rocmetrics
説明
分類モデルの性能を受信者動作特性 (ROC) 曲線またはその他のパフォーマンス メトリクスを使用して評価するには、rocmetrics オブジェクトを作成します。rocmetrics は、バイナリ問題とマルチクラス問題の両方をサポートします。
rocmetrics は、各クラスについて、1 対他の ROC 曲線のパフォーマンス メトリクスを計算します。平均 ROC 曲線のメトリクスは、関数 average を使用して計算できます。ROC 曲線のメトリクスを計算した後、関数 plot を使用してそれらをプロットできます。
rocmetrics は、ROC 曲線を取得するために、既定では偽陽性率 (FPR) と真陽性率 (TPR) を計算します。追加のメトリクスを計算する場合は、オブジェクトの作成時に名前と値の引数 AdditionalMetrics を指定するか、オブジェクトの作成後に関数 addMetrics を呼び出して指定できます。計算されたメトリクスは、rocmetrics オブジェクトの Metrics プロパティに格納されます。
R2024b において: auc 関数を使用して ROC 曲線の下の領域 (AUC) を求めることができます。
rocmetrics は、NumBootstraps の値を正の整数に設定するか、真のクラス ラベル (Labels)、分類スコア (Scores)、および観測値の重み (Weights) の交差検証データを指定すると、パフォーマンス メトリクスの点単位の信頼区間を計算します。詳細については、点単位の信頼区間を参照してください。
作成
構文
説明
rocObj = rocmetrics(Labels,Scores,ClassNames)Labels の真のクラス ラベルと Scores の分類スコアを使用して rocmetrics オブジェクトを作成します。Labels は長さ n のベクトルとして指定し、Scores は n 行 K 列のサイズの行列として指定します。ここで、n は観測値の数、K はクラスの数です。ClassNames は、Scores における列の順序を指定します。
Metrics プロパティに、Scores と ClassNames を指定した各クラスについてのパフォーマンス メトリクスが格納されます。
Labels と Scores で交差検証データを cell 配列として指定すると、rocmetrics はパフォーマンス メトリクスの信頼区間を計算します。
rocObj = rocmetrics(Mdl,Tbl,ResponseVarName)Tbl 内の予測子データと Tbl 内に 1 つの列として格納された応答変数名 ResponseVarName を使用して、分類モデル オブジェクト Mdl から rocmetrics オブジェクトを作成します。
rocObj = rocmetrics(___,Name=Value)NumBootstraps=100 は、100 個のブートストラップ標本を抽出してパフォーマンス メトリクスの信頼区間を計算します。
入力引数
名前と値の引数
プロパティ
オブジェクト関数
addMetrics | 分類の追加のパフォーマンス メトリクスの計算 |
auc | ROC 曲線または適合率-再現率曲線の下の領域 |
average | マルチクラス問題における平均受信者動作特性 (ROC) 曲線のパフォーマンス メトリクスの計算 |
modelOperatingPoint | Operating point of rocmetrics object |
plot | 受信者動作特性 (ROC) 曲線やその他の性能曲線のプロット |
例
rocmetrics オブジェクトを作成してバイナリ分類問題のパフォーマンス メトリクス (FPR と TPR) を計算し、関数 plot を使用して ROC 曲線をプロットします。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子 (X) と、不良 ('b') または良好 ('g') という 351 個の二項反応 (Y) が含まれています。
load ionosphereデータを学習セットとテスト セットに分割します。観測値の約 80% をサポート ベクター マシン (SVM) モデルの学習に使用し、観測値の約 20% を学習済みモデルの新しいデータでの性能の検定に使用します。データの分割には cvpartition を使用します。
rng("default") % For reproducibility of the partition c = cvpartition(Y,Holdout=0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set XTrain = X(trainingIndices,:); YTrain = Y(trainingIndices); XTest = X(testIndices,:); YTest = Y(testIndices);
SVM 分類モデルに学習させます。
Mdl = fitcsvm(XTrain,YTrain);
テスト セットの分類スコアを計算します。
[~,Scores] = predict(Mdl,XTest); size(Scores)
ans = 1×2
70 2
出力 Scores は、70 行 2 列のサイズの行列です。Scores の列の順序は Mdl のクラスの順序に従います。Mdl.ClassNames に格納されているクラスの順序を表示します。
Mdl.ClassNames
ans = 2×1 cell
{'b'}
{'g'}
YTest の真のラベルと Scores の分類スコアを使用して rocmetrics オブジェクトを作成します。Mdl.ClassNames を使用して Scores の列の順序を指定します。
rocObj = rocmetrics(YTest,Scores,Mdl.ClassNames);
rocObj は、各クラスのパフォーマンス メトリクスが Metrics プロパティに格納された rocmetrics オブジェクトです。auc 関数を使用して AUC 値を計算します。
a = auc(rocObj)
a = 1×2
0.8587 0.8587
バイナリ分類問題の場合、AUC の値は互いに等しくなります。
Metrics の table には、両方のクラスについてのパフォーマンス メトリクスの値が、クラスの順序に従って垂直方向に連結して格納されます。table から 1 番目のクラスの行を特定し、最初の 8 行を表示します。
idx = strcmp(rocObj.Metrics.ClassName,Mdl.ClassNames(1)); head(rocObj.Metrics(idx,:))
ClassName Threshold FalsePositiveRate TruePositiveRate
_________ _________ _________________ ________________
{'b'} 15.546 0 0
{'b'} 15.546 0 0.04
{'b'} 15.106 0 0.08
{'b'} 11.424 0 0.16
{'b'} 10.08 0 0.2
{'b'} 9.9742 0 0.24
{'b'} 9.9413 0 0.28
{'b'} 9.0345 0 0.32
関数 plot を使用して、各クラスの ROC 曲線をプロットします。
plot(rocObj)

関数 plot は、各クラスの ROC 曲線をプロットし、モデル操作点に塗りつぶされた円のマーカーを表示します。凡例に各曲線のクラスの名前と AUC の値が表示されます。
バイナリ分類問題では、両方のクラスの ROC 曲線を調べる必要はないことに注意してください。2 つの ROC 曲線は対称であり、AUC の値は同じになります。一方のクラスの TPR はもう一方のクラスの真陰性率 (TNR) であり、TNR は 1-FPR です。したがって、一方のクラスの TPR と FPR のプロットはもう一方のクラスの 1-FPR と 1-TPR のプロットと同じになります。
名前と値の引数 ClassNames を指定して、1 番目のクラスの ROC 曲線のみをプロットします。
plot(rocObj,ClassNames=Mdl.ClassNames(1))

rocmetrics オブジェクトを作成してマルチクラス分類問題のパフォーマンス メトリクス (FPR と TPR) を計算し、関数 plot を使用して各クラスの ROC 曲線をプロットします。plot の名前と値の引数 AverageCurveType を指定して、マルチクラス問題の平均 ROC 曲線を作成します。
fisheriris データ セットを読み込みます。行列 meas には、150 種類の花についての測定値が格納されています。ベクトル species には、それぞれの花の種類がリストされています。species には、3 種類の花の名前が格納されています。
load fisheriris観測値を 3 つのラベルのいずれかに分類する分類木に学習させます。10 分割の交差検証をモデルに対して実行します。
rng("default") % For reproducibility Mdl = fitctree(meas,species,Crossval="on");
検証分割観測値の分類スコアを計算します。
[~,Scores] = kfoldPredict(Mdl); size(Scores)
ans = 1×2
150 3
出力 Scores は、150 行 3 列のサイズの行列です。Scores の列の順序は Mdl のクラスの順序に従います。Mdl.ClassNames に格納されているクラスの順序を表示します。
Mdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
species の真のラベルと Scores の分類スコアを使用して rocmetrics オブジェクトを作成します。Mdl.ClassNames を使用して Scores の列の順序を指定します。
rocObj = rocmetrics(species,Scores,Mdl.ClassNames);
rocObj は、各クラスのパフォーマンス メトリクスが Metrics プロパティに格納された rocmetrics オブジェクトです。auc 関数を使用して AUC 値を計算します。
a = auc(rocObj)
a = 1×3
1.0000 0.9636 0.9636
Metrics の table には、3 つのすべてのクラスについてのパフォーマンス メトリクスの値が、クラスの順序に従って垂直方向に連結して格納されます。table から 2 番目のクラスの行を特定して表示します。
idx = strcmp(rocObj.Metrics.ClassName,Mdl.ClassNames(2)); rocObj.Metrics(idx,:)
ans=13×4 table
ClassName Threshold FalsePositiveRate TruePositiveRate
______________ _________ _________________ ________________
{'versicolor'} 1 0 0
{'versicolor'} 1 0.01 0.7
{'versicolor'} 0.95455 0.02 0.8
{'versicolor'} 0.91304 0.03 0.9
{'versicolor'} -0.2 0.04 0.9
{'versicolor'} -0.33333 0.06 0.9
{'versicolor'} -0.6 0.08 0.9
{'versicolor'} -0.86957 0.12 0.92
{'versicolor'} -0.91111 0.16 0.96
{'versicolor'} -0.95122 0.31 0.96
{'versicolor'} -0.95238 0.38 0.98
{'versicolor'} -0.95349 0.44 0.98
{'versicolor'} -1 1 1
各クラスの ROC 曲線をプロットします。AverageCurveType="micro" を指定し、マイクロ平均法を使用して平均 ROC 曲線のパフォーマンス メトリクスを計算します。
plot(rocObj,AverageCurveType="micro")
ionosphere データをワークスペースに読み込みます。
load ionosphere
whoYour variables are: Description X Y
変数 X にデータがあり、変数 Y に応答があります。データの分類木モデルを作成します。
Mdl = fitctree(X,Y);
モデルと行列データからの rocmetrics オブジェクトの作成
X と Y を予測子データと応答データとして使用して、分類木モデルから rocmetrics オブジェクトを作成します。
rocMdl = rocmetrics(Mdl,X,Y);
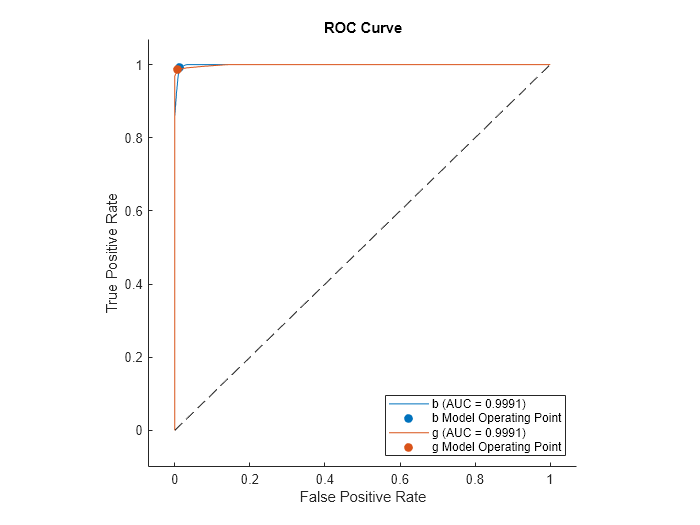
rocmetrics オブジェクトの ROC 曲線をプロットします。
plot(rocMdl)
モデルと table データからの rocmetrics オブジェクトの作成
X のデータの table を作成します。
save("datafile.txt","X","-ascii"); Tbl = readtable("datafile.txt");
Tbl を予測子データ、Y を応答データとして使用して、分類木モデルから rocmetrics オブジェクトを作成します。
Mdl2 = fitctree(Tbl,Y); rocMdl2 = rocmetrics(Mdl2,Tbl,Y);
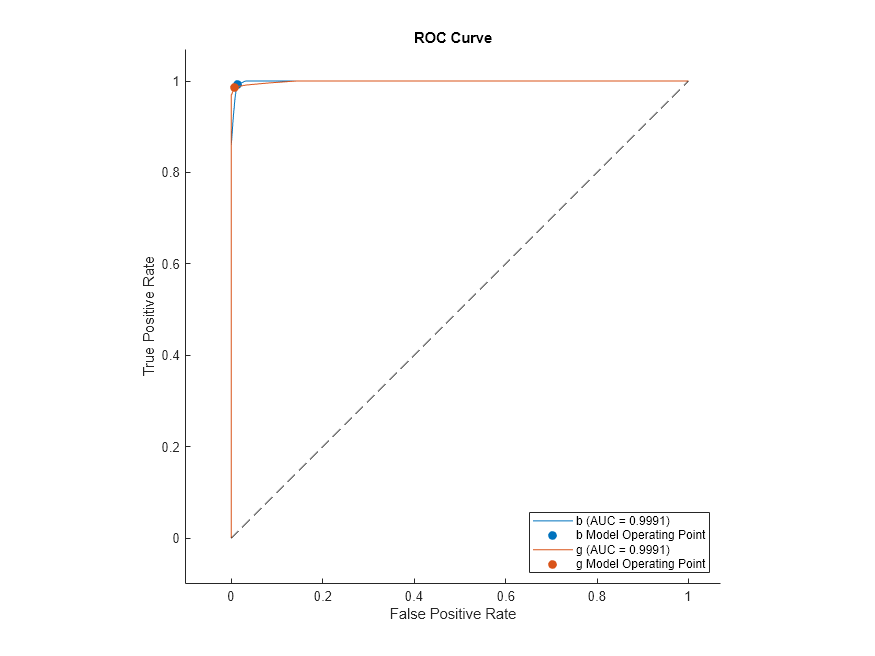
rocMdl2 の ROC 曲線をプロットします。前のプロットと同じになります。
plot(rocMdl2)
モデルと応答を含む table からの rocmetrics オブジェクトの作成
応答データ Y を Tbl 内に Resp という変数名で含めます。
Tbl.Resp = Y;
Resp を応答変数名として指定して、Tbl から rocmetrics オブジェクトを作成します。
Mdl3 = fitctree(Tbl,"Resp"); rocMdl3 = rocmetrics(Mdl3,Tbl,"Resp");
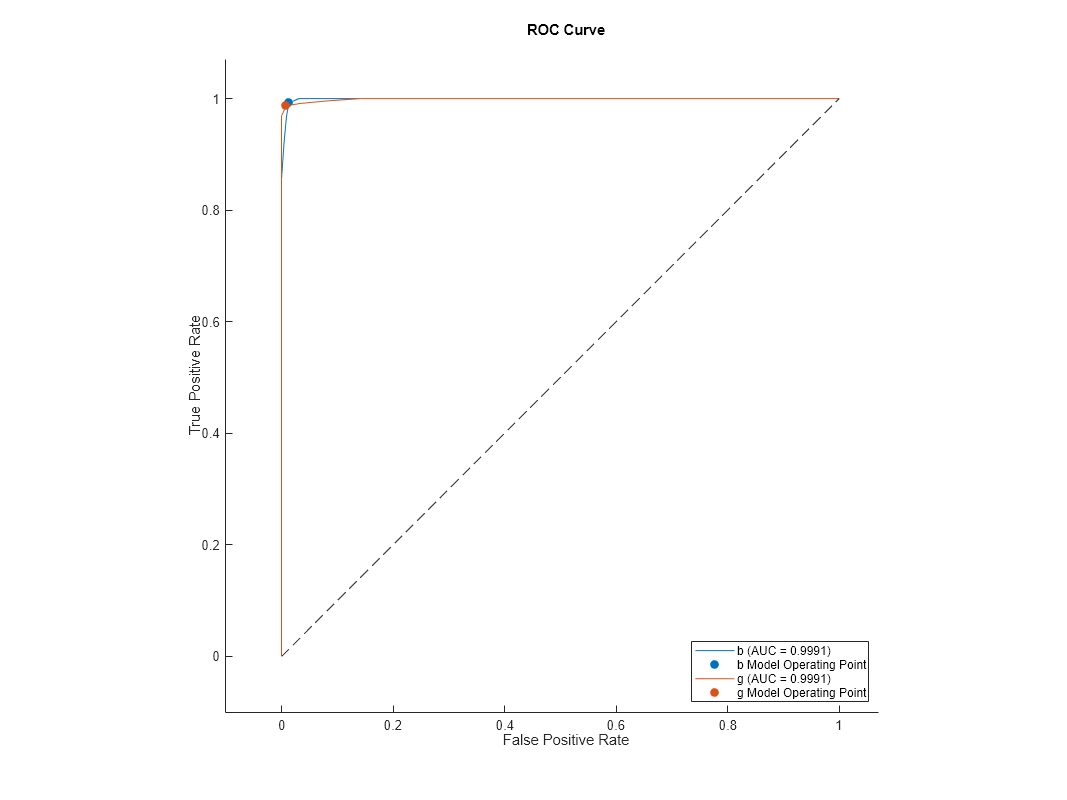
rocMdl3 の ROC 曲線をプロットします。前のプロットと同じになります。
plot(rocMdl3)
交差検証済みモデルからの rocmetrics オブジェクトの作成
交差検証分類木モデルを作成します。
rng default % For reproducibility CVMdl = fitctree(X,Y,KFold=5);
交差検証済みモデルから rocmetrics オブジェクトを作成します。
rocMdl4 = rocmetrics(CVMdl);
rocMdl4 の ROC 曲線をプロットします。
plot(rocMdl4)
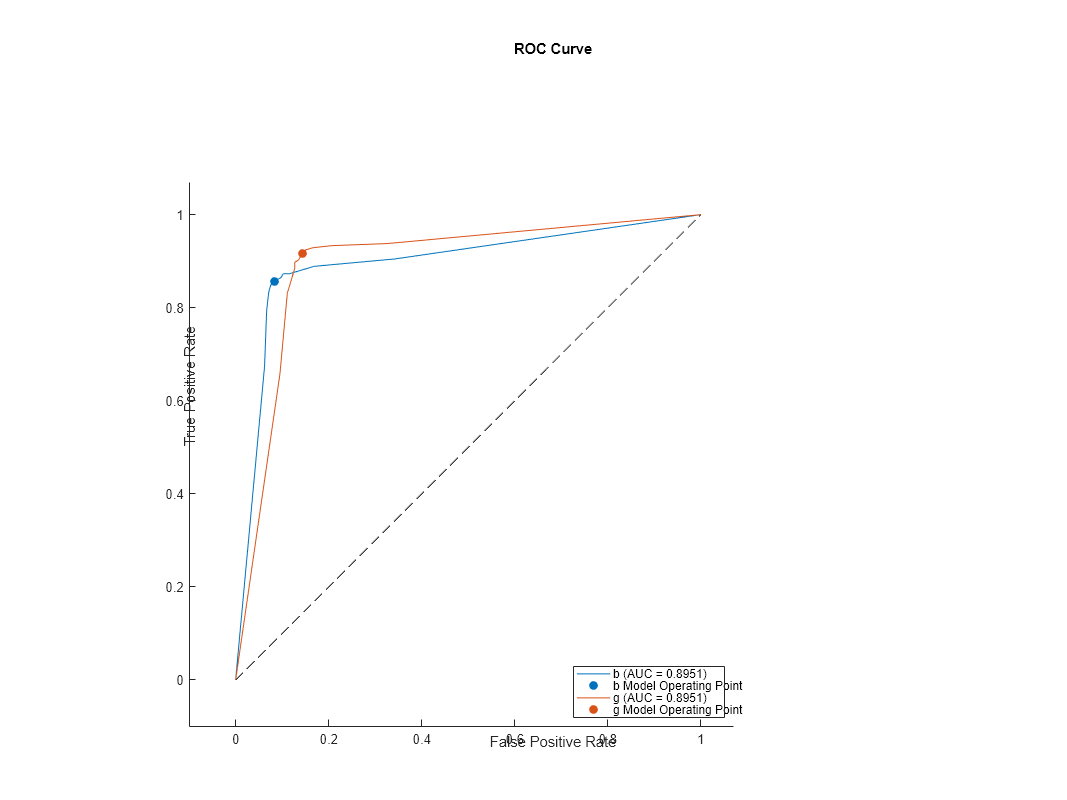
この ROC 曲線は前のプロットと見た目が異なります。交差検証済みモデルの ROC 曲線は、より現実に近いものになります。
"k" 最近傍 (KNN)、判別分析、および単純ベイズ分類器では、ラベルの予測にスコアではなく予測分類コストが使用されます。これらのモデルの ROC 曲線を既定以外の誤分類コストを使用して作成する場合は、関数 rocmetrics の名前と値の引数 ApplyCostToScores を true に設定します。
標本ファイル CreditRating_Historical.dat を table に読み取ります。予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。
creditrating = readtable("CreditRating_Historical.dat");変数 ID の各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID)) は creditrating に含まれる観測値の数に等しい)、変数 ID は予測子としては適切ではありません。変数 ID を table から削除します。
creditrating = removevars(creditrating,"ID");すべての A 格付けを 1 つの格付けに統合します。B と C の格付けに対して同様に実行し、応答変数に 3 つの異なる格付けが含まれるようにします。3 つの格付けのうち、A が最良で C が最悪と見なされます。
Rating = categorical(creditrating.Rating); Rating = mergecats(Rating,["AAA","AA","A"],"A"); Rating = mergecats(Rating,["BBB","BB","B"],"B"); Rating = mergecats(Rating,["CCC","CC","C"],"C"); creditrating.Rating = Rating;
顧客の信用格付けの誤分類に特定のコストが関連付けられていると仮定します。誤分類コストを含む行列変数を作成します。クラス名と行列変数におけるそれらの順序を指定する別の変数を作成します。
classificationCosts = [0 100 200; 500 0 100; 1000 500 0]; classNames = categorical(["A","B","C"]);
このコストは、信用が高い顧客を信用が低い顧客として分類するより、信用が低い顧客を信用が高い顧客として分類するほうが、コストが高いことを示しています。たとえば、C の格付け顧客を A の格付け顧客として誤分類するコストは $1000 です。
データを学習セットとテスト セットに分割します。観測値の 75% を判別分析分類器の学習に使用し、観測値の 25% を学習済みモデルの新しいデータでの性能のテストに使用します。
rng("default") % For reproducibility c = cvpartition(creditrating.Rating,"Holdout",0.25); trainRatings = creditrating(training(c),:); testRatings = creditrating(test(c),:);
判別分析分類器を学習させます。誤分類コストを指定します。
mdl = fitcdiscr(trainRatings,"Rating",Cost=classificationCosts, ... ClassNames=classNames);
テスト セットの観測値について、クラス ラベル、スコア、予測分類コストを予測します。
[labels,scores,expectedCosts] = predict(mdl,testRatings);
各観測値の予測クラス ラベルは、すべてのクラスの中でスコア (事後確率) が最大のクラスではなく、予測分類コストが最小のクラスに対応します。
たとえば、テスト セットの最初の観測値についての予測を表示します。
firstLabel = labels(1)
firstLabel = categorical
B
firstScores = array2table(scores(1,:),VariableNames=["A","B","C"])
firstScores=1×3 table
A B C
_______ _______ __________
0.70807 0.29193 4.7141e-13
firstExpectedCosts = array2table(expectedCosts(1,:), ... VariableNames=["A","B","C"])
firstExpectedCosts=1×3 table
A B C
______ ______ ______
145.96 70.807 170.81
事後確率はクラス A が最大であるにもかかわらず、予測ラベルは予測分類コストが最も低いクラス B に対応しています。
testRatings の真のラベルと scores の分類スコアを使用して rocmetrics オブジェクトを作成します。scores の列の順序を指定します。既定以外の誤分類コストと判別分析モデルから返されるスコアを使用するために、名前と値の引数 Cost と ApplyCostToScores を指定します。
roc = rocmetrics(testRatings.Rating,scores,classNames, ...
Cost=classificationCosts,ApplyCostToScores=true);rocmetrics に格納されているスコアは負の予測分類コストであることに注意してください。
isequal(roc.Scores,-expectedCosts)
ans = logical
1
関数 plot を使用して、各クラスの ROC 曲線をプロットします。
plot(roc,ClassNames=classNames)

各クラスについて、プロット関数で曲線がプロットされます。塗りつぶされた円のマーカーはモデル操作点を示します。
creditrating データ セット全体を使用して、交差検証判別分析分類器に学習させます。
cvmdl = fitcdiscr(creditrating,"Rating",Cost=classificationCosts, ... ClassNames=classNames,CrossVal="on")
cvmdl =
ClassificationPartitionedModel
CrossValidatedModel: 'Discriminant'
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
NumObservations: 3932
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: [A B C]
ScoreTransform: 'none'
Properties, Methods
関数 fitcdiscr で、タイプ Discriminant (CrossValidatedModel プロパティの値) の ClassificationPartitionedModel オブジェクトが作成されます。交差検証済みモデルを作成するために、関数では次の手順が実行されます。
データを 10 個のセットに無作為に分割する。
各セットについて、そのセットを検証データとして予約し、他の 9 個のセットを使用してモデルに学習させる。
10 個のコンパクトな学習済みモデルを交差検証済みモデル オブジェクトの
Trainedプロパティに 10 行 1 列の cell ベクトルとして格納する。
cvmdl.Trained
ans=10×1 cell array
{1×1 classreg.learning.classif.CompactClassificationDiscriminant}
{1×1 classreg.learning.classif.CompactClassificationDiscriminant}
{1×1 classreg.learning.classif.CompactClassificationDiscriminant}
{1×1 classreg.learning.classif.CompactClassificationDiscriminant}
{1×1 classreg.learning.classif.CompactClassificationDiscriminant}
{1×1 classreg.learning.classif.CompactClassificationDiscriminant}
{1×1 classreg.learning.classif.CompactClassificationDiscriminant}
{1×1 classreg.learning.classif.CompactClassificationDiscriminant}
{1×1 classreg.learning.classif.CompactClassificationDiscriminant}
{1×1 classreg.learning.classif.CompactClassificationDiscriminant}
各観測値について、クラス ラベル、スコア、予測分類コストを予測します。
[cvlabels,cvscores,cvexpectedCosts] = kfoldPredict(cvmdl);
各クラスの ROC 曲線をプロットします。
cvroc = rocmetrics(creditrating.Rating,cvscores,classNames, ...
Cost=classificationCosts,ApplyCostToScores=true);
plot(cvroc,ClassNames=classNames)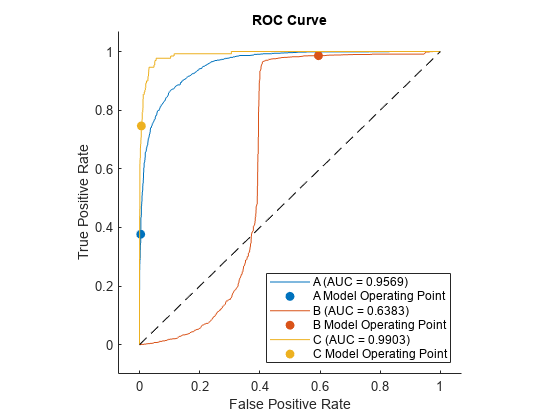
交差検証の結果は前のテスト セットと似た結果になります。
外れ値を含む生成された標本データについて、関数iforestを使用して孤立森モデルに学習させて異常スコアを計算します。iforest はスコアをベクトルとして返します。スコアを使用して rocmetrics オブジェクトを作成します。異常スコアを使用して適合率-再現率曲線をプロットし、孤立森モデルのモデル操作点を特定します。
ガウス型コピュラを使用して、二変量分布からランダムなデータ点を生成します。
rng("default") rho = [1,0.05;0.05,1]; n = 1000; u = copularnd("Gaussian",rho,n);
無作為に選択された 5% の観測値にノイズを追加して、それらの観測値を外れ値にします。
noise = randperm(n,0.05*n); true_tf = false(n,1); true_tf(noise) = true; u(true_tf,1) = u(true_tf,1)*5;
関数 iforest を使用して孤立森モデルに学習させます。学習観測値に含まれている異常の比率を 0.05 と指定します。
[f,tf,scores] = iforest(u,ContaminationFraction=0.05);
f はIsolationForestオブジェクトです。iforest は、学習データの異常インジケーター (tf) および異常スコア (scores) も返します。iforest は、指定した比率の学習観測値が異常として検出されるようにしきい値 (f.ScoreThreshold) を決定します。
曲線の下の領域 (AUC) の値を計算する適合率-再現率曲線をプロットして、IsolationForest オブジェクトの性能をチェックします。真の異常インジケーター (true_tf) と異常スコア (scores) を使用して rocmetrics オブジェクトを作成します。1 に近いスコア値は異常を示し、true_tf の値が true になります。したがって、scores のクラス名を true として指定します。名前と値の引数 AdditionalMetrics を指定して、適合率の値 (つまり陽性の予測値) を計算します。
rocObj = rocmetrics(true_tf,scores,true,AdditionalMetrics="PositivePredictiveValue");rocmetrics の関数 plot を使用して曲線をプロットします。"y" 軸のメトリクスを適合率 (つまり陽性の予測値)、"x" 軸のメトリクスを再現率 (つまり真陽性率) として指定します。f.ScoreThreshold に対応するモデル操作点に塗りつぶされた円を表示します。
r = plot(rocObj,YAxisMetric="PositivePredictiveValue",XAxisMetric="TruePositiveRate",... ShowModelOperatingPoint=true);

ブートストラップ標本を使用して FPR と TPR の固定のしきい値に対する信頼区間を計算し、関数 plot を使用して ROC 曲線に TPR の信頼区間をプロットします。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子 (X) と、不良 ('b') または良好 ('g') という 351 個の二項反応 (Y) が含まれています。
load ionosphereデータを学習セットとテスト セットに分割します。観測値の約 80% をサポート ベクター マシン (SVM) モデルの学習に使用し、観測値の約 20% を学習済みモデルの新しいデータでの性能の検定に使用します。データの分割には cvpartition を使用します。
rng("default") % For reproducibility of the partition c = cvpartition(Y,Holdout=0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set XTrain = X(trainingIndices,:); YTrain = Y(trainingIndices); XTest = X(testIndices,:); YTest = Y(testIndices);
SVM 分類モデルに学習させます。
Mdl = fitcsvm(XTrain,YTrain);
テスト セットの分類スコアを計算します。
[~,Scores] = predict(Mdl,XTest);
YTest の真のラベルと Scores の分類スコアを使用して rocmetrics オブジェクトを作成します。Mdl.ClassNames を使用して Scores の列の順序を指定します。NumBootstraps を 100 と指定し、100 個のブートストラップ標本を使用して信頼区間を計算します。
rocObj = rocmetrics(YTest,Scores,Mdl.ClassNames, ...
NumBootstraps=100);Metrics プロパティの table から 2 番目のクラスの行を特定し、最初の 8 行を表示します。
idx = strcmp(rocObj.Metrics.ClassName,Mdl.ClassNames(2)); head(rocObj.Metrics(idx,:))
ClassName Threshold FalsePositiveRate TruePositiveRate
_________ _________ __________________________ ________________________________
{'g'} 7.196 0 0 0 0 0 0
{'g'} 7.196 0 0 0 0.022222 0 0.093023
{'g'} 6.2583 0 0 0 0.044444 0 0.11969
{'g'} 5.5719 0 0 0 0.066667 0.020988 0.16024
{'g'} 5.5643 0 0 0 0.088889 0.022635 0.18805
{'g'} 5.4618 0.04 0 0.22222 0.088889 0.022635 0.18805
{'g'} 5.3667 0.08 0 0.28 0.088889 0.022635 0.18805
{'g'} 5.1525 0.08 0 0.28 0.11111 0.045035 0.19532
table の各行に、FPR と TPR の固定のしきい値に対するメトリクスの値とその信頼区間が格納されます。変数 Threshold は列ベクトルで、変数 FalsePositiveRate と TruePositiveRate は 3 列の行列です。行列の 1 列目がメトリクスの値に対応し、2 列目と 3 列目が下限と上限にそれぞれ対応します。
TPR の ROC 曲線と信頼区間をプロットします。信頼区間を表示するために ShowConfidenceIntervals=true を指定し、プロットする 1 つのクラスを名前と値の引数 ClassNames を使用して指定します。
plot(rocObj,ShowConfidenceIntervals=true,ClassNames=Mdl.ClassNames(2))
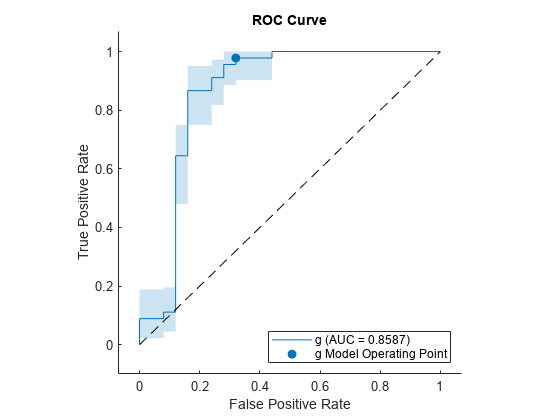
ROC 曲線の周囲に影付きの領域で信頼区間が示されます。信頼区間は、学習済みモデルのテスト セットでの分散による曲線の不確かさを表しています。
交差検証データを使用して FPR と TPR の固定のしきい値に対する信頼区間を計算し、関数 plot を使用して ROC 曲線に TPR の信頼区間をプロットします。
fisheriris データ セットを読み込みます。行列 meas には、150 種類の花についての測定値が格納されています。ベクトル species には、それぞれの花の種類がリストされています。species には、3 種類の花の名前が格納されています。
load fisheriris観測値を 3 つのラベルのいずれかに分類する単純ベイズ モデルに学習させます。10 分割の交差検証をモデルに対して実行します。
rng("default") % For reproducibility Mdl = fitcnb(meas,species,Crossval="on");
検証分割観測値の分類スコアを計算します。
[~,Scores] = kfoldPredict(Mdl);
cell 配列の各要素が 1 つの検証分割に対応するように、交差検証済みスコアとそれに対応する真のラベルを cell 配列に格納します。
cv = Mdl.Partition; numTestSets = cv.NumTestSets; cvLabels = cell(numTestSets,1); cvScores = cell(numTestSets,1); for i = 1:numTestSets testIdx = test(cv,i); cvLabels{i} = species(testIdx); cvScores{i} = Scores(testIdx,:); end
cell 配列を使用して rocmetrics オブジェクトを作成します。cell 配列を使用して真のラベルとスコアを指定すると、rocmetrics で信頼区間が計算されます。
rocObj = rocmetrics(cvLabels,cvScores,Mdl.ClassNames);
TPR の ROC 曲線と信頼区間をプロットします。信頼区間を表示するために ShowConfidenceIntervals=true を指定します。
plot(rocObj,ShowConfidenceIntervals=true)
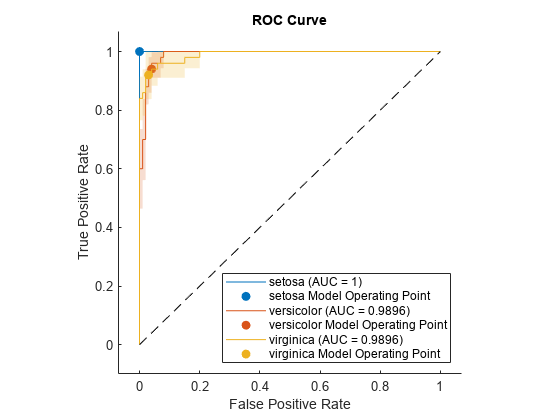
各曲線の周囲に影付きの領域で信頼区間が示されます。setosa の信頼区間は非ゼロの偽陽性率の幅が 0 であるため、プロットに setosa に対する影付きの領域はありません。信頼区間は、学習セットとテスト セットでの分散によるモデルの不確かさを反映しています。
決定木モデル、一般化加法モデル、および単純ベイズ モデルの 3 種類の分類モデルに学習させます。ROC 曲線と AUC の値を使用して、テスト データ セットで 3 つのモデルの性能を比較します。
census1994.mat に保存されている 1994 年の国勢調査データを読み込みます。このデータ セットは、個人の年収が $50,000 を超えるかどうかを予測するための、米国勢調査局の人口統計データから構成されます。
load census1994census1994 には学習データ セット adultdata およびテスト データ セット adulttest が含まれています。応答変数 salary の一意の値を表示します。
classNames = unique(adultdata.salary)
classNames = 2×1 categorical
<=50K
>50K
学習データ adultdata を渡し、応答変数名 "salary" を指定して、3 つのモデルに学習させます。名前と値の引数 ClassNames を使用してクラスの順序を指定します。
MdlTree = fitctree(adultdata,"salary",ClassNames=classNames); MdlGAM = fitcgam(adultdata,"salary",ClassNames=classNames); MdlNB = fitcnb(adultdata,"salary",ClassNames=classNames);
学習済みモデルを使用して、テスト データ セット adulttest の分類スコアを計算します。
[~,ScoresTree] = predict(MdlTree,adulttest); [~,ScoresGAM] = predict(MdlGAM,adulttest); [~,ScoresNB] = predict(MdlNB,adulttest);
各モデルの rocmetrics オブジェクトを作成します。
rocTree = rocmetrics(adulttest.salary,ScoresTree,classNames); rocGAM = rocmetrics(adulttest.salary,ScoresGAM,classNames); rocNB = rocmetrics(adulttest.salary,ScoresNB,classNames);
各モデルの ROC 曲線をプロットします。関数 plot は、既定ではクラス名と AUC の値を凡例に表示します。凡例にクラス名の代わりにモデル名を含めるには、関数 plot から返される ROCCurve オブジェクトの DisplayName プロパティを変更します。
figure
c = cell(3,1);
g = cell(3,1);
[c{1},g{1}] = plot(rocTree,ClassNames=classNames(1));
hold on
[c{2},g{2}] = plot(rocGAM,ClassNames=classNames(1));
[c{3},g{3}] = plot(rocNB,ClassNames=classNames(1));
modelNames = ["Decision Tree Model", ...
"Generalized Additive Model","Naive Bayes Model"];
for i = 1 : 3
c{i}.DisplayName = replace(c{i}.DisplayName, ...
string(classNames(1)),modelNames(i));
g{i}(1).DisplayName = join([modelNames(i),"Operating Point"]);
end
hold off
AUC の値は、一般化加法モデル (MdlGAM) が最も高く、決定木モデル (MdlTree) が最も低くなっています。この結果は、MdlTree と MdlNB よりも MdlGAM の方がテスト データ セットに対する平均的な性能が優れていることを示しています。
バイナリ分類モデルのモデル操作点と最適な操作点を特定します。最適な操作点に対応する新しいしきい値を使用して、テスト データ セットの観測値を分類します。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子 (X) と、不良 (b) または良好 (g) という 351 個の二項反応 (Y) が含まれています。
load ionosphereデータを学習セットとテスト セットに分割します。観測値の約 75% をサポート ベクター マシン (SVM) モデルの学習に使用し、観測値の約 25% を学習済みモデルの新しいデータでの性能の検定に使用します。データの分割には cvpartition を使用します。
rng("default") % For reproducibility of the partition c = cvpartition(Y,Holdout=0.25); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set XTrain = X(trainingIndices,:); YTrain = Y(trainingIndices); XTest = X(testIndices,:); YTest = Y(testIndices);
SVM 分類モデルに学習させます。
Mdl = fitcsvm(XTrain,YTrain);
Mdl.ClassNames に格納されているクラスの順序を表示します。
Mdl.ClassNames
ans = 2×1 cell
{'b'}
{'g'}
テスト セットの分類スコアを計算します。
[Y1,Scores] = predict(Mdl,XTest);
YTest の真のラベルと Scores の分類スコアを使用して rocmetrics オブジェクトを作成します。Mdl.ClassNames を使用して Scores の列の順序を指定します。
rocObj = rocmetrics(YTest,Scores,Mdl.ClassNames);
modelOperatingPoint 関数を使用してモデル操作点を特定します。
modelpt = modelOperatingPoint(rocObj)
modelpt=2×4 table
ClassName Threshold FalsePositiveRate TruePositiveRate
_________ _________ _________________ ________________
{'b'} 1.262 0.017857 0.58065
{'g'} 0.21843 0.41935 0.98214
この関数はどのように機能するでしょうか。関数 predict は、スコアが高い方のクラスに観測値を分類します。これは、調整スコアが非負になるクラスに対応します。つまり、関数 predict で使用される標準のしきい値は 0 です。rocObj の Metrics プロパティのクラス b に対する行から、最も小さい非負のしきい値をもつ点を見つけます。曲線上の点は、しきい値 0 の性能と同じ性能を示します。
idx_b = strcmp(rocObj.Metrics.ClassName,"b"); X = rocObj.Metrics(idx_b,:).FalsePositiveRate; Y = rocObj.Metrics(idx_b,:).TruePositiveRate; T = rocObj.Metrics(idx_b,:).Threshold; idx_model = find(T>=0,1,"last"); modelptb = [T(idx_model) X(idx_model) Y(idx_model)]
modelptb = 1×3
1.2620 0.0179 0.5806
バイナリ分類の場合、平均誤分類コストが最小になる最適な操作点は、ROC 曲線が傾き の直線と交差する点になります。ここで、 は次のように定義されます。
.
は陽性クラスの観測値の総数、 は陰性クラスの観測値の総数です。cost の値はコスト行列 の成分です。
cost(N|P) は陽性クラスを陰性クラスとして誤分類するコスト、cost(P|N) は陰性クラスを陽性クラスとして誤分類するコストです。Mdl.ClassNames のクラスの順序に従い、陽性クラス P はクラス b に対応します。
傾き の線と交差する ROC 曲線上の点から、完璧な ROC 曲線が通る完璧な分類器の点 (FPR = 0、TPR = 1) に最も近い点を選択します。
陽性クラス b の最適な操作点を特定します。
p = sum(strcmp(YTest,"b")); n = sum(~strcmp(YTest,"b")); cost = Mdl.Cost; m = (cost(2,1)-cost(2,2))/(cost(1,2)-cost(1,1))*n/p; [~,idx_opt] = min(X - Y/m); optpt = [T(idx_opt) X(idx_opt) Y(idx_opt)]
optpt = 1×3
-1.1976 0.1071 0.7742
plot 関数を使用して、クラス b の ROC 曲線をプロットします。これにより、既定でモデル操作点も表示されます。
figure
r = plot(rocObj,ClassNames="b");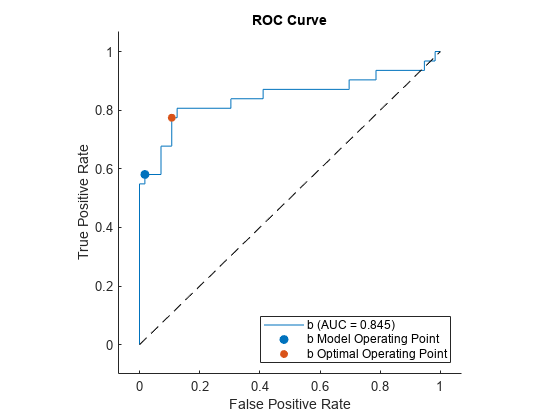
モデル操作点と最適な操作点を表示します。
modelpt(3,:) = table({"b optimal"},optpt(1),optpt(2),optpt(3))modelpt=3×4 table
ClassName Threshold FalsePositiveRate TruePositiveRate
_______________ _________ _________________ ________________
{'b' } 1.262 0.017857 0.58065
{'g' } 0.21843 0.41935 0.98214
{["b optimal"]} -1.1976 0.10714 0.77419
最適な操作点を使用して XTest を分類します。調整スコアが最適なしきい値以上である観測値を陽性クラス b に割り当てます。
s = Scores(:,1) - Scores(:,2);
idx_b_opt = (s >= optpt(1));
Y2 = cell(size(YTest));
Y2(idx_b_opt) = {'b'};
Y2(~idx_b_opt) = {'g'};Y1 のラベル (関数 predict からのラベル) と Y2 のラベル (最適なしきい値 optpt(1) からのラベル) が異なる観測値の調整スコアを表示します。
s(~strcmp(Y1,Y2))
ans = 11×1
-1.1705
-0.8448
-0.8239
-0.4546
-1.0720
-0.4614
-0.2184
-1.1976
-1.0114
-1.1551
-0.4523
⋮
調整スコアが 0 未満で最適なしきい値以上である観測値が 11 個あります。
マルチクラス分類問題用のモデルに学習させた後、目的のクラスのみに対応する rocmetrics オブジェクトを作成します。指定したしきい値についてのパフォーマンス メトリクスを rocmetrics で計算するように FixedMetricValues を指定します。
標本ファイル CreditRating_Historical.dat を table に読み取ります。予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。データ セットの最初の数行をプレビューします。
creditrating = readtable("CreditRating_Historical.dat");
head(creditrating) ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ ______ ______ _______ ________ _____ ________ _______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB' }
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
48631 0.194 0.263 0.062 1.017 0.228 4 {'BBB'}
43768 0.121 0.413 0.057 3.647 0.466 12 {'AAA'}
39255 -0.117 -0.799 0.01 0.179 0.082 4 {'CCC'}
62236 0.087 0.158 0.049 0.816 0.324 2 {'BBB'}
39354 0.005 0.181 0.034 2.597 0.388 7 {'AA' }
変数 ID の各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID)) は creditrating に含まれる観測値の数に等しい)、変数 ID は予測子としては適切ではありません。変数 ID を table から削除し、変数 Industry を categorical 変数に変換します。
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);データを学習セットとテスト セットに分割します。観測値の約 80% をニューラル ネットワーク モデルの学習に使用し、観測値の約 20% を学習済みモデルの新しいデータでの性能のテストに使用します。データの分割には cvpartition を使用します。
rng("default") % For reproducibility of the partition c = cvpartition(creditrating.Rating,"Holdout",0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set creditTrain = creditrating(trainingIndices,:); creditTest = creditrating(testIndices,:);
学習データ creditTrain を関数 fitcnet に渡して、ニューラル ネットワーク分類器に学習させます。
Mdl = fitcnet(creditTrain,"Rating");テスト セットの観測値について、分類スコアを計算し、格付けを予測します。
[labels,Scores] = predict(Mdl,creditTest);
ニューラル ネットワーク分類器の分類スコアは事後確率に対応します。
モデルの B、BB、および BBB の格付けのみを評価し、残りの格付けは無視するとします。
ClassNames プロパティに格納されているモデルの格付けの順序を表示し、評価するクラスを特定します。
Mdl.ClassNames
ans = 7×1 cell
{'A' }
{'AA' }
{'AAA'}
{'B' }
{'BB' }
{'BBB'}
{'CCC'}
idx_Class = [4 5 6]; classesToEvaluate = Mdl.ClassNames(idx_Class);
3 つのクラス (B、BB、BBB) の観測値のインデックスを特定します。
idx = ismember(creditTest.Rating,classesToEvaluate);
3 つのクラスの真のラベルとスコアを使用して rocmetrics オブジェクトを作成します。指定したしきい値についてのパフォーマンス メトリクスを rocmetrics で計算するように FixedMetricValues=1:-0.25:-1 を指定します。
thresholds = 1:-0.25:-1;
rocObj = rocmetrics(creditTest.Rating(idx),Scores(idx,idx_Class), ...
classesToEvaluate,FixedMetricValues=thresholds);Metrics プロパティに格納されている計算されたメトリクスを表示します。
rocObj.Metrics
ans=27×4 table
ClassName Threshold FalsePositiveRate TruePositiveRate
_________ __________ _________________ ________________
{'B' } 0.85716 0 0
{'B' } 0.77865 0 0.10938
{'B' } 0.52098 0.007732 0.3125
{'B' } 0.27642 0.020619 0.42188
{'B' } 0.00018834 0.046392 0.59375
{'B' } -0.24869 0.10825 0.67188
{'B' } -0.49883 0.16495 0.75
{'B' } -0.74953 0.51804 0.85938
{'B' } -0.97556 1 1
{'BB'} 0.95742 0 0
{'BB'} 0.75382 0.048689 0.19459
{'BB'} 0.50353 0.10861 0.47027
{'BB'} 0.26199 0.15356 0.60541
{'BB'} 0.0021065 0.22097 0.75676
{'BB'} -0.22974 0.33708 0.85946
{'BB'} -0.49791 0.47566 0.94595
⋮
Metrics プロパティには、3 つの格付け B、BB、および BBB の指定したしきい値についてのパフォーマンス メトリクスのみが格納されます。rocmetrics で信頼区間を計算しない場合、UseNearestNeighbor の既定値は true です。したがって、指定した各しきい値について、rocmetrics は指定された値に最も近い調整スコアの値を選択し、その最も近い値をしきい値として使用します。各クラスの指定したしきい値と実際に使用されるしきい値を表示します。
idx_B = strcmp(rocObj.Metrics.ClassName,"B"); idx_BB = strcmp(rocObj.Metrics.ClassName,"BB"); idx_BBB = strcmp(rocObj.Metrics.ClassName,"BBB"); table(thresholds',rocObj.Metrics.Threshold(idx_B), ... rocObj.Metrics.Threshold(idx_BB), ... rocObj.Metrics.Threshold(idx_BBB), ... VariableNames=["Fixed Threshold";string(classesToEvaluate)])
ans=9×4 table
Fixed Threshold B BB BBB
_______________ __________ _________ _________
1 0.85716 0.95742 0.94214
0.75 0.77865 0.75382 0.75343
0.5 0.52098 0.50353 0.50068
0.25 0.27642 0.26199 0.25555
0 0.00018834 0.0021065 0.0084191
-0.25 -0.24869 -0.22974 -0.24954
-0.5 -0.49883 -0.49791 -0.49609
-0.75 -0.74953 -0.74572 -0.74947
-1 -0.97556 -0.94214 -0.96075