partition
データストアを分割する
構文
説明
例
ファイルの大規模な集合のデータストアを作成します。この例では、サンプル ファイル airlinesmall.csv の 10 個のコピーを使用します。表形式データの欠損フィールドを処理するには、名前と値のペア TreatAsMissing と MissingValue を指定します。
files = repmat({'airlinesmall.csv'},1,10);
ds = tabularTextDatastore(files,...
'TreatAsMissing','NA','MissingValue',0);データストアを 3 つの部分に分割し、最初の区画を返します。関数 partition は、データストア ds から最初の約 1/3 のデータを返します。
subds = partition(ds,3,1);
データストアの Files プロパティには、データストア内のファイルのリストが格納されます。データストア ds の Files プロパティおよび分割されたデータストア subds にあるファイルの数をチェックします。データストア ds には 10 個のファイル、区画 subds には最初の 4 つのファイルが格納されています。
length(ds.Files)
ans = 10
length(subds.Files)
ans = 4
関数 mapreduce の出力ファイルであるサンプル ファイル mapredout.mat からデータストアを作成します。
ds = datastore('mapredout.mat');ds の既定の分割数を取得します。
n = numpartitions(ds);
データストアを既定の数に分割し、最初の分割部分に対応するデータストアを返します。
subds = partition(ds,n,1);
subds 内のデータを読み取ります。
while hasdata(subds) data = read(subds); end
イメージ ファイルを 3 つ含むデータストアを作成します。
ds = imageDatastore({'street1.jpg','peppers.png','corn.tif'})
ds =
ImageDatastore with properties:
Files: {
' ...\folder1\street1.jpg';
' ...\folder1\peppers.png';
' ...\folder1\corn.tif'
}
ReadSize: 1
Labels: {}
ReadFcn: @readDatastoreImage
データストアをファイル別に分割し、2 番目のファイルに対応する部分を返します。
subds = partition(ds,'Files',2)
subds =
ImageDatastore with properties:
Files: {
' ...\folder1\peppers.png'
}
ReadSize: 1
Labels: {}
ReadFcn: @readDatastoreImage
subds にはファイルが 1 つあります。
関数 mapreduce の出力ファイルであるサンプル ファイル mapredout.mat からデータストアを作成します。
ds = datastore('mapredout.mat');並列プール内の 3 個のワーカーに対して、データストアを 3 つの部分に分割します。
numWorkers = 3; p = parpool('local',numWorkers); n = numpartitions(ds,p); parfor ii=1:n subds = partition(ds,n,ii); while hasdata(subds) data = read(subds); end end
粒度の粗い分割と粒度の細かいサブセットを比較します。
ビデオ ファイル xylophone.mp4 のすべてのフレームを読み取り、反復処理するための ArrayDatastore オブジェクトを作成します。結果のオブジェクトには 141 個のフレームがあります。
v = VideoReader("xylophone.mp4"); allFrames = read(v); arrds = arrayDatastore(allFrames,IterationDimension=4,OutputType="cell",ReadSize=4);
隣接するフレームの特定のセットを抽出するために、arrds の粒度の粗い分割を 16 個作成します。9 個のフレームをもつ 2 番目の分割を抽出します。
partds = partition(arrds,16,2); imshow(imtile(partds.readall()))
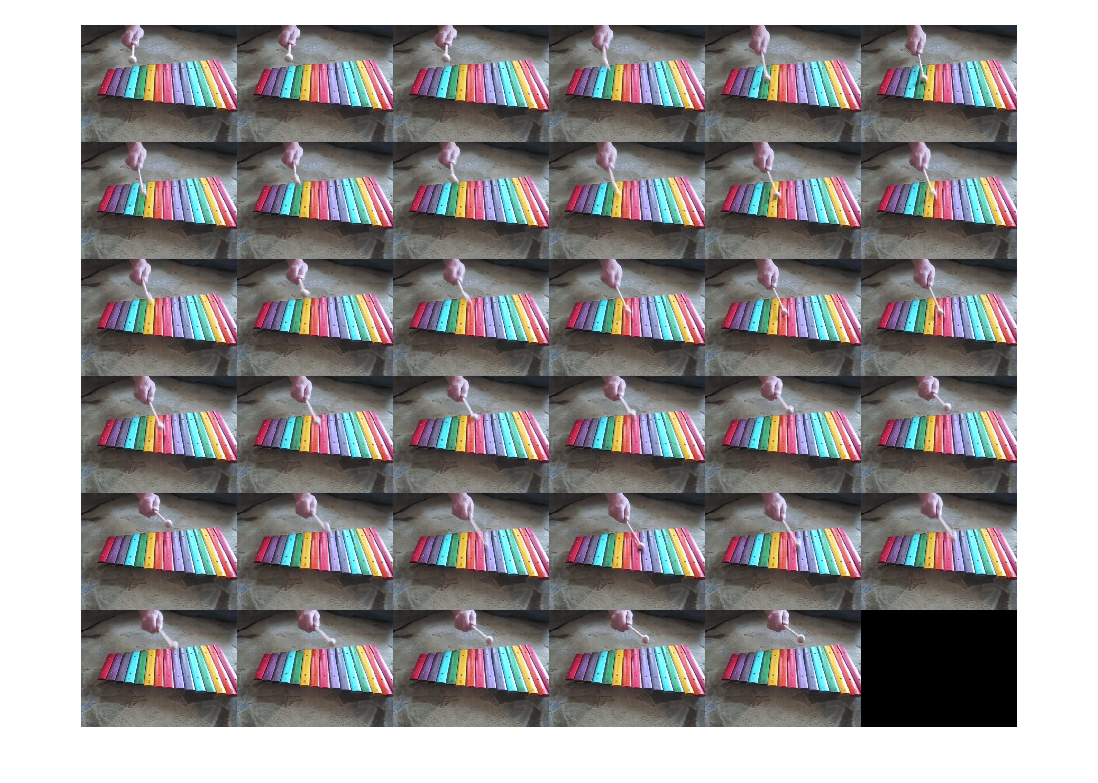
粒度の細かいサブセットを使用して、指定されたインデックスにおける 2 個の隣接しないフレームを arrds から抽出します。
subds = subset(arrds,[67 79]); imshow(imtile(subds.readall()))

入力引数
出力引数
拡張機能
バージョン履歴
R2015a で導入