friedman
フリードマン検定
構文
説明
p = friedman(x,reps,displayopt)displayopt が 'on' (既定値) の場合は表示、displayopt が 'off' の場合は非表示になる ANOVA 表の表示を有効にします。
例
この例では、フリードマン検定を使用して二元配置における列効果を検定する方法を示します。
標本データを読み込みます。
load popcorn
popcornpopcorn = 6×3
5.5000 4.5000 3.5000
5.5000 4.5000 4.0000
6.0000 4.0000 3.0000
6.5000 5.0000 4.0000
7.0000 5.5000 5.0000
7.0000 5.0000 4.5000
これは、ポップコーンのブランドと製造器具タイプの研究 (Hogg 1987) のデータです。行列 popcorn の列はブランド (Gourmet、National、および Generic) を示しています。行は製造器具のタイプです (Oil と Air)。この研究では、それぞれの製造器具で、それぞれのブランドのポップコーンを 3 回ずつ作りました。値は、ポップコーンの生産量をカップ単位で示しています。
フリードマン検定を使用して、ポップコーンのブランドがポップコーンの生産量に影響するかどうかを判定します。
p = friedman(popcorn,3)
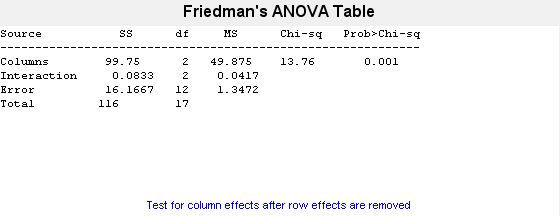
p = 0.0010
p = 0.001 という小さい値は、ポップコーンのブランドがポップコーンの生産量に影響することを示します。
入力引数
出力引数
詳細
参照
[1] Hogg, R. V., and J. Ledolter. Engineering Statistics. New York: MacMillan, 1987.
[2] Hollander, M., and D. A. Wolfe. Nonparametric Statistical Methods. Hoboken, NJ: John Wiley & Sons, Inc., 1999.
バージョン履歴
R2006a より前に導入