plotPartialDependence
部分依存プロット (PDP) および個別条件付き期待値 (ICE) プロットの作成
構文
説明
plotPartialDependence( は、RegressionMdl,Vars)Vars にリストされた予測子変数とモデル予測の間の部分依存を計算してプロットします。この構文におけるモデル予測は、予測子データを含む回帰モデル RegressionMdl を使用して予測される応答です。
Varsで 1 つの変数を指定した場合、関数は変数に対する部分依存のライン プロットを作成します。Varsで 2 つの変数を指定した場合、関数は 2 つの変数に対する部分依存の表面プロットを作成します。
plotPartialDependence( は、予測子データが含まれる分類モデル ClassificationMdl,Vars,Labels)ClassificationMdl を使用して、Vars にリストされた予測子変数と、Labels で指定されたクラスのスコアの間の部分依存を計算してプロットします。
Varsで 1 つの変数を指定した場合、関数はLabelsの各クラスの変数に対する部分依存のライン プロットを作成します。Varsで 2 つの変数を指定した場合、関数は 2 つの変数に対する部分依存の表面プロットを作成します。Labelsで 1 つのクラスを指定しなければなりません。
plotPartialDependence( は、予測子データ fun,Vars,Data)Data を使用して、Vars にリストされた予測子変数と、カスタム モデル fun で返される出力の間の部分依存を計算してプロットします。
Varsで 1 つの変数を指定した場合、関数はfunによって返された出力の各列の変数に対する部分依存のライン プロットを作成します。Varsで 2 つの変数を指定した場合、関数は 2 つの変数に対する部分依存の表面プロットを作成します。2 つの変数を指定した場合、funは列ベクトルを返す必要があります。または、名前と値の引数OutputColumnsを設定して使用する出力列を指定する必要があります。
plotPartialDependence(___, は、1 つ以上の名前と値の引数によって指定された追加オプションを使用します。たとえば、Name,Value)"Conditional","absolute" を指定した場合、関数 plotPartialDependence は PDP、選択した予測子変数と予測応答またはスコアの散布図、および各観測値の ICE プロットが含まれている Figure を作成します。
例
carsmall データ セットを使用して回帰木に学習をさせてから、特徴量と学習済み回帰木内の予測応答との間の関係を示す PDP を作成します。
carsmall データ セットを読み込みます。
load carsmall予測子変数 (X) として Weight、Cylinders および Horsepower を、応答変数 (Y) として MPG を指定します。
X = [Weight,Cylinders,Horsepower]; Y = MPG;
X と Y を使用して回帰木に学習させます。
Mdl = fitrtree(X,Y);
学習済み回帰木をグラフィックで表示します。
view(Mdl,"Mode","graph")

1 番目の予測子変数 Weight の PDP を作成します。
plotPartialDependence(Mdl,1)

プロットされたラインは、学習済み回帰木 Mdl における Weight (ラベルは x1) と MPG (ラベルは Y) の間の平均化された部分関係性を表します。x 軸の小目盛りは x1 の一意の値を表します。
回帰木ビューアーには、最初の決定が x1 が 3085.5 より小さいかどうかであることが示されています。PDP でも、x1 = 3085.5 付近に大きい変化が示されています。木ビューアーは、予測子変数に基づいて各ノードにおける各決定を可視化します。x1 の値に基づいて分割されたノードをいくつか見つけることはできますが、x1 に対する Y の従属を把握することは簡単ではありません。しかし、plotPartialDependence は平均化された予測応答を x1 に対してプロットするので、x1 に対する Y の部分依存を明確に把握できます。
ラベル x1 および Y は、予測子名および応答名の既定値です。これらの名前は、fitrtree を使用して Mdl に学習をさせるときに、名前と値の引数 PredictorNames および ResponseName を指定して変更できます。関数 xlabel および ylabel を使用して座標軸のラベルを変更することもできます。
fisheriris データ セットを使って単純ベイズ分類モデルに学習させ、予測子変数と複数クラスの予測スコア (事後確率) の関係を示す PDP を作成します。
fisheriris データ セットを読み込みます。これには 150 本のアヤメの標本について種類 (species) と、がく片の長さ、がく片の幅、花弁の長さ、花弁の幅の測定値 (meas) が含まれています。このデータ セットには、setosa、versicolor および virginica の 3 種類のそれぞれについて 50 個ずつの標本が含まれています。
load fisheriris応答に species、予測子に meas を使用して、単純ベイズ分類モデルに学習させます。
Mdl = fitcnb(meas,species);
3 番目の予測子変数 x3 に対する species の 3 つのクラスすべてについて、Mdl によって予測されるスコアの PDP を作成します。Mdl の ClassNames プロパティを使用して、クラス ラベルを指定します。
plotPartialDependence(Mdl,3,Mdl.ClassNames);
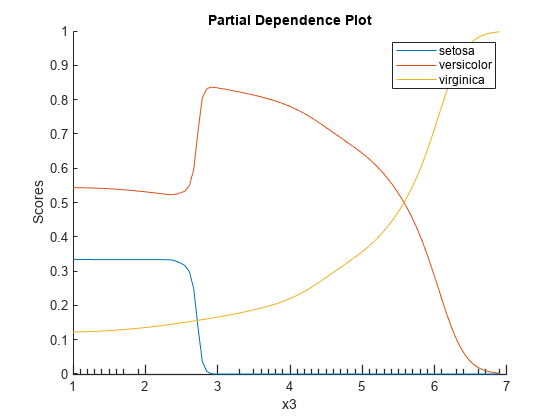
このモデルでは、virginica の確率は x3 にともなって増加しています。setosa の確率は、x3 が 0 から 2.5 付近までは約 0.33 であり、それ以降は確率はほぼ 0 に低下します。
予測子変数間の交互作用が応答変数に含まれている標本データを生成し、このデータを使用してガウス過程回帰モデルに学習をさせます。その後、各観測値について特徴量と予測応答の間の関係を示す ICE プロットを作成します。
標本予測子データ x1 および x2 を生成します。
rng("default") % For reproducibility n = 200; x1 = rand(n,1)*2-1; x2 = rand(n,1)*2-1;
x1 と x2 の間に交互作用が含まれている応答値を生成します。
Y = x1-2*x1.*(x2>0)+0.1*rand(n,1);
[x1 x2] と Y を使用してガウス過程回帰モデルを作成します。
Mdl = fitrgp([x1 x2],Y);
Conditional として "centered" を指定して、1 番目の予測子 x1 についての PDP (赤い線)、x1 と予測応答の散布図 (円マーカー)、および一連の ICE プロット (灰色の線) が含まれている Figure を作成します。
plotPartialDependence(Mdl,1,"Conditional","centered")

Conditional が "centered" である場合、plotPartialDependence はすべてのプロットがゼロから始まるようにプロットのオフセットを設定します。これは、選択した特徴量の累積的な効果を確認するために役立ちます。
PDP は平均化された関係を明らかにするので、特徴量間の交互作用が応答に含まれている場合は特に、隠された依存性は明らかになりません。しかし ICE プロットには、x1 に対する 2 つの異なる応答の依存性が明確に示されます。
分類モデルのアンサンブルに学習させ、2 つの PDP を作成します。1 つには学習データ セットを使用し、もう 1 つには新しいデータ セットを使用します。
census1994 データ セットを読み込みます。これには、<=50K または >50K に分類される米国の年収データと、複数の人口統計変数が含まれます。
load census1994分析する変数のサブセットを table adultdata と adulttest から抽出します。
X = adultdata(:,["age","workClass","education_num","marital_status","race", ... "sex","capital_gain","capital_loss","hours_per_week","salary"]); Xnew = adulttest(:,["age","workClass","education_num","marital_status","race", ... "sex","capital_gain","capital_loss","hours_per_week","salary"]);
関数 fitcensemble を使用し、応答として salary を、予測子として他の変数を指定し、分類器のアンサンブルに学習させます。バイナリ分類の場合、fitcensemble は LogitBoost メソッドを使用して 100 本の分類木を集約します。
Mdl = fitcensemble(X,"salary");Mdl のクラス名を検査します。
Mdl.ClassNames
ans = 2×1 categorical
<=50K
>50K
学習データを使用して、予測子 age に対する salary (>50K) の 2 番目のクラスについて、Mdl によって予測されるスコアの部分依存プロットを作成します。
plotPartialDependence(Mdl,"age",Mdl.ClassNames(2))
table Xnew からの新しい予測子データを使用して、age に対するクラス >50K のスコアの PDP を作成します。
plotPartialDependence(Mdl,"age",Mdl.ClassNames(2),Xnew)
2 つのプロットは、age の salary (>50K) が高い予測スコアの部分依存について類似した形状を示しています。両方のプロットは、高給の予測スコアが 30 歳まで急速に上昇し、その後 60 歳までほぼ横ばいで、その後急速に低下することを示しています。ただし、新しいデータに基づくプロットでは、65 歳以上のスコアがわずかに高くなっています。
isolationForest オブジェクトの予測子と異常スコアの関係を解析するための PDP を作成します。isolationForest オブジェクトを関数 plotPartialDependence に直接渡すことはできません。代わりに、オブジェクトの異常スコアを返すカスタム関数を定義し、その関数を plotPartialDependence に渡します。
census1994.mat に保存されている 1994 年の国勢調査データを読み込みます。このデータ セットは、米国勢調査局の人口統計データから構成されます。
load census1994census1994 には 2 つのデータ セット adultdata および adulttest が含まれています。
adulttest 用に孤立森モデルに学習させます。関数 iforest は、IsolationForest オブジェクトを返します。
rng("default") % For reproducibility Mdl = iforest(adulttest);
IsolationForest の関数 isanomaly によって計算された異常スコアを返すカスタム関数 myAnomalyScores を定義します。このカスタム関数の定義は、この例の終わりで示します。
adulttest データ セットの変数 age に対する異常スコアの PDP を作成します。plotPartialDependence は、関数ハンドルの形式のカスタム モデルを受け入れます。関数ハンドルで表される関数は予測子データを受け入れ、観測値ごとに 1 つの行をもつ列ベクトルまたは行列を返す必要があります。カスタム モデルを @(tbl)myAnomalyScores(Mdl,tbl) として指定し、カスタム関数で学習済みモデル Mdl が使用されて予測子データが受け入れられるようにします。
plotPartialDependence(@(tbl)myAnomalyScores(Mdl,tbl),"age",adulttest) xlabel("Age") ylabel("Anomaly Score")

カスタム関数 myAnomalyScores
function scores = myAnomalyScores(Mdl,tbl) [~,scores] = isanomaly(Mdl,tbl); end
carsmall データ セットを使用してアンサンブル回帰に学習をさせ、新しいデータ セット carbig を使用して各予測子変数について PDP プロットと ICE プロットを作成します。その後、Figure を比較して予測子変数の重要度を分析します。また、関数 predictorImportance によって返される予測子の重要度の推定値と結果を比較します。
carsmall データ セットを読み込みます。
load carsmall予測子変数 (X) として Weight、Cylinders、Horsepower および Model_Year を、応答変数 (Y) として MPG を指定します。
X = [Weight,Cylinders,Horsepower,Model_Year]; Y = MPG;
X と Y を使用してアンサンブル回帰に学習をさせます。
Mdl = fitrensemble(X,Y, ... "PredictorNames",["Weight","Cylinders","Horsepower","Model Year"], ... "ResponseName","MPG");
plotPartialDependence 関数とpredictorImportance関数を使用して、予測子変数の重要度を調べます。関数 plotPartialDependence は、選択した予測子と予測応答の間の関係を可視化します。predictorImportance は、予測子の重要度を単一の値で要約します。
plotPartialDependence を使用し "Conditional","absolute" を指定して、各予測子についての PDP プロット (赤い線) と ICE プロット (灰色の線) が含まれている Figure を作成します。各 Figure には、選択した予測子と予測応答の散布図 (円マーカー) も含まれています。また、carbig データ セットを読み込み、新しい予測子データ Xnew として使用します。Xnew が指定された場合、関数 plotPartialDependence は Mdl 内の予測子データではなく Xnew を使用します。
load carbig Xnew = [Weight,Cylinders,Horsepower,Model_Year]; figure t = tiledlayout(2,2,"TileSpacing","compact"); title(t,"Individual Conditional Expectation Plots") for i = 1 : 4 nexttile plotPartialDependence(Mdl,i,Xnew,"Conditional","absolute") title("") end

predictorImportance を使用して、予測子の重要度の推定値を計算します。この関数は、すべての予測子について分割によって生じる平均二乗誤差 (MSE) の変動を合計し、その合計を枝ノードの数で除算します。
imp = predictorImportance(Mdl); figure bar(imp) title("Predictor Importance Estimates") ylabel("Estimates") xlabel("Predictors") ax = gca; ax.XTickLabel = Mdl.PredictorNames;

予測子の重要度によると、MPG に対する効果が最も大きいのは変数 Weight です。Weight の PDP も、MPG は Weight に対する部分的従属性が高いことを示しています。予測子の重要度によると、MPG に対する効果が最も小さいのは変数 Cylinders です。Cylinders の PDP も、Cylinders による MPG の変動が小さいことを示しています。
予測子の線形項と交互作用項の両方を使用して一般化加法モデル (GAM) に学習させます。その後、線形項と交互作用項の両方を含む PDP と線形項のみを含む PDP を作成します。PDP を作成する際に交互作用項を含めるかどうかを指定します。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphere予測子 X とクラス ラベル Y を使用して、GAM に学習させます。クラス名を指定することが推奨されます。上位 10 個の最も重要な交互作用項を含めるように指定します。
Mdl = fitcgam(X,Y,"ClassNames",{'b','g'},"Interactions",10);
Mdl は ClassificationGAM モデル オブジェクトです。
Mdl の交互作用項の一覧を表示します。
Mdl.Interactions
ans = 10×2
1 5
7 8
6 7
5 6
5 7
5 8
3 5
4 7
1 7
4 5
Interactions の各行は 1 つの交互作用項を表し、交互作用項の予測子変数の列インデックスを格納します。
交互作用項で最も頻度が高い予測子を調べます。
mode(Mdl.Interactions,"all")ans = 5
交互作用項で最も頻度が高い予測子は 5 番目の予測子 (x5) です。5 番目の予測子についての PDP を作成します。2 つ目の PDP では、計算から交互作用項を除外するために "IncludeInteractions",false を指定します。
plotPartialDependence(Mdl,5,Mdl.ClassNames(1)) hold on plotPartialDependence(Mdl,5,Mdl.ClassNames(1),"IncludeInteractions",false) grid on legend("Linear and interaction terms","Linear terms only") title("PDPs of Posterior Probabilities for 5th Predictor") hold off
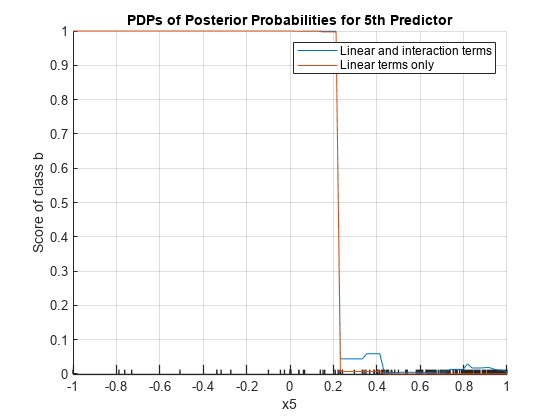
このプロットは、x5 のスコア (事後確率) の部分依存はモデルに交互作用項が含まれているかどうかによって異なり、特に 0.2 から 0.45 までの x5 で大きく異なることを示しています。
carsmall データ セットを使用してサポート ベクター マシン (SVM) 回帰モデルに学習をさせ、2 つの予測子変数について PDP を作成します。その後、plotPartialDependence の出力から部分依存の推定値を抽出します。または、関数partialDependenceを使用して、部分依存の値を取得することもできます。
carsmall データ セットを読み込みます。
load carsmall予測子変数 (Tbl) として Weight、Cylinders、Displacement および Horsepower を指定します。
Tbl = table(Weight,Cylinders,Displacement,Horsepower);
Tbl と応答変数 MPG を使用して、SVM 回帰モデルを構築します。自動カーネル スケールのガウス カーネル関数を使用します。
Mdl = fitrsvm(Tbl,MPG,"ResponseName","MPG", ... "CategoricalPredictors","Cylinders","Standardize",true, ... "KernelFunction","gaussian","KernelScale","auto");
予測子変数 Weight および Cylinders に対する予測応答 (MPG) の部分依存を可視化する PDP を作成します。クエリ点を指定し、名前と値の引数 QueryPoints を使用して Weight の部分依存を計算します。Cylinders はカテゴリカル変数であるため、QueryPoints の値は指定できません。plotPartialDependence ではすべての categorical 値を使用します。
pt = linspace(min(Weight),max(Weight),50)'; ax = plotPartialDependence(Mdl,["Weight","Cylinders"],"QueryPoints",{pt,[]}); view(140,30) % Modify the viewing angle

PDP には、Weight と Cylinders の間の交互作用効果が示されています。Weight に対する MPG の部分依存は、Cylinders の値に応じて変化します。
Weight と Cylinders に対する MPG の部分依存の推定値を抽出します。ax.Children の XData、YData および ZData の値はそれぞれ、x 軸の値 (1 番目に選択された予測子の値)、y 軸の値 (2 番目に選択された予測子の値) および z 軸の値 (対応する部分依存の値) です。
xval = ax.Children.XData; yval = ax.Children.YData; zval = ax.Children.ZData;
または、関数partialDependenceを使用して、部分依存の値を取得することもできます。
[pd,x,y] = partialDependence(Mdl,["Weight","Cylinders"],"QueryPoints",{pt,[]});
pd にはクエリ点 x と y の部分依存の値が含まれます。
Conditional として "absolute" を指定した場合、plotPartialDependence は PDP、散布図および一連の ICE プロットが含まれている Figure を作成します。ax.Children(1) と ax.Children(2) はそれぞれ PDP と散布図に対応します。ax.Children の残りの要素は ICE プロットに対応します。ax.Children(i) の XData および YData の値はそれぞれ、x 軸の値 (選択された予測子の値) および y 軸の値 (対応する部分依存の値) です。
入力引数
名前と値の引数
出力引数
詳細
アルゴリズム
回帰モデル (RegressionMdl) と分類モデル (ClassificationMdl) の両方で、plotPartialDependence は、関数 predict を使用して応答またはスコアを予測します。plotPartialDependence は、モデルに従って適切な関数 predict を選択し、既定の設定で predict を実行します。各関数 predict の詳細については、次の 2 つの表の関数 predict を参照してください。指定したモデルが木ベースのモデル (木のブースティング アンサンブルを除く) で Conditional が "none" の場合、plotPartialDependence は関数 predict ではなく重み付き走査アルゴリズムを使用します。詳細については、重み付き走査アルゴリズムを参照してください。
回帰モデル オブジェクト
| モデル タイプ | 完全またはコンパクトな回帰モデル オブジェクト | 応答を予測する関数 |
|---|---|---|
| 決定木のアンサンブルのバギング | CompactTreeBagger | predict |
| 決定木のアンサンブルのバギング | TreeBagger | predict |
| 回帰モデルのアンサンブル | RegressionEnsemble, RegressionBaggedEnsemble, CompactRegressionEnsemble | predict |
| ランダムな特徴量拡張を使用したガウス カーネル回帰モデル | RegressionKernel | predict |
| ガウス過程回帰 | RegressionGP, CompactRegressionGP | predict |
| 一般化加法モデル | RegressionGAM, CompactRegressionGAM | predict |
| 一般化線形混合効果モデル | GeneralizedLinearMixedModel | predict |
| 一般化線形モデル | GeneralizedLinearModel, CompactGeneralizedLinearModel | predict |
| 線形混合効果モデル | LinearMixedModel | predict |
| 線形回帰 | LinearModel, CompactLinearModel | predict |
| 高次元データの線形回帰 | RegressionLinear | predict |
| ニューラル ネットワーク回帰モデル | RegressionNeuralNetwork, CompactRegressionNeuralNetwork | predict |
| 非線形回帰 | NonLinearModel | predict |
| 打ち切り線形回帰 | CensoredLinearModel, CompactCensoredLinearModel | predict |
| 回帰木 | RegressionTree, CompactRegressionTree | predict |
| サポート ベクター マシン | RegressionSVM, CompactRegressionSVM | predict |
| XGBoost 回帰 | CompactRegressionXGBoost | predict |
分類モデル オブジェクト
| モデル タイプ | 完全またはコンパクトな分類モデル オブジェクト | ラベルとスコアを予測する関数 |
|---|---|---|
| 判別分析分類器 | ClassificationDiscriminant, CompactClassificationDiscriminant | predict |
| サポート ベクター マシンまたはその他の分類器用のマルチクラス モデル | ClassificationECOC, CompactClassificationECOC | predict |
| 分類用のアンサンブル学習器 | ClassificationEnsemble, CompactClassificationEnsemble, ClassificationBaggedEnsemble | predict |
| ランダムな特徴量拡張を使用したガウス カーネル分類モデル | ClassificationKernel | predict |
| 一般化加法モデル | ClassificationGAM, CompactClassificationGAM | predict |
| k 最近傍モデル | ClassificationKNN | predict |
| 線形分類モデル | ClassificationLinear | predict |
| 単純ベイズ モデル | ClassificationNaiveBayes, CompactClassificationNaiveBayes | predict |
| ニューラル ネットワーク分類器 | ClassificationNeuralNetwork, CompactClassificationNeuralNetwork | predict |
| 1 クラスおよびバイナリ分類用のサポート ベクター マシン | ClassificationSVM, CompactClassificationSVM | predict |
| マルチクラス分類用の二分決定木 | ClassificationTree, CompactClassificationTree | predict |
| 決定木のバギング アンサンブル | TreeBagger, CompactTreeBagger | predict |
| XGBoost 分類 | CompactClassificationXGBoost | predict |
代替機能
partialDependenceは可視化せずに部分依存を計算します。この関数は、1 回の関数呼び出しで 2 つの変数と複数クラスの部分依存を計算できます。
参照
[3] Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. The Elements of Statistical Learning. New York, NY: Springer New York, 2001.