predictorImportance
回帰木の予測子の重要度の推定
説明
例
データ内のすべての予測子変数について予測子の重要度を推定します。
carsmall データ セットを読み込みます。
load carsmallAcceleration、Cylinders、Displacement、Horsepower、Model_Year、および Weight を予測子として使用して、MPG の回帰木を成長させます。
X = [Acceleration Cylinders Displacement Horsepower Model_Year Weight]; tree = fitrtree(X,MPG);
すべての予測子変数について予測子の重要度を推定します。
imp = predictorImportance(tree)
imp = 1×6
0.0647 0.1068 0.1155 0.1411 0.3348 2.6565
最後の予測子 Weight は、燃費に対する影響が最も大きくなっています。予測に対する影響が最も小さい予測子は、最初の変数 Acceleration です。
代理分岐が含まれている回帰木で、データに含まれているすべての変数について予測子の重要度を推定します。
carsmall データ セットを読み込みます。
load carsmallAcceleration、Cylinders、Displacement、Horsepower、Model_Year、および Weight を予測子として使用して、MPG の回帰木を成長させます。代理分岐を識別するように指定します。
X = [Acceleration Cylinders Displacement Horsepower Model_Year Weight];
tree = fitrtree(X,MPG,Surrogate="on");すべての予測子変数について予測子の重要度を推定します。
imp = predictorImportance(tree)
imp = 1×6
1.0449 2.4560 2.5570 2.5788 2.0832 2.8938
imp を予測子の重要度の推定の結果と比較すると、燃費に対する影響が最も大きいのは依然として Weight ですが、Cylinders は 4 番目に重要な予測子になっています。
carsmall データ セットを読み込みます。与えられた加速、気筒数、エンジン排気量、馬力、製造業者、モデル年および重量に対して自動車の燃費の平均を予測するモデルを考えます。Cylinders、Mfg および Model_Year はカテゴリカル変数であるとします。
load carsmall Cylinders = categorical(Cylinders); Mfg = categorical(cellstr(Mfg)); Model_Year = categorical(Model_Year); X = table(Acceleration,Cylinders,Displacement,Horsepower,Mfg, ... Model_Year,Weight,MPG);
カテゴリカル変数で表現されるカテゴリの個数を表示します。
numCylinders = numel(categories(Cylinders))
numCylinders = 3
numMfg = numel(categories(Mfg))
numMfg = 28
numModelYear = numel(categories(Model_Year))
numModelYear = 3
Cylinders と Model_Year には 3 つしかカテゴリがないので、予測子分割アルゴリズムの標準 CART ではこの 2 つの変数よりも連続予測子が分割されます。
データ セット全体を使用して回帰木に学習をさせます。偏りの無い木を成長させるため、予測子の分割に曲率検定を使用するよう指定します。データには欠損値が含まれているので、代理分岐を使用するよう指定します。
Mdl = fitrtree(X,"MPG",PredictorSelection="curvature",Surrogate="on");
すべての予測子について分割によるリスク変動を合計し、この合計を枝ノード数で除算することにより、予測子の重要度の値を推定します。棒グラフを使用して推定を比較します。
imp = predictorImportance(Mdl); figure bar(imp) title("Predictor Importance Estimates") ylabel("Estimates") xlabel("Predictors") h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = "none";
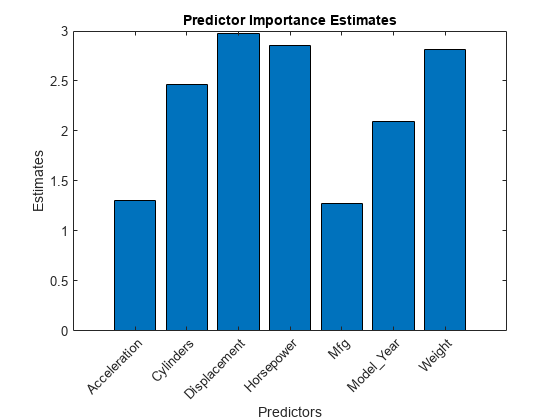
このケースでは、最も重要な予測子は Displacement であり、次に重要なのは Horsepower です。
入力引数
詳細
拡張機能
バージョン履歴
R2011a で導入