confusionchart
分類問題用の混同行列チャートの作成
構文
説明
confusionchart( は、真のラベル trueLabels,predictedLabels)trueLabels および予測ラベル predictedLabels から混同行列チャートを作成し、ConfusionMatrixChart オブジェクトを返します。混同行列の行は真のクラスに対応し、列は予測クラスに対応します。対角線および対角線外のセルは、それぞれ正しく分類された観測値および誤分類された観測値に対応します。作成した混同行列チャートを変更するには、cm を使用します。プロパティの一覧については、ConfusionMatrixChart のプロパティ を参照してください。
confusionchart( は、数値混同行列 m)m から混同行列チャートを作成します。ワークスペースに数値混同行列が既に存在する場合は、この構文を使用します。
confusionchart( は、"x" 軸と "y" 軸に表示されるクラス ラベルを指定します。ワークスペースに数値混同行列とクラス ラベルが既に存在する場合は、この構文を使用します。m,classLabels)
confusionchart( は、parent,___)parent で指定された Figure、パネル、またはタブに混同チャートを作成します。
confusionchart(___, は、1 つ以上の名前と値のペアの引数を使用して、追加の Name,Value)ConfusionMatrixChart プロパティを指定します。プロパティは、他のすべての入力引数の後で指定します。プロパティの一覧については、ConfusionMatrixChart のプロパティ を参照してください。
cm = confusionchart(___)ConfusionMatrixChart オブジェクトを返します。作成したチャートのプロパティを変更するには、cm を使用します。プロパティの一覧については、ConfusionMatrixChart のプロパティ を参照してください。
例
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris
X = meas;
Y = species;X は、150 本のアヤメについて 4 つの測定値が含まれている数値行列です。Y は、対応するアヤメの種類が含まれている文字ベクトルの cell 配列です。
k 最近傍 (KNN) 分類器に学習させます。ここで、予測子の最近傍の個数 (k) は 5 です。数値予測子データを標準化することをお勧めします。
Mdl = fitcknn(X,Y,'NumNeighbors',5,'Standardize',1);
学習データのラベルを予測します。
predictedY = resubPredict(Mdl);
真のラベル Y と予測ラベル predictedY から混同行列チャートを作成します。
cm = confusionchart(Y,predictedY);
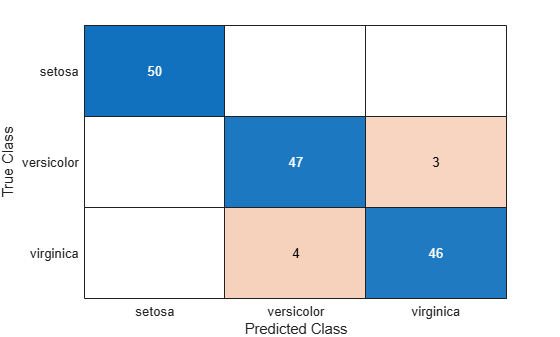
混同行列では、観測値の総数が各セルに表示されます。混同行列の行は真のクラスに、列は予測クラスに対応します。対角線および対角線外のセルは、それぞれ正しく分類された観測値および誤分類された観測値に対応します。
既定では、confusionchart は sort によって定義される自然な順序にクラスを並べ替えます。この例では、クラス ラベルが文字ベクトルなので、confusionchart はクラスをアルファベット順に並べ替えます。指定した順序または混同行列の値でクラスを並べ替えるには、sortClasses を使用します。
NormalizedValues プロパティには、混同行列の値が格納されています。ドット表記を使用して、これらの値を表示します。
cm.NormalizedValues
ans = 3×3
50 0 0
0 47 3
0 4 46
プロパティ値を変更して、混同行列チャートの外観と動作を変更します。タイトルを追加します。
cm.Title = 'Iris Flower Classification Using KNN';列と行の要約を追加します。
cm.RowSummary = 'row-normalized'; cm.ColumnSummary = 'column-normalized';
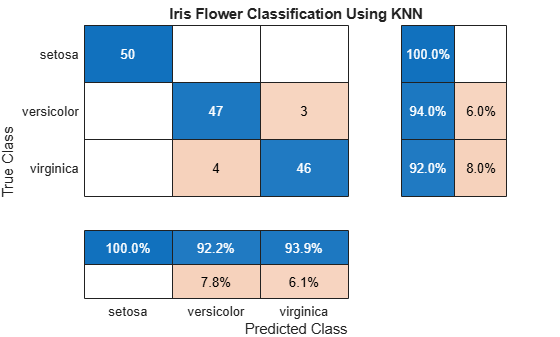
行正規化による行要約では、真のクラスのそれぞれについて、正しく分類された観測値と誤って分類された観測値の割合が表示されます。列正規化による列要約では、各予測クラスについて、正しく分類された観測値と誤って分類された観測値の割合が表示されます。
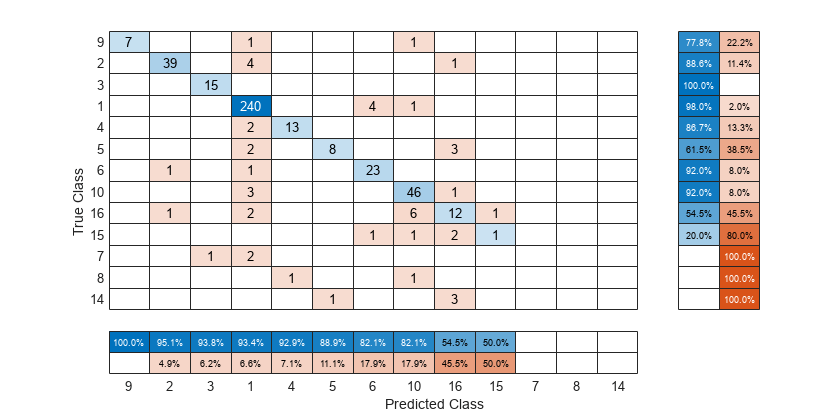
混同行列チャートを作成し、クラス単位の真陽性率 (再現率) またはクラス単位の陽性の予測値 (精度) に従ってチャートのクラスを並べ替えます。
arrhythmia データ セットを読み込み検証します。
load arrhythmia
isLabels = unique(Y);
nLabels = numel(isLabels)nLabels = 13
tabulate(categorical(Y))
Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
不整脈のさまざまな段階を表す 16 個の異なるラベルがデータに含まれていますが、応答 (Y) には 13 個の異なるラベルのみが含まれています。
分類木に学習をさせ、木の再代入応答を予測します。
Mdl = fitctree(X,Y); predictedY = resubPredict(Mdl);
真のラベル Y と予測ラベル predictedY から混同行列チャートを作成します。真陽性率と偽陽性率を行要約に表示するため、'RowSummary' として 'row-normalized' を指定します。また、陽性の予測値と偽発見率を列要約に表示するため、'ColumnSummary' として 'column-normalized' を指定します。
fig = figure; cm = confusionchart(Y,predictedY,'RowSummary','row-normalized','ColumnSummary','column-normalized');
混同チャートのコンテナーのサイズを変更して、パーセントが行要約に表示されるようにします。
fig_Position = fig.Position; fig_Position(3) = fig_Position(3)*1.5; fig.Position = fig_Position;
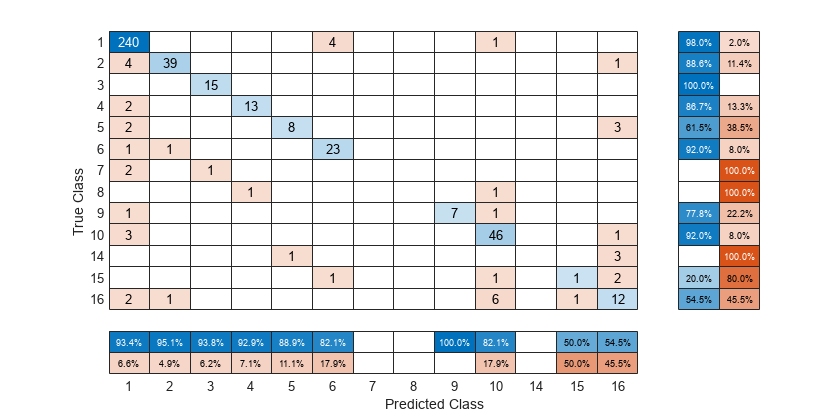
真陽性率に従って混同行列を並べ替えるため、Normalization プロパティを 'row-normalized' に設定することにより各行でセルの値を正規化してから、sortClasses を使用します。並べ替えた後で、観測値の総数を各セルに表示するため、Normalization プロパティを 'absolute' にリセットします。
cm.Normalization = 'row-normalized'; sortClasses(cm,'descending-diagonal') cm.Normalization = 'absolute';
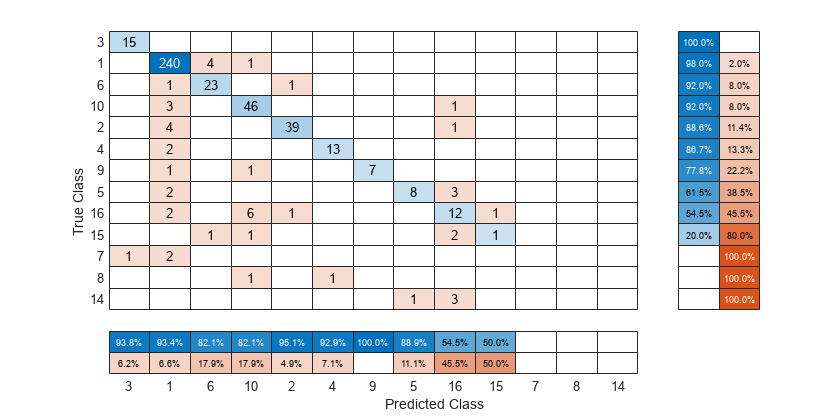
陽性の予測値に従って混同行列を並べ替えるため、Normalization プロパティを 'column-normalized' に設定することにより各列でセルの値を正規化してから、sortClasses を使用します。並べ替えた後で、観測値の総数を各セルに表示するため、Normalization プロパティを 'absolute' にリセットします。
cm.Normalization = 'column-normalized'; sortClasses(cm,'descending-diagonal') cm.Normalization = 'absolute';
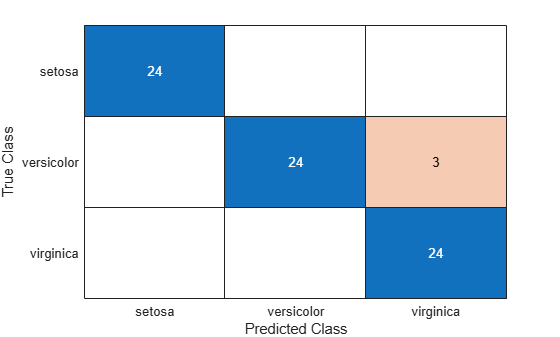
フィッシャーのアヤメのデータ セットの tall 配列に対して分類を実行します。関数 confusionchart を使用して、既知の tall ラベルと予測した tall ラベルに対する混同行列チャートを計算します。
tall 配列に対する計算を実行する場合、MATLAB® は並列プール (Parallel Computing Toolbox™ がある場合は既定) またはローカルの MATLAB セッションを使用します。Parallel Computing Toolbox がある場合にローカルの MATLAB セッションを使用して例を実行するには、関数 mapreducer を使用してグローバルな実行環境を変更します。
mapreducer(0)
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheririsインメモリ配列 meas および species を tall 配列に変換します。
tx = tall(meas); ty = tall(species);
tall 配列内の観測値の個数を求めます。
numObs = gather(length(ty)); % gather collects tall array into memory再現性を得るために rng と tallrng を使用して乱数発生器のシードを設定し、学習標本を無作為に選択します。tall 配列の場合、ワーカーの個数と実行環境によって結果が異なる可能性があります。詳細については、コードの実行場所の制御を参照してください。
rng('default') tallrng('default') numTrain = floor(numObs/2); [txTrain,trIdx] = datasample(tx,numTrain,'Replace',false); tyTrain = ty(trIdx);
決定木分類器モデルを学習標本に当てはめます。
mdl = fitctree(txTrain,tyTrain);
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 2: Completed in 0.73 sec - Pass 2 of 2: Completed in 0.74 sec Evaluation completed in 2.2 sec Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 4: Completed in 0.42 sec - Pass 2 of 4: Completed in 0.47 sec - Pass 3 of 4: Completed in 0.51 sec - Pass 4 of 4: Completed in 0.62 sec Evaluation completed in 2.5 sec Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 4: Completed in 0.17 sec - Pass 2 of 4: Completed in 0.22 sec - Pass 3 of 4: Completed in 0.24 sec - Pass 4 of 4: Completed in 0.26 sec Evaluation completed in 1.1 sec Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 4: Completed in 0.19 sec - Pass 2 of 4: Completed in 0.19 sec - Pass 3 of 4: Completed in 0.22 sec - Pass 4 of 4: Completed in 0.26 sec Evaluation completed in 1.1 sec Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 4: Completed in 0.18 sec - Pass 2 of 4: Completed in 0.18 sec - Pass 3 of 4: Completed in 0.21 sec - Pass 4 of 4: Completed in 0.19 sec Evaluation completed in 1 sec
学習済みのモデルを使用して、テスト標本のラベルを予測します。
txTest = tx(~trIdx,:); label = predict(mdl,txTest);
生成された分類について混同行列チャートを作成します。
tyTest = ty(~trIdx); cm = confusionchart(tyTest,label)
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.18 sec Evaluation completed in 0.44 sec Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.29 sec Evaluation completed in 0.44 sec
cm =
ConfusionMatrixChart with properties:
NormalizedValues: [3×3 double]
ClassLabels: {3×1 cell}
Show all properties
この混同行列チャートは、versicolor クラスの測定値の 3 つが誤分類されたことを示しています。setosa および virginica に属している測定は、すべて正しく分類されています。
入力引数
名前と値の引数
出力引数
制限
ConfusionMatrixChartオブジェクトでは、MATLAB® コード生成がサポートされていません。