ポンプ診断用の特徴の解析と選択
この例では診断特徴デザイナー アプリを使用して、3 重往復ポンプの故障を診断するための特徴を解析し選択する方法を説明します。
ここではシミュレーション データを使用した複数クラス故障検出の例で生成された、シミュレートしたポンプ故障のデータを使用します。データはポンプの起動遷移を取り除く前処理が済んでいます。
診断特徴デザイナーを開く
3 重ポンプの故障データを読み込みます。ポンプのデータには、さまざまな故障状態における 240 個の流量と圧力の測定値が含まれています。3 つの故障タイプ (ポンプ シリンダーの漏れ、ポンプ入口のブロック、ポンプ ベアリング摩擦の増加) があります。測定値は故障なし、1 つの故障、または複数の故障が存在する状態をカバーしています。データは各行が異なる測定値である table に集められています。
load('savedPumpData')
pumpDatapumpData=240×3 table
flow pressure faultCode
__________________ __________________ _________
{1201×1 timetable} {1201×1 timetable} 0
{1201×1 timetable} {1201×1 timetable} 0
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 0
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
{1201×1 timetable} {1201×1 timetable} 100
⋮
diagnosticFeatureDesigner コマンドを使用して診断特徴デザイナーを開きます。[新規セッション] をクリックして新規セッションを開始すると、データ インポートのためのダイアログ ボックスが開きます。

[データセットをワークスペースから選択] ペインで、pumpData をデータ ソースとして選択します。[ソース変数を選択] ペインで、変数名が、コマンド ラインに表示された名前と一致することを確認します。flow と pressure はいずれも信号です。faultCode は "状態変数" です。状態変数は故障の有無を示し、アプリによってグループ化と分類のために使用されます。[新規セッション] ダイアログ ボックスを初めて開くと、アプリにより、最初の変数の変数プロパティが表示されます。

[インポート] をクリックして、ポンプ データをアプリにインポートします。
データのプロットと故障コードによるグループ化
データ ブラウザーの [変数] セクションから flow を選択し、プロット ギャラリーで [信号トレース] をクリックして流量信号をプロットします。pressure 信号も同じ方法でプロットします。

これらのプロットは、データセット内の 240 個すべてのメンバーについて圧力信号と流量信号を示しています。[信号トレース] タブをクリックして [グループ化] で faultCode を選択すると、同じ故障コードをもつ信号が同じ色で表示されます。この方法で信号をグループ化すると、異なる故障タイプの信号間に明確な違いがあるかどうかをすばやく判定することができます。この場合、測定された信号には異なる故障コードによる明らかな違いが見られません。

今後のプロットをすべて faultCode によってグループ化するには、[プロット オプション] を使用します。[プロット オプション] をクリックすると、セッションの基本設定を設定できるダイアログ ボックスが開きます。

時間領域の特徴の抽出
測定信号に異なる故障状態による違いが見られないため、次の手順として、信号の平均値および標準偏差など時間領域の特徴を信号から抽出します。まず、データ ブラウザーで flow/Data を選択します。次に、[時間領域の特徴] を選択してから [信号の特徴] を選択します。

2 つの新規タブ [信号の特徴] および [時間領域の特徴] が開きます。[信号の特徴] で、抽出する特徴を選択して [適用] をクリックします。ここでは [結果のプロット] チェック ボックスをオフにします。結果は、特徴が各種の故障状態を区別するのに役立つかどうかを確認するために、後ほどプロットします。このプロセスを圧力信号について繰り返します。

周波数領域の特徴の抽出
往復ポンプはドライブ シャフトとシリンダーを使って流体を移動させます。ポンプの機械的な構成のため、ポンプの流量と圧力には周期的な変動があるものと見込まれます。たとえば、信号トレース プロットの下の信号パナーを使用して、流量信号のセクションを拡大します。

流量の周波数スペクトルを計算することで流量信号の周期性が強調表示され、さまざまな故障状態下で流量信号がどのように変化するかの理解が深まります。自己回帰モデルを使用して周波数スペクトルを推定します。

このメソッドは、指定された次数の自己回帰モデルをデータに当てはめた後、その推定モデルのスペクトルを計算します。この方法は生のデータ信号への過適合を減らします。ここでは 20 のモデル次数を指定します。また、周波数グリッドが最小値 0 と最大値 500 をもつよう設定します。
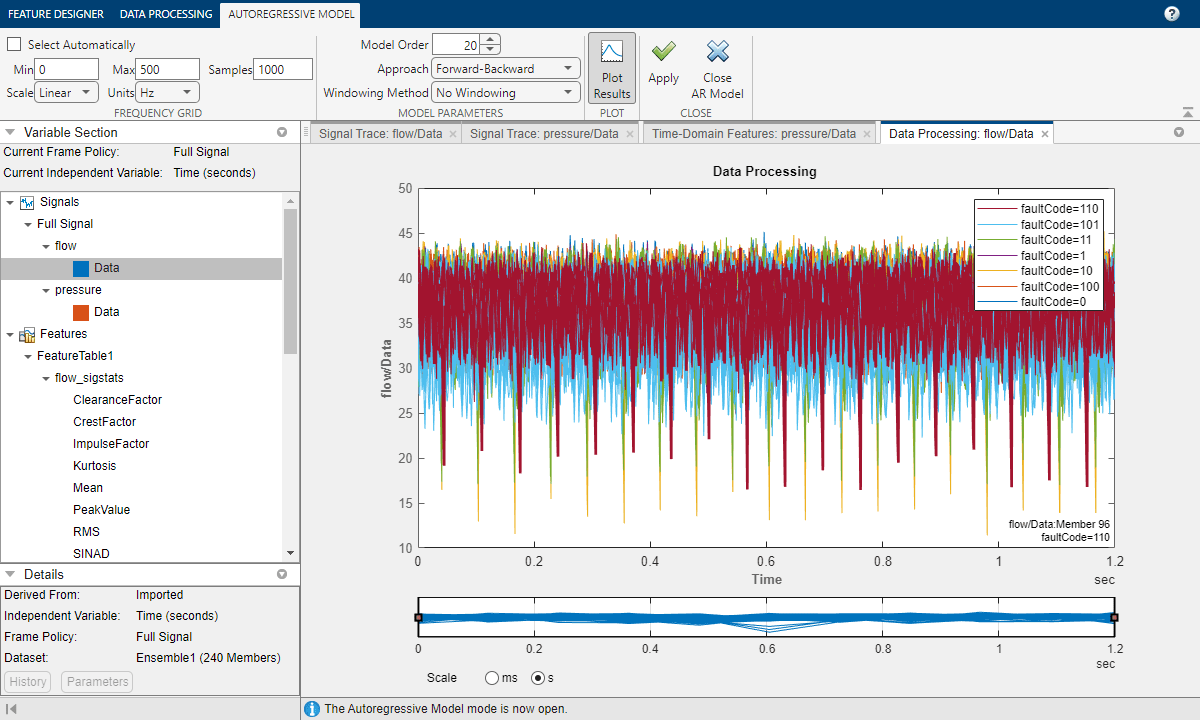
計算したスペクトルを線形スケールでプロットすると、共振ピークが明確に示されます。故障コードでグループ化すると、異なる故障状態によってスペクトルがいかに変化するかが強調表示されます。

圧力信号についても同じ計算を行うと、結果から、さまざまな故障状態の区別に役立つ追加の特徴が提示されます。
ここで、ピーク、モーダル係数、帯域パワーなどのスペクトル特徴を計算することができます。

250 Hz の後のピークは小さくなるので、これらの特徴を 23 ~ 250 Hz の比較的狭い周波数帯域で抽出します。各信号につき 5 つのスペクトル ピークを抽出します。ここでは [結果のプロット] チェック ボックスをオフにします。結果は、特徴が各種の故障状態を区別するのに役立つかどうかを確認するために、後ほどプロットします。ダイアログ ボックスの上部で選択されている信号を変更して、このプロセスを圧力信号について繰り返します。

特徴の表示
抽出したすべての特徴は、[特徴テーブル] ブラウザーに表示される table に収集されています。計算した特徴データを表示するには、データ ブラウザーから FeatureTable1 を選択してプロット ギャラリーの [特徴テーブル ビュー] をクリックします。故障コードは、特徴テーブル ビューでテーブルの一番右の列にも表示されます。計算される特徴の数が増えると、テーブルに列が追加されます。

特徴テーブルをヒストグラムとして表示することで、異なる状態変数値 (ここでは故障タイプ) に対する特徴値の分布を確認できます。FeatureTable1 を選択してから、プロット ギャラリーの [ヒストグラム] をクリックしてヒストグラム プロットのセットを作成します。異なる特徴のヒストグラムを表示するには、[次へ] ボタンと [前へ] ボタンを使用します。故障コードでグループ化されたヒストグラム プロットは、特定の特徴が故障タイプ間の強い差別化要因であるかどうかを判定するのに役立ちます。強い差別化要因である場合、その分布の間の距離はより遠くなります。3 重ポンプのデータでは、特徴の分布が重なる傾向にあり、特徴の識別に使用できることが明らかな特徴はありません。次の節では、自動ランク付けを使用して、どの特徴が故障の予測に役立つかを考えます。

特徴のランク付けとエクスポート
[特徴デザイナー] タブから [特徴のランク付け] をクリックして FeatureTable1 を選択します。アプリがすべての特徴データを収集し、ANOVA などのメトリクスに基づいて特徴をランク付けします。アプリは、メトリクス値に基づく重要度の順に特徴量をリストします。この場合、流量信号の RMS 値および圧力信号の RMS 値と平均値が、異なる故障タイプを互いから最も強く区別する特徴です。

特徴量を重要度でランク付けした後、次の手順ではこれらをエクスポートし、これらの特徴量に基づいて分類モデルを学習させることができるようにします。[エクスポート] をクリックして、[特徴を分類学習器にエクスポート] を選択し、分類に使用する特徴を選択します。ここでは、上位 15 の特徴をエクスポートします。その後、これらの特徴はアプリによって "分類学習器" に送られ、さまざまな故障を特定する分類器の設計に使用できるようになります。

"分類学習器" によって開かれる [ファイルからの新規セッション] ダイアログ ボックスで、5 分割交差検証を確認してセッションを開始します。

"分類学習器" に、単一のモデルの散布図が表示されます。

[分類学習器] タブの [モデル] セクションで、学習用にすべてのモデル タイプを選択します。
[モデル] リストで、[複数] を選択します。次に、[すべてを学習] をクリックします。

学習が完了すると、"分類学習器" には各モデルがモデル番号の順に、モデル検証の精度とともにリストされ、セット内の最初のモデルの混同行列が表示されます。[並べ替え] の順序を Accuracy (Validation) に変更します。

SVM メソッドの分類精度が最も高く、およそ 79% です。プロセスにランダム性があるため、結果にばらつきが生じる場合があります。このモデルを選択し、[混同行列] をクリックします。混同行列は、このメソッドが各故障タイプについてモデルをどの程度うまく分類しているかを示しています。対角上のエントリは、正しく分類されている故障タイプの数を表します。対角を外れたエントリは、予測されたクラスと真のクラスが同じではない故障タイプを表します。精度を上げるために、特徴の数を増やしてみることができます。あるいは、既存の特徴について反復することもできます。別の手順としては、既存の特徴、特にスペクトル特徴について反復し、おそらくはスペクトルの計算方法を変更したり、帯域幅を変更したり、あるいは異なる周波数ピークを使用するなどして、分類の精度を改善することが考えられます。

3 重ポンプの故障の診断
この例では診断特徴デザイナーを使用して特徴の解析と選択を行い、3 重往復ポンプの故障を診断する分類器を作成する方法を説明しました。