と回帰の手法のどちらについて特徴をランク付けするのかを指定します。分類か回帰かの選択は CV の内容に基づいてアプリで初期化されますが、その選択が正しくない場合に切り替えることができます。
このオプションは、MRMR と ReliefF のランク付けオプションでのみ使用できます。
ラプラシアン スコアを計算するためのキー値を定義するパラメーターを指定します。ラプラシアン スコアは、特定の特徴が他の特徴とどの程度密集しているかを示します。ラプラシアン スコアは、特定の特徴から最近傍の特徴までのペアワイズ距離に基づきます。
近傍の数 — スコアの計算に使用する最近傍の数
距離計量 —
[euclidean]や[cityblock]など、各ペアワイズ距離の計算方法カーネル スケール — ペアワイズ距離をスコアを提供する "類似性グラフ" に変換するカーネルのスケール係数
このオプションは、ラプラシアン スコアによる教師なしのランク付けでのみ使用できます。ラプラシアン スコアによるランク付けの詳細については、fsulaplacian を参照してください。
[適用] をクリックして、指定されたパラメーターでランク付けを計算します。プロット領域の [特徴のランク付け] タブには、結果がグラフと表形式の両方で表示されます。この表示には、既定のランク付けアルゴリズムの結果と、それまでに計算したその他のランク付け手法の結果も含まれます。
ランク付けを計算すると、パラメーターを変更するまで、[適用] は無効になります。タブ内でランク付けは複数回計算できます。パラメーターを変更してランク付けを計算するたびに、新しい結果がプロット領域タブの以前の結果を上書きします。
ランク付け手法のタブ内でランク付けが完了したら、そのタブを閉じてコントロールを [特徴のランク付け] タブに戻します。ランク付け手法のタブがアクティブになっている間は、[特徴のランク付け] は無効になります。
コードの生成タブ
この パラメーター は読み取り専用です。
フレーム ポリシー情報は、[特徴デザイナー] タブで [エクスポート]、[次の関数を生成...] を選択したときに行った選択を反映します。
生成された関数の項目を選択する際に、オプションを絞り込む基準を設定します。すべての基準で、選択可能なオプションを string で上書きできます。string のマッチングでは大文字と小文字が区別されません。フィルターは、信号、特徴、ランク付けの table など、すべての出力項目に適用されます。基準には、以下が含まれます。
出力 — 生成された関数用に選択する変数、特徴、またはランク付けの table の名前など、出力名に表示される string
入力 — 出力変数または特徴が計算された入力信号、またはランク付けの table が計算された特徴テーブル
手法 —
TSAやKurtosisなどの出力項目を生成した計算解析タイプ — データ処理、特徴処理、または特徴のランク付け
フィルターを 1 つだけリセットするには、コンテンツを削除し、アプリ内の任意の場所をクリックします。すべてのフィルターを一度にリセットするには、[フィルターのリセット] をクリックします。
選択したすべての項目をまとめて表示します。複数のフィルターを組み合わせて codegen の選択を組み立てた場合は特に、[選択した項目で並べ替え] を使用します。すべての選択がまとめて表示されます。
生成されたコードで並列計算を使用するかどうかを指定します。既定値はオプションで指定した値です。並列計算を使用せずに対話型処理を行った場合でも、並列計算を指定できます。この方法により、生成されたコードを特徴の開発に使用したアンサンブルよりも大きなアンサンブルで実行する予定がある場合に、コードがよりスケーラブルになります。特徴の開発時に並列計算を使用した場合は、並列計算をオフにすることもできます。
生成されたコードで並列処理を利用するには、Parallel Computing Toolbox をインストールしてライセンスを取得する必要があります。ただし、ツールボックスがないシステムでは、コードはシリアル モードで実行されます。
選択の構成が完了したら、[関数の生成] ボタンをクリックします。選択したすべての出力項目に使用される計算を含む関数が開きます。
アプリでのコード生成の詳細については、MATLAB の生成コードを使用した自動特徴抽出を参照してください。
プログラムでの使用
diagnosticFeatureDesigner が診断特徴デザイナー アプリを開きます。
diagnosticFeatureDesigner( がアプリを開き、以前に保存したセッションを読み込みます。sessionFile)sessionFile は、MATLAB パス上のセッション データ ファイルの名前です。データには、アプリにインポートしたか、アプリ内で計算したすべての変数と特徴が含まれます。データには、アプリの設定と、コードの生成に必要な処理情報も含まれます。
そのためには、診断特徴デザイナー アプリの [特徴デザイナー] タブで  [セッションの保存] をクリックします。
[セッションの保存] をクリックします。
diagnosticFeatureDesigner( がアプリを開き、有効性チェックを実行した後、ソースとして dataset)dataset のデータがあらかじめ選択された状態で、自動的に [新規セッション] ダイアログ ボックスが開きます。
詳細
"データ アンサンブル" は、さまざまな状態下でシステムを測定またはシミュレートすることによって作成されたデータ セットのコレクションです。アンサンブルは、行列や table などの独立したデータ セットを使用して実装することも、"アンサンブル table" などの単一の集合データ セットで実装することもできます。
データ アンサンブルと変数の詳細については、状態監視と予知保全のためのデータ アンサンブルを参照してください。
アンサンブル内の各データ セットは "メンバー" です。アンサンブルのメンバーにはすべて、同じ "変数" が含まれています。たとえば、アンサンブルに一連の類似マシンからのデータが含まれている場合、それらのマシンの 1 つに対応するデータ セットがメンバーになります。
アンサンブル table は、table としてフォーマットされたアンサンブル データ セットです。table の各列は 1 つの変数を表します。table の各行は 1 つのアンサンブル メンバーを表します。メンバー行列をアンサンブル table に変換する方法については、診断特徴デザイナー用の行列データの準備を参照してください。
大規模なアンサンブルは、"アンサンブル データストア オブジェクト" を使用して実装できます。これらのオブジェクトには、メンバー ファイルのリストと、それらを操作するための情報が含まれています。アンサンブル データストア オブジェクトの詳細については、状態監視と予知保全のためのデータ アンサンブルを参照してください。
"データ変数" は、アンサンブルの主な内容を構成しており、予知保全アルゴリズムの解析と開発に使用する測定データと派生データを含みます。たとえば、加速度計のデータをデータ変数 Vibration として表すことができます。データ変数は、信号の平均値や信号スペクトルのピーク振幅の周波数など、派生値を含むこともあります。
"独立変数" (IV) は、アンサンブル内のメンバーの特定や順序付けをする変数であり、タイムスタンプ、操作時間数、マシン ID などを含みます。たとえば、Time は一般的な独立変数です。
"状態変数" (CV) は、アンサンブル メンバーの故障状態または動作状態を記述する変数です。状態変数は故障状態の有無や、周囲温度のような他の動作状態を記録できます。多くの場合、状態変数には、"ラベル" によって記述される特定の可能な値があります。たとえば、Health という名前の状態変数には、Healthy と Degraded というラベルで記述された 2 つの状態が存在する場合があります。状態変数は、複数の故障状態および動作状態をエンコードする 1 つのスカラー値など、派生値をとる場合もあります。
バージョン履歴
R2019a で導入
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
Web サイトの選択
Web サイトを選択すると、翻訳されたコンテンツにアクセスし、地域のイベントやサービスを確認できます。現在の位置情報に基づき、次のサイトの選択を推奨します:
また、以下のリストから Web サイトを選択することもできます。
最適なサイトパフォーマンスの取得方法
中国のサイト (中国語または英語) を選択することで、最適なサイトパフォーマンスが得られます。その他の国の MathWorks のサイトは、お客様の地域からのアクセスが最適化されていません。
南北アメリカ
- América Latina (Español)
- Canada (English)
- United States (English)
ヨーロッパ
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)