anovan
多因子分散分析
構文
説明
p = anovan(y,group,Name,Value)Name,Value ペア引数で指定された追加オプションを使用して、多因子 (n 因子) ANOVA の p 値のベクトルを返します。
たとえば、どの予測子変数が連続的であるかや、どのタイプの二乗和を使用するかを指定できます。
[ から返される構造体 p,tbl,stats] = anovan(___)stats を使用して、多重比較検定を実行できるようになります。これにより、どのグループ平均のペアが有意に異なるかを判別できます。このような検定を実行するには、構造体 stats を入力引数として指定し、関数 multcompare を使用します。
例
標本データを読み込みます。
y = [52.7 57.5 45.9 44.5 53.0 57.0 45.9 44.0]';
g1 = [1 2 1 2 1 2 1 2];
g2 = {'hi';'hi';'lo';'lo';'hi';'hi';'lo';'lo'};
g3 = {'may';'may';'may';'may';'june';'june';'june';'june'};y は応答ベクトル、g1、g2 および g3 はグループ化変数 (因子) です。各因子には 2 つの水準があり、y のすべての観測値は因子の水準の組み合わせによって識別されます。たとえば、観測値 y(1) は、因子 g1 の水準 1、因子 g2 の水準 'hi' および因子 g3 の水準 'may' に関連付けられています。同様に、観測値 y(6) は、因子 g1 の水準 2、因子 g2 の水準 'hi' および因子 g3 の水準 'june' に関連付けられています。
すべての因子水準について応答が同じであるか検定します。
p = anovan(y,{g1,g2,g3})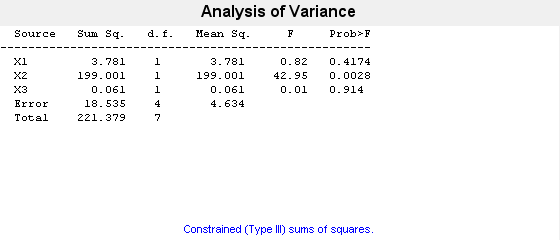
p = 3×1
0.4174
0.0028
0.9140
ANOVA 表の X1、X2 および X3 は、それぞれ因子 g1、g2 および g3 に対応しています。0.4174 という p は、因子 g1 の水準 1 および 2 について平均応答が有意には異ならないことを示しています。同様に、0.914 という p 値は、因子 g3 の水準 'may' および 'june' について平均応答が有意には異ならないことを示しています。しかし、0.0028 という p 値は十分に小さいので、因子 g2 の 2 つの水準 'hi' および 'lo' について平均応答が有意に異なると結論づけることができます。既定の設定では、anovan は 3 つの主効果のみについて p 値を計算します。
2 因子の交互作用を検定します。今回は、変数名を指定します。
p = anovan(y,{g1 g2 g3},'model','interaction','varnames',{'g1','g2','g3'})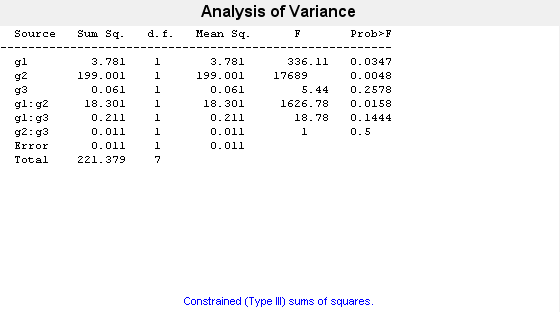
p = 6×1
0.0347
0.0048
0.2578
0.0158
0.1444
0.5000
交互作用項は、ANOVA 表で g1*g2、g1*g3 および g2*g3 によって表されています。p の初めの 3 つの項目は、主効果の p 値です。終わりの 3 つの項目は、2 次交互作用の p 値です。0.0158 という p 値は、g1 と g2 の交互作用が有意であることを示しています。0.1444 および 0.5 という p 値は、対応する交互作用が有意ではないことを示しています。
標本データを読み込みます。
load carbigこのデータには、406 台の自動車についての測定値が含まれています。変数 org は自動車の製造国、変数 when は自動車の製造時期を表しています。
自動車を製造した時期と国によって燃費効率がどのように変化するかを調べます。また、2 次交互作用をモデルに含めます。
p = anovan(MPG,{org when},'model',2,'varnames',{'origin','mfg date'})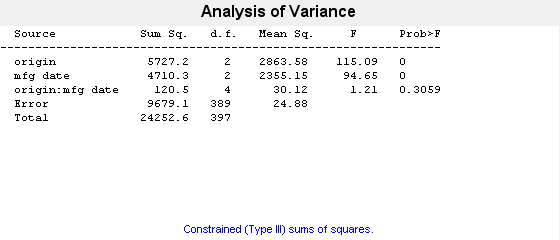
p = 3×1
0.0000
0.0000
0.3059
名前と値のペアの引数 'model',2 は、2 次交互作用を表します。交互作用項の p 値は 0.3059 という小さくない値なので、製造時期 (mfg date) の効果が製造国 (origin) の影響を受けることを示す証拠はほとんどありません。しかし、製造国と製造時期の主効果は、どちらも p 値が 0 なので有意です。
標本データを読み込みます。
y = [52.7 57.5 45.9 44.5 53.0 57.0 45.9 44.0]'; g1 = [1 2 1 2 1 2 1 2]; g2 = ["hi" "hi" "lo" "lo" "hi" "hi" "lo" "lo"]; g3 = ["may" "may" "may" "may" "june" "june" "june" "june"];
y は応答ベクトル、g1、g2 および g3 はグループ化変数 (因子) です。各因子には 2 つの水準があり、y のすべての観測値は因子の水準の組み合わせによって識別されます。たとえば、観測値 y(1) は、因子 g1 の水準 1、因子 g2 の水準 hi および因子 g3 の水準 may に関連付けられています。同様に、観測値 y(6) は、因子 g1 の水準 2、因子 g2 の水準 hi および因子 g3 の水準 june に関連付けられています。
すべての因子水準について応答が同じであるか検定します。また、多重比較検定に必要な統計量も計算します。
[~,~,stats] = anovan(y,{g1 g2 g3},"Model","interaction", ...
"Varnames",["g1","g2","g3"]);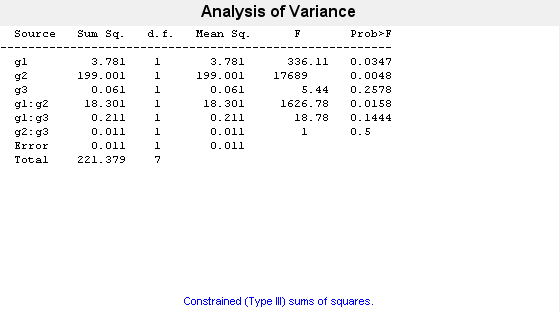
0.2578 という "p" 値は、因子 g3 の水準 may および june について平均応答が有意には異なっていないことを示しています。0.0347 という p 値は、因子 g1 の水準 1 および 2 について平均応答が有意に異なっていることを示しています。同様に、0.0048 という "p" 値は、因子 g2 の水準 hi および lo について平均応答が有意に異なっていることを示しています。
多重比較検定を実行し、因子 g1 および g2 についてどのグループが有意に異なるかを調べます。
[results,~,~,gnames] = multcompare(stats,"Dimension",[1 2]);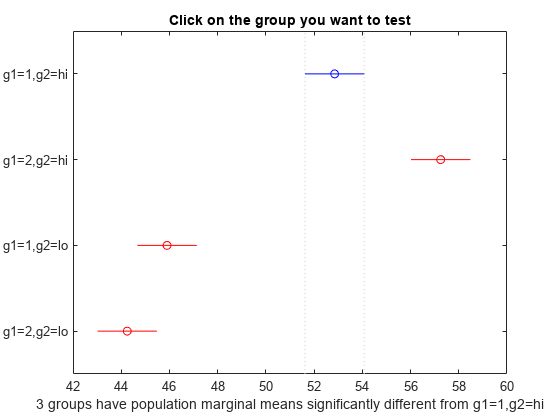
対応するグループの比較区間をクリックすると、他のグループについて検定を行うことができます。クリックしたバーは青になります。有意に異なるグループのバーは、赤になります。有意には異ならないグループのバーは、灰色になります。たとえば、g1 の水準 1 と g2 の水準 lo の組み合わせの比較区間をクリックすると、g1 の水準 2 と g2 の水準 lo の組み合わせの比較区間は重なるので灰色になります。逆に、他の比較区間は赤になり、有意に異なることを示します。
多重比較の結果と該当するグループ名を table で表示します。
tbl = array2table(results,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"]); tbl.("Group A")=gnames(tbl.("Group A")); tbl.("Group B")=gnames(tbl.("Group B"))
tbl=6×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
______________ ______________ ___________ _____ ___________ _________
{'g1=1,g2=hi'} {'g1=2,g2=hi'} -6.8604 -4.4 -1.9396 0.027249
{'g1=1,g2=hi'} {'g1=1,g2=lo'} 4.4896 6.95 9.4104 0.016983
{'g1=1,g2=hi'} {'g1=2,g2=lo'} 6.1396 8.6 11.06 0.013586
{'g1=2,g2=hi'} {'g1=1,g2=lo'} 8.8896 11.35 13.81 0.010114
{'g1=2,g2=hi'} {'g1=2,g2=lo'} 10.54 13 15.46 0.0087375
{'g1=1,g2=lo'} {'g1=2,g2=lo'} -0.8104 1.65 4.1104 0.07375
関数 multcompare は、2 つのグループ化変数 g1 および g2 についてグループ (水準) の組み合わせを比較します。たとえば、この行列の 1 行目は、g1 の水準 1 と g2 の水準 hi の組み合わせが g1 の水準 2 と g2 の水準 hi の組み合わせと同じ平均応答値になっていることを示しています。この検定に対応する "p" 値は 0.0272 なので、平均応答が有意に異なっていることがわかります。この結果は、図からもわかります。青いバーは、g1 の水準 1 と g2 の水準 hi の組み合わせについて平均応答の比較区間を示しています。赤いバーは、他のグループの組み合わせについて平均応答の比較区間を示しています。どの赤いバーも青いバーと重なっていないので、g1 の水準 1 と g2 の水準 hi の組み合わせの平均応答が他のグループの組み合わせの平均応答と有意に異なっていることがわかります。
入力引数
名前と値の引数
出力引数
代替機能
anovan を使用する代わりに、関数 anova を使用して anova オブジェクトを作成できます。関数 anova には次の利点があります。
関数
anovaでは、ANOVA モデルのタイプ、二乗和のタイプ、カテゴリカルとして扱う因子を指定できます。anovaでは、table の予測子と応答の入力引数もサポートされます。anovaオブジェクトのプロパティには、anovanで返される出力に加えて以下が含まれます。ANOVA モデルの式
当てはめられる ANOVA モデルの係数
残差
因子と応答データ
anovaオブジェクトを当てはめた後に、anovaのオブジェクト関数を使用して追加の解析を実行できます。たとえば、ANOVA の平均の多重比較についての対話型プロットを作成したり、因子の各値の平均応答推定を取得したり、分散成分推定を計算したりできます。
参照
[1] Dunn, O.J., and V.A. Clark. Applied Statistics: Analysis of Variance and Regression. New York: Wiley, 1974.
[2] Goodnight, J.H., and F.M. Speed. Computing Expected Mean Squares. Cary, NC: SAS Institute, 1978.
[3] Seber, G. A. F., and A. J. Lee. Linear Regression Analysis. 2nd ed. Hoboken, NJ: Wiley-Interscience, 2003.
バージョン履歴
R2006a より前に導入