診断特徴デザイナーを使用したアンサンブル データの調査と特徴の比較
診断特徴デザイナー アプリを使うと、多機能グラフィカル インターフェイスを使用して、予知保全ワークフローの特徴設計の部分を実行できるようになります。特徴を対話的に設計および比較してから、定格システムと故障システムなど、異なるグループからのデータの区別に最も適した特徴を決定します。故障に至るまで実行されたデータがある場合、残存耐用期間 (RUL) を決定するのに最も適した特徴はどれかを評価することもできます。最も効果的な特徴は、最終的に故障の診断と予知のための状態インジケーターとすることができます。
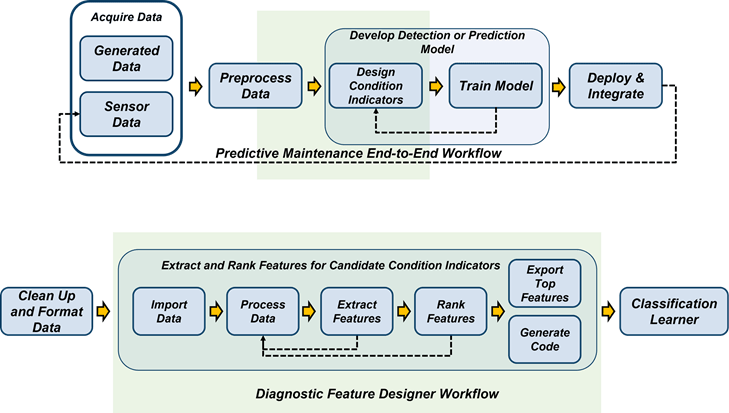
次の図は、予知保全のワークフローと診断特徴デザイナーの機能との関係を示しています。
全体的な予知保全ワークフローには、データの収集、データの前処理、状態インジケーターの設計、モデルのトレーニング、およびモデルの展開と統合が含まれます。このワークフローの詳細については、What Is Predictive Maintenance?を参照してください。
ワークフローの診断特徴デザイナーの部分は、データのインポートから始まり、データの処理、特徴の抽出およびランク付けを繰り返し行い、効果的な特徴セットを作成するプロセスが含まれます。このワークフローにはコード生成も含まれ、モデルの生成と比較のための分類学習器や回帰学習器などのツールへの特徴のエクスポートも含まれます。
アプリはアンサンブル データを処理します。アンサンブル データには、複数の類似したマシンや、日または年などの時間間隔でデータがセグメント化されている単一のマシンなど、複数メンバーからのデータ測定値が含まれています。データには、アンサンブル メンバーの故障状態または動作状態を記述する状態変数が含まれることもあります。状態変数は通常、"ラベル" と呼ばれる定義済みの値をもちます。データ アンサンブルの詳細については、状態監視と予知保全のためのデータ アンサンブルを参照してください。
アプリ内のワークフローは、既に次の状態にあるデータのインポート時に開始されます。
クリーンアップ機能により前処理されている
個々のデータ ファイルか、またはすべてのアンサンブル メンバーを含むか参照する単一のアンサンブル データ ファイルに整理されている
診断特徴デザイナー内のワークフローには、データをさらに処理し、データから特徴を抽出して、これらの特徴を有効度でランク付けするために必要な手順が含まれています。ワークフローの最後に、最も効果的な特徴を選択し、それらの特徴をモデルの学習用に分類学習器アプリまたは回帰学習器アプリにエクスポートします。
ワークフローにはオプションとして、MATLAB® コードの生成手順が含まれます。選択した特徴の計算が記述されたコードを生成すれば、異なる工場にある類似のマシンなど、より多くのメンバーが含まれる、より大規模な測定データセットのために、これらの計算を自動化できます。結果として得られる特徴セットは、分類学習器および回帰学習器に対する追加の学習入力を提供します。ストリーミング データ用に書式設定されたコードや Simulink® ブロックを生成することもできます。
診断特徴デザイナーを使った予知保全タスクの実行
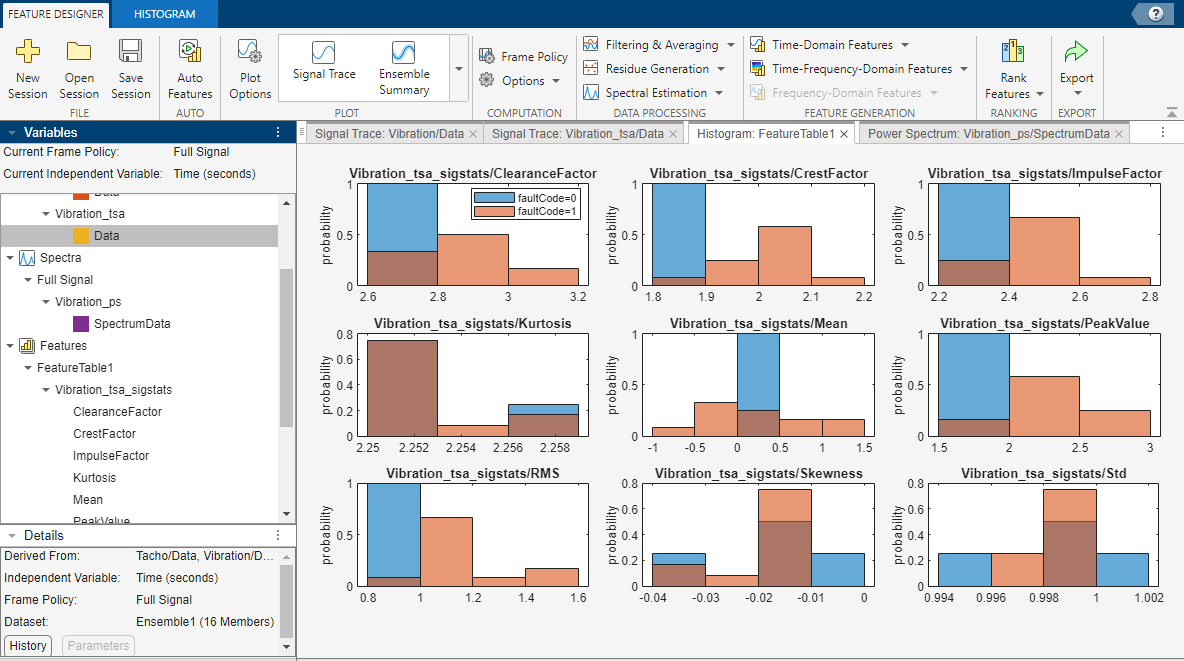
次のイメージは、診断特徴デザイナーの基本的な機能を示しています。データと結果を操作するには、図に示されている [特徴デザイナー] タブなどのタブにあるコントロールを使用します。インポートおよび導出した変数、特徴、およびデータ セットを [データ ブラウザー] で表示します。結果をプロット領域で可視化します。
統合アンサンブル データ セットへのインポート データの変換
アプリを使用する際の最初の手順は、新規セッションを作成してデータをインポートすることです。データは table、timetable、cell 配列、または行列からインポートできます。また、アプリが外部のデータ ファイルを操作できるようにする情報の含まれた、アンサンブル データストアをインポートすることもできます。ファイルには、実際の、またはシミュレートされた時間領域測定データ、スペクトル モデルまたはスペクトル データ、変数名、状態変数と動作変数、および前に生成した特徴を含めることができます。診断特徴デザイナーはすべてのメンバー データを単一のアンサンブル データセットに組み合わせます。このデータセットでは各変数が、個々のメンバーの値をすべて含む集合的信号あるいは集合的モデルとなります。
複数のセッションで同じデータを使用するには、初期セッションをセッション ファイルに保存することができます。セッション データには、インポートされた変数と、計算した追加の変数および特徴がすべて含まれます。後続のセッションでセッション ファイルを開き、インポート データや派生データの処理を続けることができます。
データの準備とインポートの詳細については、以下を参照してください。
インポート処理自体の詳細については、診断特徴デザイナーでのアンサンブル データのインポートと可視化を参照してください。
データの可視化
インポートした、または処理ツールで生成した信号やスペクトルをプロットするには、プロット ギャラリーからプロット タイプを選択します。次の図は一般的な信号トレースを示しています。対話的なプロット ツールによって、ピークの位置やピーク間距離をパン、ズーム、表示したり、アンサンブル内の統計的な変化を表示することができます。プロット内のデータを状態ラベルでグループ化すると、メンバー データがたとえば定格システムと故障システムのどちらに由来するのかを明確に示すことができます。
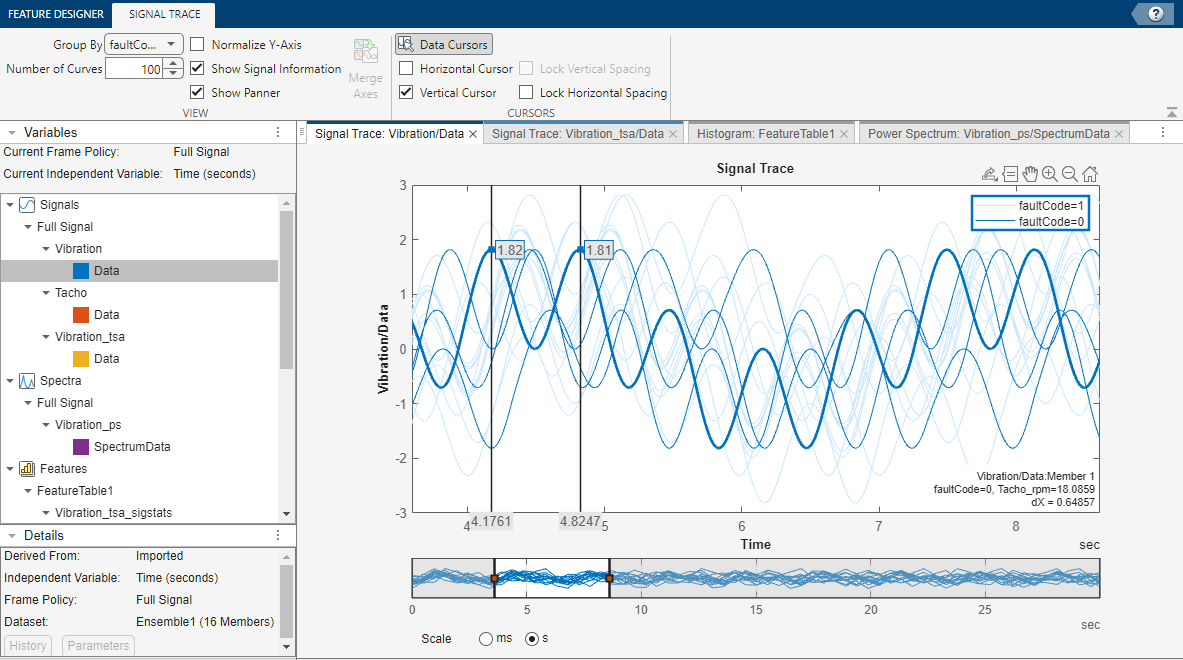
アプリ内でのプロットの詳細については、診断特徴デザイナーでのアンサンブル データのインポートと可視化を参照してください。
新しい変数の計算
データを調査して特徴抽出のために準備するには、データ処理ツールを使用します。処理ツールを適用するたびにアプリは新しい派生変数を作成し、これに、ソース変数と直近で使用された処理手順の両方を含む名前を付けます。以下に例を示します。
変数
Vibration/Dataに対し時間同期信号平均化 (TSA) 処理を適用した場合、新しい派生変数の名前はVibration_tsa/Dataになります。次に
Vibration_tsa/Dataからパワー スペクトルを計算した場合、新しい変数の名前はVibration_ps/SpectrumDataになります。この新しい名前には、直近の処理psと、変数が信号ではなくスペクトルであるという事実の両方が反映されています。
変数に関する詳細情報を確認するには、[詳細] ペインを使用します。このエリアには、直接ソース信号や独立変数などの情報が表示されます。また、変数の処理履歴をプロットして、直近の操作のパラメーターを表示することもできます。
すべての信号のデータ処理オプションには、アンサンブルレベルの統計値、信号残差、フィルター処理、およびパワー スペクトルと次数スペクトルが含まれます。独立変数での同一間隔でメンバー サンプルが発生しない場合は、データを等間隔グリッドに内挿することもできます。
回転機から得たデータの場合、タコメーター出力または定格 rpm に基づいて TSA 処理を実行できます。TSA 信号から、TSA 残差や差分信号などの追加の信号を生成できます。TSA から導出したこれらの信号は、高調波と側波帯を保持または破棄することでシステム内の物理コンポーネントを分離し、それらは多くのギア状態の特徴のベースとなります。
処理オプションの多くは独立して使用できます。オプションには、シーケンスとして実行できる、あるいは実行しなければならないものもあります。前に説明した回転機と TSA 信号に加え、もう 1 つの例として任意の信号の残差生成があります。次のことが可能です。
[アンサンブル統計] を使用して、アンサンブル全体を特徴付ける平均や最大値など、単一メンバーの統計的変数を生成します。
[基準信号の減算] を使用して、アンサンブルレベルの値を減算することで各メンバーの残差信号を生成します。これらの残差は信号間の変動を表し、アンサンブルの残りの部分から逸脱する信号をより明確に示すことができます。
これらの残差信号を、追加の処理オプションあるいは特徴生成のソースとして使用します。
アプリ内におけるデータ処理オプションの詳細については、診断特徴デザイナーでのデータの処理と特徴の調査を参照してください。
フレームベースおよび並列の処理
アプリには、フレームベース (セグメント化) および並列の処理に用いるオプションが用意されています。
既定では、アプリは一度の操作で信号全体を処理します。信号をセグメント化して個々のフレームを処理することもできます。フレームベースの処理は、アンサンブルのメンバーが非定常動作、時変動作、または周期的動作を示す場合に特に便利です。フレームベースの処理は、特徴値の時系列履歴も提供しているため、予知ランク付けもサポートしています。
Parallel Computing Toolbox™ がある場合は、並列処理を使用できます。アプリは同じ処理をすべてのメンバーに対し個別に行うことが多いため、並列処理によって計算時間を大幅に改善することができます。
特徴の生成
元の信号と導出された信号およびスペクトルから、特徴を計算してその有効度を評価することができます。どの特徴が最もよく機能するか既にわかっている場合もあれば、該当するすべての特徴を使って実験することが望ましい場合もあります。利用できる特徴は、一般的な信号統計から、故障の正確な位置を特定できる特殊なギア状態メトリクス、そして無秩序動作を強調する非線形の特徴までさまざまです。
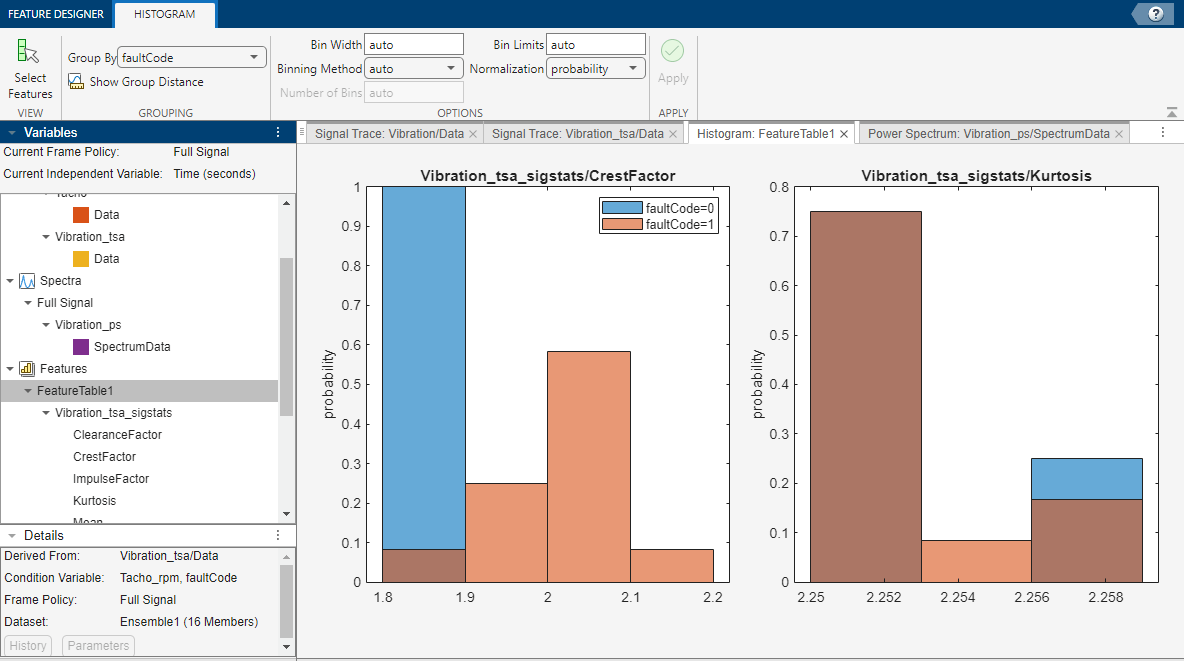
一連の特徴を計算するたびに、アプリはそれらを特徴テーブルに追加して、メンバー全体を通した値の分布のヒストグラムを生成します。次の図は、2 つの特徴のヒストグラムを示しています。ヒストグラムは、各特徴がラベル付きデータをどの程度うまく区別するかを表しています。たとえば次の図で示すように、状態変数が faultCode であり、定格システムのデータに状態 0 (青色) を、故障システムのデータに状態 1 (オレンジ色) を用いるとします。ヒストグラムでは、定格状態と故障状態のグループ化の結果が、区別の明確なヒストグラム ビンとなるか混合したヒストグラム ビンとなるかを、ビン内の混色の有無によって確認できます。特徴のヒストグラムすべてを一度に表示したり、どの特徴をアプリがヒストグラム プロットのセットに含めるかを選択することもできます。図では、CrestFactor のビンは主に純粋な青か純粋なオレンジであり、区別が良好であることを示します。Kurtosis ヒストグラムのビンは主に、青とオレンジの混色である暗いオレンジであり、区別が不十分であることを示します。
すべての特徴の値を一緒に比較するには、特徴テーブル ビューと特徴トレース プロットを使用します。特徴テーブル ビューには、全アンサンブル メンバーの特徴値すべてのテーブルが表示されます。特徴トレースはこれらの値をプロットします。このプロットは、アンサンブル内における特徴値の逸脱を可視化するもので、ある特徴値が表す特定のメンバーを識別することができます。
アプリでの特徴の生成とヒストグラムの解釈の詳細については、以下を参照してください。
特徴のランク付け
ヒストグラムによって特徴の有効度の初期評価を実行できます。より厳密な相対評価を行うには、専用の統計的手法を使用して特徴をランク付けすることができます。アプリは "教師ありのランク付け"、"教師なしのランク付け"、および "予知ランク付け" という 3 タイプのランク付けを提供します。
教師ありのランク付けには、"分類ランク付け" と "回帰ランク付け" の両方の手法が含まれます。
分類ランク付けは、定格動作と故障動作の区別など、データ グループを区別する能力によって特徴にスコアを与え、ランク付けを行います。このタイプのランク付けには、データ グループを特徴付けるラベルを含む状態変数が必要です。
回帰ランク付けは、数値応答を正確に予測する能力によって特徴にスコアを与え、ランク付けを行います。このタイプのランク付けには、実際の数値応答を提供する状態変数が必要です。
教師なしのランク付けに、データ ラベルや応答データなどの状態変数は必要ありません。このタイプのランク付けでは、他の特徴とクラスターをなす傾向に基づき特徴にスコアを与え、ランク付けをします。
予知ランク付け手法は、劣化を追跡する能力に基づいて特徴にスコアを与え、ランク付けします。これにより、残存耐用期間 (RUL) の予測が可能になります。予知ランク付けには、故障に至るまで実行されたデータまたは故障進行データの実データまたはシミュレーション データが必要であり、状態変数は使用されません。
次の図は、教師ありの分類のランク付けの結果を示しています。複数のランク付け方法を試行して、各方法の結果を一緒に表示できます。ランク付けの結果によって、効果のない特徴を排除し、派生した変数や特徴を計算する際にパラメーター調整のランク付けの効果を評価することができます。
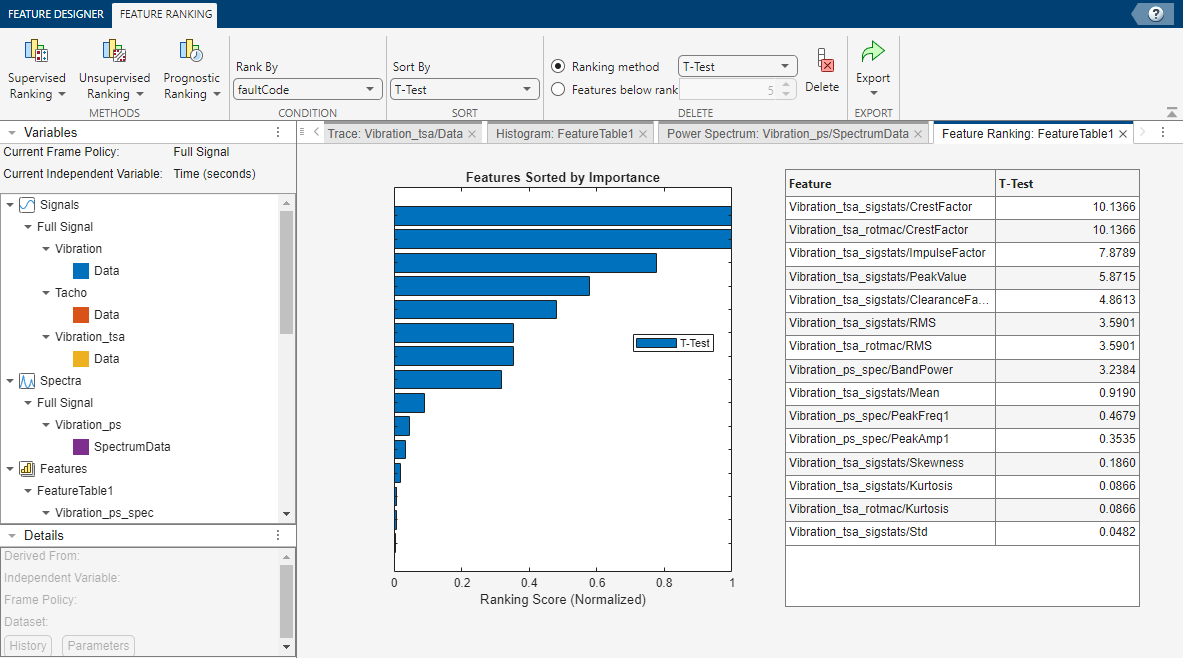
特徴のランク付けの詳細については、以下を参照してください。
診断特徴デザイナーの [特徴のランク付け] タブとランク付け手法のセクション
特徴のエクスポート
特徴候補のセットを定義したら、それらを Statistics and Machine Learning Toolbox™ の分類学習器アプリまたは回帰学習器アプリにエクスポートできます。
分類学習器は、特徴セットにより各種のモデルをテストする自動化された方法を使用して、データの分類をモデルに学習させます。そうすることで、分類学習器は最適なモデルと最も効果的な特徴を決定します。予知保全の場合、分類学習器を使用する目的は、健全なシステムのデータと故障状態のシステムのデータを区別するモデルを選択し、学習させることです。このモデルを故障の検出と予測のアルゴリズムに組み込むことができます。アプリから分類学習器へのエクスポートの例は、ポンプ診断用の特徴の解析と選択を参照してください。
回帰学習器は、同じく自動化された方法を使用して最適なモデルと最も効果的な特徴を見つけ、数値応答の予測をモデルに学習させます。このモデルをしきい値 (予測応答が動作限界を超える時点を示す値) を含む故障の検出と予測のアルゴリズムに組み込むことができます。
特徴とデータ セットを MATLAB ワークスペースにエクスポートすることもできます。これにより、コマンド ラインの関数や他のアプリを使用して元のアンサンブル データおよび導出したアンサンブル データを可視化し、処理できるようになります。コマンド ラインでは、選択した特徴と変数を、(アンサンブル データストアで参照されるファイルを含めた) ファイルに保存することもできます。
エクスポートの詳細については、診断特徴デザイナーでの特徴のランク付けとエクスポートを参照してください。
特徴に対する MATLAB コードの生成
特徴自体のエクスポートに加え、それらの特徴を作成した計算を再現する MATLAB 関数を生成することができます。コードを生成することで、異なるデータ セットでの特徴計算を自動化することができます。たとえば、多数のメンバーをもつ大規模な入力データセットがあるものの、考えられる特徴を対話的に調査するときに、まずはそのデータのサブセットを使用してアプリの応答時間を短縮するとします。アプリを使用して最も効果的な特徴を特定したら、コードを生成したうえで、そのコードを使用して同じ特徴計算をフルメンバーのデータ セットに適用することができます。メンバー セットが大規模になるほど、学習入力として分類学習器に提示できるサンプル数も多くなります。
次の図は [コード生成] タブを示しています。ここでは、特徴入力や計算方法などの条件に基づいて特徴を選択するための、詳細なクエリを実行することができます。

function [featureTable,outputTable] = diagnosticFeatures(inputData) %DIAGNOSTICFEATURES recreates results in Diagnostic Feature Designer. %
ストリーミング データ用に書式設定されたコードやそのコードを使用する Simulink ブロックを生成することもできます。
詳細については、以下を参照してください。