kruskalwallis
クラスカル・ワリス検定
構文
説明
p = kruskalwallis(x)x の各列のデータが同じ分布から派生しているという帰無仮説についての p 値を返します。対立仮説は、すべての標本が同じ分布から派生しているとは限らないとします。クラスカル・ワリス検定は、1 因子 ANOVA のノンパラメトリックな別バージョンを提供します。詳細については、クラスカル・ワリス検定を参照してください。
p = kruskalwallis(x,group,displayopt)
例
2 つの異なる正規確率分布オブジェクトを作成します。1 番目の分布は mu = 0 および sigma = 1 にします。2 番目の分布は mu = 2 および sigma = 1 にします。
pd1 = makedist('Normal'); pd2 = makedist('Normal','mu',2,'sigma',1);
これらの 2 つの分布から乱数を生成して標本データの行列を作成します。
rng('default'); % for reproducibility x = [random(pd1,20,2),random(pd2,20,1)];
最初の分布から生成されたデータを x の最初の 2 列に格納し、2 番目の分布から生成されたデータを 3 列目に格納します。
x の各列の標本データが同じ分布から派生しているという帰無仮説を検定します。
p = kruskalwallis(x)

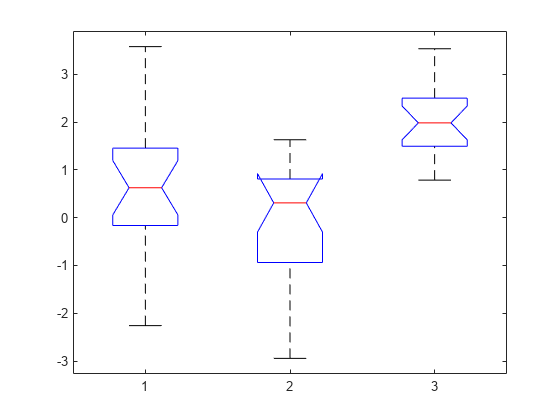
p = 3.6896e-06
p の戻り値は、kruskalwallis が有意水準 1% で 3 つすべてのデータ標本が同じ分布から派生しているという帰無仮説を棄却することを示します。追加の検定結果を示す ANOVA 表と、x の各列の要約統計量を視覚的に示す箱ひげ図が表示されます。
2 つの異なる正規確率分布オブジェクトを作成します。1 番目の分布は mu = 0 および sigma = 1 にします。2 番目の分布は mu = 2 および sigma = 1 にします。
pd1 = makedist('Normal'); pd2 = makedist('Normal','mu',2,'sigma',1);
これらの 2 つの分布から乱数を生成して標本データの行列を作成します。
rng('default'); % for reproducibility x = [random(pd1,20,2),random(pd2,20,1)];
最初の分布から生成されたデータを x の最初の 2 列に格納し、2 番目の分布から生成されたデータを 3 列目に格納します。
x の各列の標本データが同じ分布から派生しているという帰無仮説を検定します。出力は非表示にし、追加の検定で使用する stats 構造体を生成します。
[p,tbl,stats] = kruskalwallis(x,[],'off')p = 3.6896e-06
tbl=4×6 cell array
{'Source' } {'SS' } {'df'} {'MS' } {'Chi-sq' } {'Prob>Chi-sq'}
{'Columns'} {[7.6311e+03]} {[ 2]} {[3.8155e+03]} {[ 25.0200]} {[ 3.6896e-06]}
{'Error' } {[1.0364e+04]} {[57]} {[ 181.8228]} {0×0 double} {0×0 double }
{'Total' } {[ 17995]} {[59]} {0×0 double } {0×0 double} {0×0 double }
stats = struct with fields:
gnames: [3×1 char]
n: [20 20 20]
source: 'kruskalwallis'
meanranks: [26.7500 18.9500 45.8000]
sumt: 0
p の戻り値は、有意水準 1% で帰無仮説を棄却することを示します。stats 構造体を使用して補足の検定を実行できます。cell 配列 tbl に、グラフィカルな ANOVA 表 (列と行のラベルを含む) と同じデータが含まれています。
別の分布から派生しているデータ標本を識別するための補足の検定を実行します。
c = multcompare(stats);
Note: Intervals can be used for testing but are not simultaneous confidence intervals.
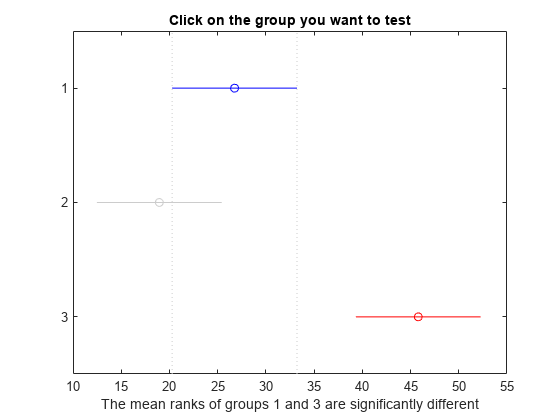
多重比較の結果を table で表示します。
tbl = array2table(c,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"])
tbl=3×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
_______ _______ ___________ ______ ___________ __________
1 2 -5.1435 7.8 20.744 0.33446
1 3 -31.994 -19.05 -6.1065 0.0016282
2 3 -39.794 -26.85 -13.906 3.4768e-06
結果的に、グループ 1 とグループ 3 の間には有意差が認められたため、それらの 2 つのグループが同じ分布から派生しているという帰無仮説は棄却されます。同じことがグループ 2 および 3 についても成り立ちます。しかし、グループ 1 および 2 の間には有意な差がないので、この 2 つのグループが同じ分布に由来しているという帰無仮説は棄却されません。したがって、これらの結果から、グループ 1 とグループ 2 のデータが同じ分布から派生し、グループ 3 のデータは別の分布から派生していると考えられます。
金属梁の強度の測定値を含む strength というベクトルと、対応する梁の原料である合金の種類を示す alloy というベクトルを作成します。
strength = [82 86 79 83 84 85 86 87 74 82 ... 78 75 76 77 79 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'};
梁の強度の測定値の分布が 3 つのいずれの金属合金でも同じになるという帰無仮説を検定します。
p = kruskalwallis(strength,alloy,'off')p = 0.0018
p の戻り値は、有意水準 1% で帰無仮説を棄却することを示します。
入力引数
出力引数
詳細
バージョン履歴
R2006a より前に導入