アプリで生成された MATLAB コードの構造
診断特徴デザイナーを使用して、選択した特徴および変数の計算を自動化する MATLAB® コードを生成できます。この生成コードは、アプリにインポートしたアンサンブル データと同様に構成された任意のアンサンブル データを受け入れ、新しい特徴テーブルと計算された信号、スペクトル、およびランク付けの各 table を生成します。これらの table は特徴解析またはモデル学習に使用できます。コードでは、アプリ内で設定したさまざまなオプションを複製し、実行できます。
信号全体での各メンバーの信号および特徴の計算
特徴のランク付け
アンサンブルの動作を特徴付けるためのアンサンブルレベルの計算
並列処理
セグメント化された信号の処理 ("フレームベース" 処理とも呼ばれます)
アンサンブル管理は生成コードの基本的な要素です。データ アンサンブルおよびアンサンブル変数の型の詳細については、状態監視と予知保全のためのデータ アンサンブルを参照してください。
アプリで独自のコードを生成することで、この関数の説明と実際のコードを比較できます。詳細については、MATLAB の生成コードを使用した自動特徴抽出を参照してください。コードの生成方法の例については、診断特徴デザイナーでの MATLAB 関数の生成を参照してください。フレームベースのコード生成の設定が提供されている例については、診断特徴デザイナーを使用した劣化システムの特徴の予知ランク付けを参照してください。
基本的な関数フロー
次の図は、生成コードの基本的な関数フローを示します。この図では、関数は特徴と派生変数の両方を返し、逐次処理を使用して、信号全体を処理しています。

この図では、コード フローが次の 3 つの主要なセクションに分けられています。Initialize、Loop through Members、および Create Outputs。
"Initialize" ブロックは、初期設定を行います。具体的な動作は、インポートした元のデータの型、およびコード生成で指定した変数および特徴によって異なります。
"Loop Through Members" ブロックの演算では、一度に 1 つのメンバーずつ、すべての変数および特徴の計算を実行します。
"Create Outputs" では、特徴テーブルおよびアンサンブル全体の抽出および書式設定を行います。
入力
関数は、最初にアプリにインポートしたデータと一致する入力データに対して動作します。アプリからコード生成する予定がある場合、コードを適用する予定のデータと同じ形式でデータをインポートすることをお勧めします。
アンサンブルの table や cell 配列などのワークスペース変数をメモリからインポートした場合、関数ではアンサンブルの table や cell 配列が必要になります。
ファイルまたはシミュレーション アンサンブル データストアをインポートした場合、関数ではファイルまたはシミュレーション アンサンブル データストアが必要になります。
コードの入力データは、アプリにインポートしたデータと同様の変数構造をもっていなければなりません。入力アンサンブルには追加の変数も含めることができます。コードでは追加の変数は無視され、それらにエラーのフラグが付けられることはありません。
初期化
Initialize ブロックのコードは、関数が Loop Through Members ブロックで計算する入力と出力の両方の変数が含まれるアンサンブルを構成します。これらの計算された出力には、コードの生成時に明示的に選択した変数と特徴、およびいずれかの特徴で必要となる tsa 信号などの任意の追加変数が含まれます。
入力データが table または cell 配列の場合、コードは
workspaceEnsembleオブジェクトを作成します。このオブジェクトには、入力データ変数に対応する変数が含まれます。このオブジェクトはアンサンブル データストア オブジェクトと似ていますが、外部ファイルではなくメモリのデータに対して動作します。入力データが
simulationEnsembleDatastoreオブジェクトまたはfileEnsembleDatastoreオブジェクトの場合、コードはオブジェクトに対して直接動作します。
コードは、アンサンブルを初期化後、メンバーの計算時に計算されたすべての変数および特徴を連結します。コードは、関数 unique を使用して、余分な変数を削除します。
次の図は、ワークスペース アンサンブルとそのデータ変数を示しています。データ変数は、入力信号、出力信号、スペクトル、および特徴を特定します。

初期化時におけるアンサンブル関連の主な関数には次のものが含まれます。
reset— アンサンブルは元の未読の状態にリセットされるため、コードは先頭から読み取られるworkspaceEnsemble— メモリ内のデータを管理するアンサンブル オブジェクトfileEnsembleDatastore— 外部ファイルのデータを管理するアンサンブル オブジェクトsimulationEnsembleDatastore— 外部のログまたはファイルのシミュレーション データを管理するアンサンブル オブジェクト
メモ
初期化時、関数は処理中に使用する配列の事前割り当てを行いません。コードは任意のメンバー数の入力アンサンブルに対して動作しなければならないため、事前割り当てを行わないことによって、明確性および柔軟性が確保されます。後続の計算サイクルでは新しく計算されたデータが中間結果 table に追加されますが、その際にコードはインラインのコメント %#ok<AGROW> を使用して、事前割り当てに関する MATLAB コード アナライザーの警告を非表示にします。コード アナライザー メッセージの基本設定の詳細については、コード アナライザーの設定を参照してください。
メンバーの計算ループ
メンバーの計算ループでは、関数は一度に 1 つのメンバーずつ、メンバー固有のすべての計算を実行します。
関数 read の一連の呼び出しによって、ループが開始され、最後のアンサンブル メンバーまで、連続して各アンサンブル メンバーが読み取られます。各 read コマンドに続く計算では、そのメンバーに対して、指定されたすべての変数および特徴が提供されます。
実行されているメンバーレベルの結果 table には、変数または特徴の各セットが計算されると同時に、結果が収集されます。
次の図は、メンバーレベルの結果 table の例を示します。ここで、結果 table には、特徴が含まれる 2 つの table と、計算された信号が含まれる 1 つの timetable が組み込まれています。

すべての計算が完了すると、コードは、すべてのメンバーの結果 table をメイン アンサンブルに追加し直します。
メンバーの計算では、処理できない入力データに対応するために try/catch の組み合わせが使用されます。この方法により、無効なデータによってコード実行が停止することが回避されます。
コードは、次の主要なアンサンブル管理関数を使用します。
read— 次のアンサンブル メンバーを読み取るreadMemberData— 特定の変数について、1 つのアンサンブル メンバーからデータを抽出するwriteToLastMemberRead— アンサンブル メンバーにデータを書き込むtable— 名前付きの列に変数と特徴を含み、行にメンバーを含むアンサンブルの配列array2table— 配列を table に変換するtimetable— 各行について、名前付きの変数列の信号と特定の時刻が含まれる、メンバー固有の特殊な tablearray2timetable— 配列を timetable に変換する
出力
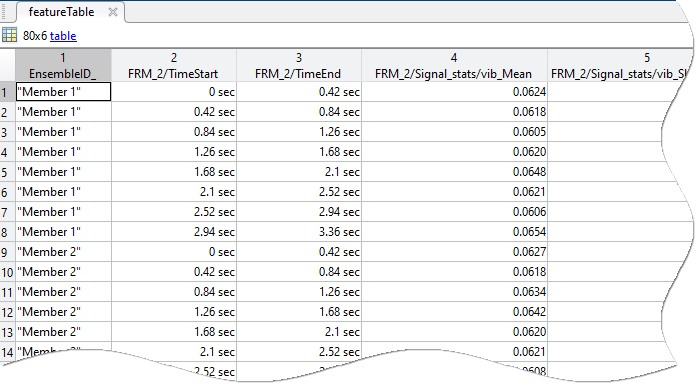
生成された関数は主に特徴テーブルを出力します。コードはこれを関数 readFeatureTable を使用して抽出します。この出力は、ワークスペース アンサンブルとアンサンブル データストアのどちらを入力として使用していても同じです。特徴テーブルには、スカラーの特徴自体と状態変数が含まれます。
次の図は、特徴テーブルの例を示します。各行はメンバーを表します。1 番目の列には状態変数が含まれ、後続列にはスカラーの特徴値が含まれます。

アンサンブル自体を返すには、オプションの 2 番目の出力引数を使用します。関数の入力が table または cell 配列である場合、関数は、関数 readall を使用してワークスペース アンサンブルを table に変換し、table を返します。
次の図は、出力テーブルの例を示します。各行はメンバーを表します。最初の 2 つの列には入力変数、残りの列には特徴また計算された変数が含まれます。

アンサンブル データストア オブジェクトの元々のインポートに基づく関数の場合、関数は更新されたデータストア オブジェクトを返します。
コードには、次の主要な出力関数が含まれます。
readFeatureTable— アンサンブル データセットから table に状態変数および特徴データを読み取るreadall— アンサンブル データセットから table にすべてのデータを読み取る
ランク付け
コード生成時に 1 つ以上のランク付け table を選択する場合、図に示すように、関数には特徴テーブルの抽出に続いてランク付けのセクションが含まれます。次の図は、「基本的な関数フロー」の図から変更されるフロー チャートの部分の詳細のみを示します。次の図の Create Outputs では、ランク付けを使用した場合のすべての出力引数が示されています。

ランク付けを初期化するために、コードは特徴テーブルから特徴値およびラベル (状態変数値) を抽出します。次に、コードは関数 grp2idx を使用してラベルを数値に変換し、各特徴にグループ インデックスを割り当てることで、クラス グループを定義します。たとえば、状態変数 FaultCode に "Faulty"、"Degraded"、および "Healthy" というラベルがあった場合、grp2idx は、これらのラベルをもつメンバーをグループ 1、2、および 3 にグループ化します。
ランク付けの各手法について、コードは次の手順で各特徴のスコアを計算します。
指定した正規化スキームを使用して、特徴を正規化します。
ラベルをマスキングするためのグループインデックスを使用してグループを分け、ランク付け手法の関数を呼び出します。具体的な構文は、ランク付け手法の関数によって異なります。
相関重要度係数を指定した場合、
correlationWeightedScoreを使用してスコアを更新します。相関の重み付けは、高ランクの特徴と高い相関を示す特徴のスコアを下げるため、冗長となります。スコアをスコアリング マトリクスに、メソッドをメソッド リストに追加します。
次に、コードはランク付け table を作成し、sortrows を使用して、コード生成時にアプリで指定した [並べ替え] 手法のスコアで行を並べ替えます。
次の図に、T 検定の結果で並べ替えられた、4 つの特徴のランク付け table の例を示します。

コードは、次の主要な関数を使用してランク付けを管理します。
grp2idx— ラベルを数値に変換するcorrelationWeightedScore— 相関係数を使用して特徴のランク付けスコアの重み付けを行うsortrows— 行をスコアで並べ替えて、特徴のランク付けを行う
アンサンブルの統計値と残差
アンサンブル統計値は、個々のメンバーではなく、アンサンブル全体を表す統計メトリクスです。たとえば、振動信号について、アンサンブルの最大値をアプリで指定できます。結果となる単一メンバーの統計値には、各時間サンプルについて、すべてのメンバーの振動値の中で最大の振動値が含まれます。
特定の変数について、すべてのメンバーの信号から同じアンサンブル メトリクスを減算することで、アンサンブル統計値を使用して残差を計算できます。たとえば、アンサンブルの平均が操作点の平均を表す場合、すべてのメンバーから平均を減算し、操作点周辺の動作を分離します。分離された信号は一種の "残差" となります。
次の図に、平均残差信号に基づき特徴を指定する場合のコード フローを示します。

このフローには、2 つの異なるメンバー ループがあります。1 番目のメンバー ループでは、アンサンブル統計値を計算します。2 番目のメンバー ループでは、信号、スペクトル、および特徴の処理を実行します。フロー チャートでは、2 番目のメンバー処理ループに、残差信号と残差に基づく特徴の処理手順が示されています。
ループ 1: アンサンブル統計値の処理
指定した変数のアンサンブル統計値を計算するために、コードはまず、アキュムレータを維持した状態でメンバー間のループを行います。ループ シーケンスの特定の時点において、アキュムレータには、たとえば次のようなものが含まれます。
それまでに計算された最大信号値
すべてのデータ値の累積和と反復回数
それまでに計算された最小信号値
次の図に、アキュムレータの内容と、変数 mean の累積和と回数の例を示します。

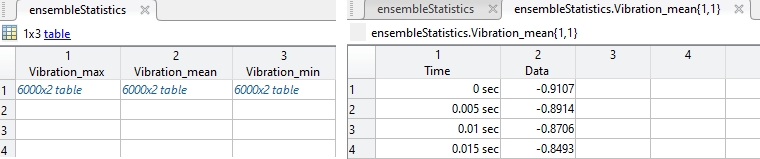
ループ反復の終了時に、コードは、アンサンブルの最大信号と最小信号を、アキュムレータからアンサンブル統計値の最大変数および最小変数に移します。コードは、アンサンブルの合計を回数で除算して、アンサンブル平均を計算します。
次の図に、最終的なアンサンブル統計値 table と、平均信号が含まれる最終的な変数 mean の例を示します。
ループ 2: 残差の処理
メインとなるメンバー処理ループでは、コードは、指定した信号から指定した統計値を減算することによって、残差信号変数を作成し、これらの残差を他の信号や特徴と同じ方法でパッケージ化します。
次の図に、残差が含まれるメンバーの結果 table の例を示します。table には、2 つの残差信号と、これらの信号から計算された 2 つの特徴セットが含まれています。

並列処理
並列処理を指定した場合、コードは図に示すように、アンサンブル メンバーをサブアンサンブルに分割し、各サブアンサンブルについて、メンバー処理ループ全体を並列実行します。

メイン アンサンブルが workspaceEnsemble オブジェクトである場合、各分割処理サイクルの終了時に、コードは更新されたサブアンサンブルを cell として配列に保存します。この配列にはすべてのサブアンサンブルの結果が格納されます。次の図に、この配列と最初の 2 つの cell の例を示します。この図では、各分割に 13 個のメンバーが含まれています。

メイン アンサンブルがワークスペース アンサンブルの場合、すべての分割処理が完了すると、コードは結果として得られた分割を集め直し、refresh コマンドを使用してメイン アンサンブルを更新します。
メイン アンサンブルがアンサンブル データストア オブジェクトの場合、コードは、各メンバー ループの終了時に結果をサブアンサンブル メンバーに書き込む際に、オブジェクトを直接更新します。
コードは、次の主要な関数を使用して並列処理を行います。
numpartitions— アンサンブル メンバーを分割する際の分割数partition— アンサンブルを分割refresh— 分割の結果を集め直して、ワークスペース アンサンブルを更新
フレームベースの処理
フレームベースの処理をアプリで指定した場合、生成コードは、各メンバーの信号全体をセグメント、すなわち "フレーム" に分割します。これらのフレームのサイズと頻度は "フレーム ポリシー" に保存されます。
次の図にフローを示します。コードは、各メンバー ループ内でフレーム ループを実行します。コード生成を行う特徴の選択時、アプリで選択できるフレーム ポリシーは単一に制限されます。そのため、生成される関数に 1 つを超えるフレーム ループが含まれることはありません。

初期化部分では、コードは、入力変数と、FRM_2 などのフレーム ポリシー ID のみをデータ変数に追加します。コードは、計算する変数を追加しません。これらの変数は FRM_ の変数に格納されます。
メンバー ループの最初の部分で、コードは次を行います。
メンバー全体の信号を読み取ります。
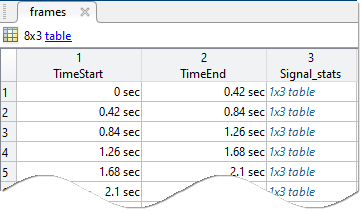
frameintervalsを使用して、信号全体の時間範囲にわたるフレーム間隔 table を作成します。これには、各フレームの開始時間と終了時間が含まれます。メンバー レベルのフレーム table を初期化します。この table には最終的に、メンバーのすべてのフレームについて計算された変数値が含まれます。
メンバー ループの 2 番目の部分はフレーム ループです。各フレームについて、コードは次を行います。
フレーム間隔情報を使用して、信号全体からそのフレームのデータを抽出します。
信号全体の処理の場合と同じ方法で、メンバー レベルで信号、スペクトル、および特徴を計算します。新しい変数を計算するたびに、コードはその変数をフレームの結果 table に追加します。次の図に、メンバーのフレーム table の例を示します。最初の 2 つの要素にはフレーム間隔の開始時間と終了時間が含まれます。最後の要素には、そのフレームについて計算された特徴が含まれます。

変数の計算が完了した後、コードは、完了したフレームの結果 table をメンバーレベルのフレーム table に追加します。次の図に、メンバーレベルの table の例を示します。これには、すべてのメンバーのフレームの結果が含まれています。
メンバー ループの末尾の演算では、完了したメンバーのフレーム table がアンサンブル メンバーに書き込まれます。
特徴テーブルの出力の作成は、各メンバーの変数にすべてのセグメントが含まれる以外は、基本の場合と本質的に同じです。
参考
frameintervals | workspaceEnsemble | grp2idx | readall | correlationWeightedScore | simulationEnsembleDatastore | fileEnsembleDatastore | reset | unique | read | readMemberData | writeToLastMemberRead | refresh