multcompare
多重比較検定
構文
説明
c = multcompare(stats,Name,Value)
例
carsmall データ セットを読み込みます。
load carsmallデータには、さまざまな車種およびモデルのガロンあたりの走行マイル数 (MPG) の測定値が格納され、生産国 (Origin) およびその他の車両の特性によってグループ化されています。
1 因子分散分析 (ANOVA) を実行し、自動車の MPG 値が生産国によって異なるかどうかを確認します。
[p,t,stats] = anova1(MPG,Origin);
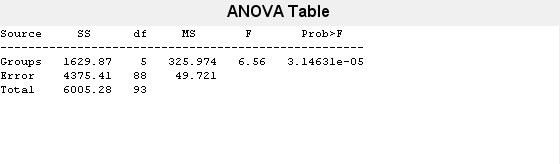
"p" 値 (列 Prob>F の値) が小さいので、グループ平均には有意な違いがあることがわかります。ただし、どのグループが異なる平均値をもつかは ANOVA の結果からはわかりません。多重比較検定を使用して一対比較を実行すると、有意に異なる平均値をもつグループを特定できます。
グループ平均の多重比較検定を実行します。
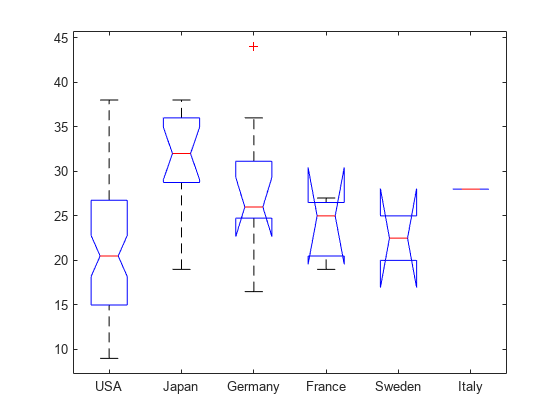
[c,m,h,gnames] = multcompare(stats);
multcompare は推定値とその周辺の比較間隔を表示します。任意の国のグラフをクリックすると、その国の平均を他の国の平均と比較できます。
平均の推定値、標準誤差、および該当するグループ名を table で表示します。
tbl = array2table(m,"RowNames",gnames, ... "VariableNames",["Mean","Standard Error"])
tbl=6×2 table
Mean Standard Error
______ ______________
USA 21.133 0.88141
Japan 31.8 1.8206
Germany 28.444 2.3504
France 23.667 4.0711
Sweden 22.5 4.986
Italy 28 7.0513
ダネットの検定を使用して制御グループに対して多重比較検定を実行し、その結果をテューキーの HSD 法による一対比較の結果と比較します。
carsmall データ セットを読み込みます。
load carsmallデータには、さまざまな車種およびモデルのガロンあたりの走行マイル数 (MPG) の測定値が格納され、生産国 (Origin) およびその他の車両の特性によってグループ化されています。
1 因子 ANOVA を実行し、生産国によって定義されたグループ間で自動車の燃費を比較します。
[~,~,stats] = anova1(MPG,Origin,"off");グループの名前を表示します。
stats.gnames
ans = 6×1 cell
{'USA' }
{'Japan' }
{'Germany'}
{'France' }
{'Sweden' }
{'Italy' }
グループ平均の多重比較の例に示したグループのすべての異なるペアに関する多重比較の結果によると、米国と日本の平均値が有意に異なります。この例では、既定の検定であるテューキーの HSD 法を使用しています。
ダネットの検定を使用して、グループ平均を制御グループと比較します。
CriticalValueTypeを "dunnett" と指定して、ダネットの検定を実行します。既定では、multcompare は最初のグループ (米国) を制御グループとして選択します。名前と値の引数ControlGroupを使用して、異なる制御グループを選択できます。
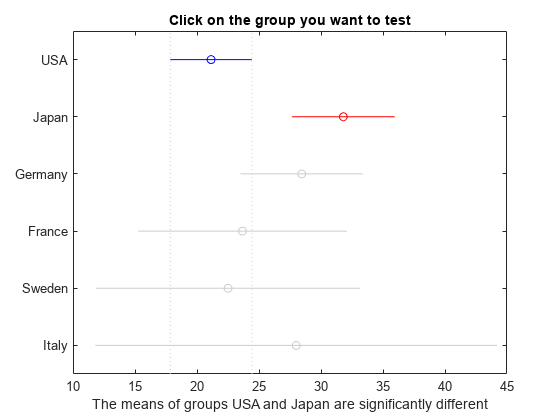
[results,~,~,gnames] = multcompare(stats,"CriticalValueType","dunnett");
図の青い円は、制御グループの平均を示しています。赤い円とバーは、制御グループの平均と有意に異なる平均値をもつグループの平均値および信頼区間を表しています。赤いバーは、制御グループの平均を表す垂直方向の点線と交差していないことに注意してください。有意に異なる平均値をもたないグループはグレーで表示されています。
ダネットの検定により、日本とドイツの 2 つのグループが米国 (制御グループ) の平均と有意に異なる平均値をもつことがわかります。グループ平均の多重比較の例で、既定の方法 (テューキーの HSD 法) ではドイツが特定されなかったことに注意してください。結果の差異は、2 つの比較検定の保守度が異なることに関連しています。ダネットの検定は制御グループとの比較のみを考慮するため、既定の方法ほど保守的ではありません。既定の方法では、グループのすべての異なるペアについて一対比較を実行します。
多重比較の結果と該当するグループ名を table で表示します。
tbl = array2table(results,"VariableNames", ... ["Group","Control Group","Lower Limit","Difference","Upper Limit","P-value"]); tbl.("Group") = gnames(tbl.("Group")); tbl.("Control Group") = gnames(tbl.("Control Group"))
tbl=5×6 table
Group Control Group Lower Limit Difference Upper Limit P-value
___________ _____________ ___________ __________ ___________ _________
{'Japan' } {'USA'} 5.3649 10.667 15.969 4.727e-06
{'Germany'} {'USA'} 0.73151 7.3116 13.892 0.022346
{'France' } {'USA'} -8.3848 2.5339 13.453 0.97912
{'Sweden' } {'USA'} -11.905 1.3672 14.64 0.99953
{'Italy' } {'USA'} -11.76 6.8672 25.495 0.86579
標本データを読み込みます。
load popcorn
popcornpopcorn = 6×3
5.5000 4.5000 3.5000
5.5000 4.5000 4.0000
6.0000 4.0000 3.0000
6.5000 5.0000 4.0000
7.0000 5.5000 5.0000
7.0000 5.0000 4.5000
このデータは、ポップコーンのブランドと製造器具タイプに関する研究 (Hogg 1987) によるものです。行列 popcorn の列はブランド (Gourmet、National、および Generic) を示しています。行は製造器具のタイプ (オイルとエアー) です。初めの 3 行はオイル タイプの製造器具、最後の 3 行はエアー タイプの製造器具に対応しています。この研究では、各製造器具で各ブランドのポップコーンを 3 回ずつ作りました。値は、ポップコーンの生産量をカップ単位で示しています。
2 因子 ANOVA を実行します。主効果について多重比較検定を実行するために必要な統計量も計算します。
[~,~,stats] = anova2(popcorn,3,"off")stats = struct with fields:
source: 'anova2'
sigmasq: 0.1389
colmeans: [6.2500 4.7500 4]
coln: 6
rowmeans: [4.5000 5.5000]
rown: 9
inter: 1
pval: 0.7462
df: 12
構造体 stats には次の情報が含まれています。
平均二乗誤差 (
sigmasq)各ポップコーン ブランドの平均生産量の推定値 (
colmeans)各ポップコーン ブランドの観測数 (
coln)各製造器具タイプの平均生産量の推定値 (
rowmeans)各製造器具タイプの観測数 (
rown)交互作用の数 (
inter)交互作用項の有意水準を示す p 値 (
pval)誤差自由度 (
df)
多重比較検定を実行して、出来上がるポップコーンの量がポップコーン ブランド (列) のペア間で異なるかどうかを調べます。
c1 = multcompare(stats);
Note: Your model includes an interaction term. A test of main effects can be difficult to interpret when the model includes interactions.
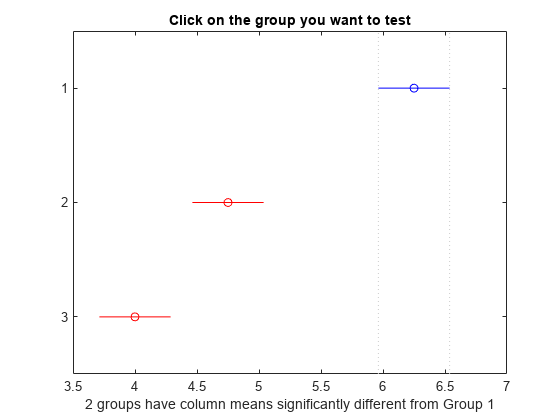
図には、平均の多重比較が示されています。既定では、グループ 1 の平均が強調表示され、比較区間が青になります。他の 2 つのグループの比較区間は、グループ 1 の平均の区間と重なっていないので、赤で強調表示されています。区間が重なっていないことから、どちらの平均もグループ 1 の平均と異なることがわかります。他のグループの平均を選択して、すべてのグループの平均が他と有意に異なることを確認します。
多重比較の結果を table で表示します。
tbl1 = array2table(c1,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"])
tbl1=3×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
_______ _______ ___________ ____ ___________ __________
1 2 0.92597 1.5 2.074 4.1188e-05
1 3 1.676 2.25 2.824 6.1588e-07
2 3 0.17597 0.75 1.324 0.011591
c1 の初めの 2 列には、比較したグループが示されています。4 列目には、推定したグループ平均の間の差が示されています。3 列目と 5 列目には、真の平均の差に関する 95% 信頼区間の下限と上限が示されています。6 列目には、対応する平均の差がゼロに等しいという仮説を検定するための p 値が含まれています。すべての "p" 値が非常に小さいので、3 つのブランドすべてででき上がるポップコーンの量が異なることがわかります。
多重比較検定を実行して、出来上がるポップコーンの量が 2 種類の製造器具タイプ (行) の間で異なるかどうかを調べます。
c2 = multcompare(stats,"Estimate","row");
Note: Your model includes an interaction term. A test of main effects can be difficult to interpret when the model includes interactions.
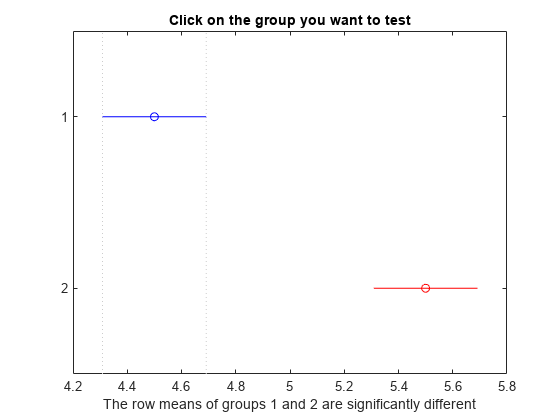
tbl2 = array2table(c2,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"])
tbl2=1×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
_______ _______ ___________ ___ ___________ __________
1 2 -1.3828 -1 -0.61722 0.00010037
"p" 値が小さいので、でき上がるポップコーンの量は 2 つの製造器具タイプ (エアーとオイル) で異なることがわかります。図には同じ結果が示されています。比較区間が重なっていないので、グループの平均が互いに有意に異なることがわかります。
標本データを読み込みます。
y = [52.7 57.5 45.9 44.5 53.0 57.0 45.9 44.0]'; g1 = [1 2 1 2 1 2 1 2]; g2 = ["hi" "hi" "lo" "lo" "hi" "hi" "lo" "lo"]; g3 = ["may" "may" "may" "may" "june" "june" "june" "june"];
y は応答ベクトル、g1、g2 および g3 はグループ化変数 (因子) です。各因子には 2 つの水準があり、y のすべての観測値は因子の水準の組み合わせによって識別されます。たとえば、観測値 y(1) は、因子 g1 の水準 1、因子 g2 の水準 hi および因子 g3 の水準 may に関連付けられています。同様に、観測値 y(6) は、因子 g1 の水準 2、因子 g2 の水準 hi および因子 g3 の水準 june に関連付けられています。
すべての因子水準について応答が同じであるか検定します。また、多重比較検定に必要な統計量も計算します。
[~,~,stats] = anovan(y,{g1 g2 g3},"Model","interaction", ...
"Varnames",["g1","g2","g3"]);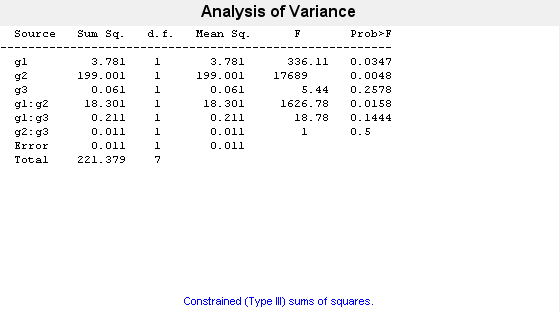
0.2578 という "p" 値は、因子 g3 の水準 may および june について平均応答が有意には異なっていないことを示しています。0.0347 という p 値は、因子 g1 の水準 1 および 2 について平均応答が有意に異なっていることを示しています。同様に、0.0048 という "p" 値は、因子 g2 の水準 hi および lo について平均応答が有意に異なっていることを示しています。
多重比較検定を実行し、因子 g1 および g2 についてどのグループが有意に異なるかを調べます。
[results,~,~,gnames] = multcompare(stats,"Dimension",[1 2]);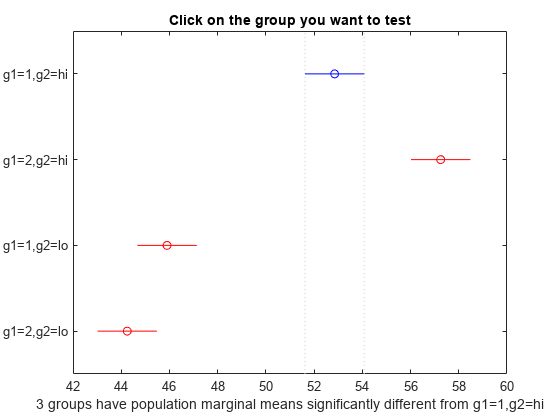
対応するグループの比較区間をクリックすると、他のグループについて検定を行うことができます。クリックしたバーは青になります。有意に異なるグループのバーは、赤になります。有意には異ならないグループのバーは、灰色になります。たとえば、g1 の水準 1 と g2 の水準 lo の組み合わせの比較区間をクリックすると、g1 の水準 2 と g2 の水準 lo の組み合わせの比較区間は重なるので灰色になります。逆に、他の比較区間は赤になり、有意に異なることを示します。
多重比較の結果と該当するグループ名を table で表示します。
tbl = array2table(results,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"]); tbl.("Group A")=gnames(tbl.("Group A")); tbl.("Group B")=gnames(tbl.("Group B"))
tbl=6×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
______________ ______________ ___________ _____ ___________ _________
{'g1=1,g2=hi'} {'g1=2,g2=hi'} -6.8604 -4.4 -1.9396 0.027249
{'g1=1,g2=hi'} {'g1=1,g2=lo'} 4.4896 6.95 9.4104 0.016983
{'g1=1,g2=hi'} {'g1=2,g2=lo'} 6.1396 8.6 11.06 0.013586
{'g1=2,g2=hi'} {'g1=1,g2=lo'} 8.8896 11.35 13.81 0.010114
{'g1=2,g2=hi'} {'g1=2,g2=lo'} 10.54 13 15.46 0.0087375
{'g1=1,g2=lo'} {'g1=2,g2=lo'} -0.8104 1.65 4.1104 0.07375
関数 multcompare は、2 つのグループ化変数 g1 および g2 についてグループ (水準) の組み合わせを比較します。たとえば、この行列の 1 行目は、g1 の水準 1 と g2 の水準 hi の組み合わせが g1 の水準 2 と g2 の水準 hi の組み合わせと同じ平均応答値になっていることを示しています。この検定に対応する "p" 値は 0.0272 なので、平均応答が有意に異なっていることがわかります。この結果は、図からもわかります。青いバーは、g1 の水準 1 と g2 の水準 hi の組み合わせについて平均応答の比較区間を示しています。赤いバーは、他のグループの組み合わせについて平均応答の比較区間を示しています。どの赤いバーも青いバーと重なっていないので、g1 の水準 1 と g2 の水準 hi の組み合わせの平均応答が他のグループの組み合わせの平均応答と有意に異なっていることがわかります。
入力引数
名前と値の引数
出力引数
詳細
参照
[1] Hochberg, Y., and A. C. Tamhane. Multiple Comparison Procedures. Hoboken, NJ: John Wiley & Sons, 1987.
[2] Milliken, G. A., and D. E. Johnson. Analysis of Messy Data, Volume I: Designed Experiments. Boca Raton, FL: Chapman & Hall/CRC Press, 1992.
[3] Searle, S. R., F. M. Speed, and G. A. Milliken. “Population marginal means in the linear model: an alternative to least-squares means.” American Statistician. 1980, pp. 216–221.