predict
ガウス カーネル分類モデルのラベルの予測
説明
例
バイナリ カーネル分類モデルを使用して学習セットのラベルを予測し、生成された分類の混同行列を表示します。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphereレーダー反射が不良 ('b') と良好 ('g') のどちらであるかを識別するバイナリ カーネル分類モデルに学習をさせます。
rng('default') % For reproducibility Mdl = fitckernel(X,Y);
Mdl は ClassificationKernel モデルです。
学習セット (再代入) のラベルを予測します。
label = predict(Mdl,X);
混同行列を作成します。
ConfusionTrain = confusionchart(Y,label);
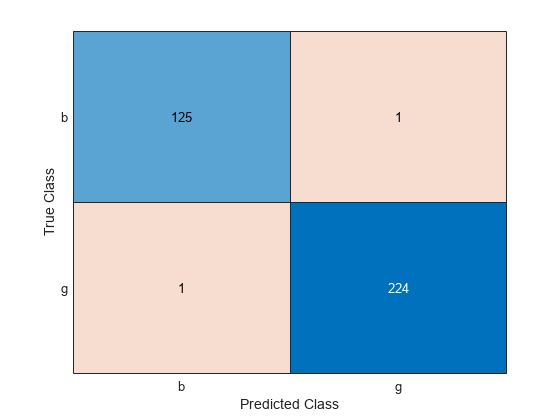
このモデルは、各クラスについて 1 つずつのレーダー反射を誤分類します。
バイナリ カーネル分類モデルを使用してテスト セットのラベルを予測し、生成された分類の混同行列を表示します。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphereデータ セットを学習セットとテスト セットに分割します。テスト セット用に 15% のホールドアウト標本を指定します。
rng('default') % For reproducibility Partition = cvpartition(Y,'Holdout',0.15); trainingInds = training(Partition); % Indices for the training set testInds = test(Partition); % Indices for the test set
学習セットを使用してバイナリ カーネル分類モデルに学習をさせます。クラスの順序を定義することをお勧めします。
Mdl = fitckernel(X(trainingInds,:),Y(trainingInds),'ClassNames',{'b','g'});
学習セットのラベルとテスト セットのラベルを予測します。
labelTrain = predict(Mdl,X(trainingInds,:)); labelTest = predict(Mdl,X(testInds,:));
学習セットの混同行列を作成します。
ConfusionTrain = confusionchart(Y(trainingInds),labelTrain);
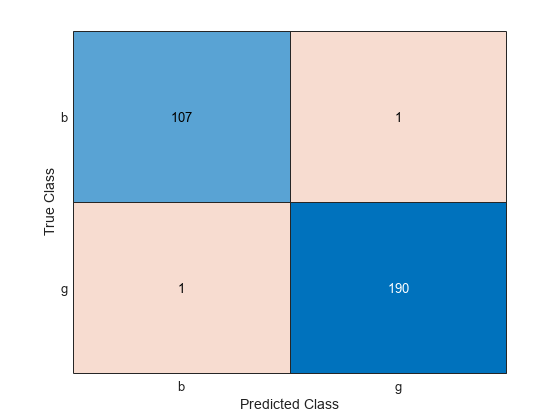
このモデルは、各クラスについて 1 つずつのレーダー反射のみを誤分類します。
テスト セットの混同行列を作成します。
ConfusionTest = confusionchart(Y(testInds),labelTest);
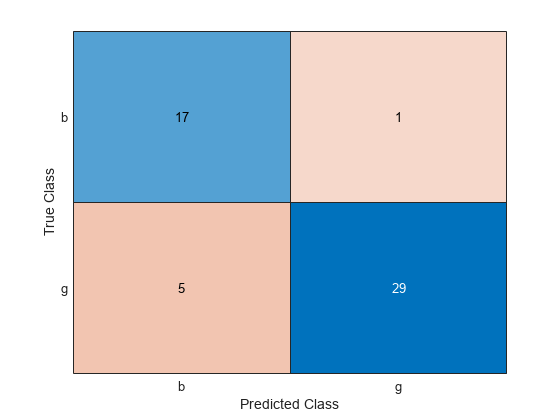
このモデルは、1 つの不良なレーダー反射を良好な反射として、5 つの良好なレーダー反射を不良な反射として誤分類します。
テスト セットの事後クラス確率を推定し、受信者動作特性 (ROC) 曲線をプロットしてモデルの品質を判断します。カーネル分類モデルは、ロジスティック回帰学習器の場合のみ事後確率を返します。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphereデータ セットを学習セットとテスト セットに分割します。テスト セット用に 30% のホールドアウト標本を指定します。
rng('default') % For reproducibility Partition = cvpartition(Y,'Holdout',0.30); trainingInds = training(Partition); % Indices for the training set testInds = test(Partition); % Indices for the test set
バイナリ カーネル分類モデルに学習をさせます。ロジスティック回帰学習器を当てはめます。
Mdl = fitckernel(X(trainingInds,:),Y(trainingInds), ... 'ClassNames',{'b','g'},'Learner','logistic');
テスト セットの事後クラス確率を予測します。
[~,posterior] = predict(Mdl,X(testInds,:));
Mdl 内の正則化強度は 1 つなので、出力 posterior は列数が 2 で行数がテスト セットの観測値数と同じである行列になります。列 i には、与えられた特定の観測値に対する Mdl.ClassNames(i) の事後確率が格納されます。
rocmetricsオブジェクトを作成し、ROC 曲線のパフォーマンス メトリクス (真陽性率と偽陽性率) を計算して ROC 曲線の下の領域 (AUC) の値を求めます。
rocObj = rocmetrics(Y(testInds),posterior,Mdl.ClassNames);
rocmetrics の関数 plot を使用して、2 番目のクラスの ROC 曲線をプロットします。
plot(rocObj,ClassNames=Mdl.ClassNames(2))
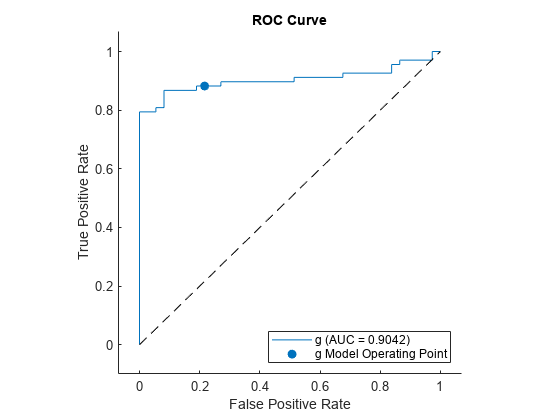
AUC は 1 に近いので、モデルによるラベルの予測精度が高いことがわかります。