ClassificationECOC
サポート ベクター マシン (SVM) などの分類器用のマルチクラス モデル
説明
ClassificationECOC は、分類器が複数のバイナリ学習器 (サポート ベクター マシン (SVM) など) から構成されている場合の、マルチクラス学習用の誤り訂正出力符号 (ECOC) 分類器です。学習済みの ClassificationECOC 分類器には、学習データ、パラメーター値、事前確率および符号化行列が格納されます。これらの分類器を使用して、新しいデータのラベルや事後確率を予測する (predict を参照) などのタスクを実行できます。
作成
ClassificationECOC オブジェクトの作成には fitcecoc を使用します。
交差検証オプションを指定せずに線形またはカーネル バイナリ学習器を指定した場合、fitcecoc は代わりに CompactClassificationECOC オブジェクトを返します。
プロパティ
オブジェクト関数
compact | 機械学習モデルのサイズの縮小 |
compareHoldout | 新しいデータを使用して 2 つの分類モデルの精度を比較 |
crossval | 機械学習モデルの交差検証 |
discardSupportVectors | ECOC モデルの線形 SVM バイナリ学習器のサポート ベクターを破棄 |
edge | マルチクラス誤り訂正出力符号 (ECOC) モデルの分類エッジ |
gather | GPU からの Statistics and Machine Learning Toolbox オブジェクトのプロパティの収集 |
incrementalLearner | マルチクラス誤り訂正出力符号 (ECOC) モデルをインクリメンタル学習器に変換 |
loss | マルチクラス誤り訂正出力符号 (ECOC) モデルの分類損失 |
margin | マルチクラス誤り訂正出力符号 (ECOC) モデルの分類マージン |
partialDependence | 部分依存の計算 |
plotPartialDependence | 部分依存プロット (PDP) および個別条件付き期待値 (ICE) プロットの作成 |
predict | マルチクラス誤り訂正出力符号 (ECOC) モデルを使用して観測値を分類 |
resubEdge | マルチクラス誤り訂正出力符号 (ECOC) モデルの再代入分類エッジ |
lime | Local Interpretable Model-agnostic Explanations (LIME) |
resubLoss | マルチクラス誤り訂正出力符号 (ECOC) モデルの再代入分類損失 |
resubMargin | マルチクラス誤り訂正出力符号 (ECOC) モデルの再代入分類マージン |
resubPredict | マルチクラス誤り訂正出力符号 (ECOC) モデル内の観測値を分類 |
shapley | シャープレイ値 |
testckfold | 交差検証の反復により 2 つの分類モデルの精度を比較 |
例
サポート ベクター マシン (SVM) バイナリ学習器を使用して、マルチクラス誤り訂正出力符号 (ECOC) モデルに学習をさせます。
フィッシャーのアヤメのデータ セットを読み込みます。予測子データ X と応答データ Y を指定します。
load fisheriris
X = meas;
Y = species;既定のオプションを使用して、マルチクラス ECOC モデルに学習をさせます。
Mdl = fitcecoc(X,Y)
Mdl =
ClassificationECOC
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingName: 'onevsone'
Properties, Methods
Mdl は ClassificationECOC モデルです。既定では、fitcecoc は SVM バイナリ学習器および 1 対 1 符号化設計を使用します。ドット表記を使用して Mdl プロパティにアクセスできます。
クラス名および符号化設計行列を表示します。
Mdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
CodingMat = Mdl.CodingMatrix
CodingMat = 3×3
1 1 0
-1 0 1
0 -1 -1
3 つのクラスに対して 1 対 1 符号化設計を使用すると、3 つのバイナリ学習器が生成されます。CodingMat の列は学習器に、行はクラスに対応します。クラスの順序は Mdl.ClassNames 内の順序と同じです。たとえば、CodingMat(:,1) は [1; –1; 0] であり、'setosa' または 'versicolor' として分類されるすべての観測値を使用して最初の SVM バイナリ学習器が学習を行うことを示します。'setosa' は 1 に対応するので陽性クラスであり、'versicolor' は –1 に対応するので陰性クラスです。
各バイナリ学習器にセルのインデックス付けおよびドット表記を使用してアクセスすることができます。
Mdl.BinaryLearners{1} % The first binary learnerans =
CompactClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [-1 1]
ScoreTransform: 'none'
Beta: [4×1 double]
Bias: 1.4505
KernelParameters: [1×1 struct]
Properties, Methods
再代入分類誤差を計算します。
error = resubLoss(Mdl)
error = 0.0067
学習データに対する分類誤差は小さくなっていますが、分類器が過適合モデルになる可能性があります。代わりに、crossval を使用して分類器を交差検証し、交差検証分類誤差を計算することができます。
SVM バイナリ学習器を使用して ECOC 分類器に学習をさせます。次に、ドット表記を使用して、バイナリ学習器のプロパティ (推定パラメーターなど) にアクセスします。
フィッシャーのアヤメのデータ セットを読み込みます。予測子として花弁の寸法を、応答として種の名前を指定します。
load fisheriris
X = meas(:,3:4);
Y = species;SVM バイナリ学習器および既定の符号化設計 (1 対 1) を使用して ECOC 分類器に学習をさせます。予測子を標準化し、サポート ベクターを保存します。
t = templateSVM('Standardize',true,'SaveSupportVectors',true); predictorNames = {'petalLength','petalWidth'}; responseName = 'irisSpecies'; classNames = {'setosa','versicolor','virginica'}; % Specify class order Mdl = fitcecoc(X,Y,'Learners',t,'ResponseName',responseName,... 'PredictorNames',predictorNames,'ClassNames',classNames)
Mdl =
ClassificationECOC
PredictorNames: {'petalLength' 'petalWidth'}
ResponseName: 'irisSpecies'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingName: 'onevsone'
Properties, Methods
tは SVM 分類のオプションを含むテンプレート オブジェクトです。関数 fitcecoc は、空 ([]) のプロパティについて既定値を使用します。Mdl は ClassificationECOC 分類器です。ドット表記を使用して Mdl のプロパティにアクセスできます。
クラス名および符号化設計行列を表示します。
Mdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
Mdl.CodingMatrix
ans = 3×3
1 1 0
-1 0 1
0 -1 -1
列は SVM バイナリ学習器に対応し、行は個々のクラスに対応します。行の順序は、Mdl の ClassNames プロパティにおける順序と同じです。各列について:
1は、対応するクラスの観測値を陽性のグループのメンバーとして使用してfitcecocが SVM に学習をさせることを示します。–1は、対応するクラスの観測値を陰性のグループのメンバーとして使用してfitcecocが SVM に学習をさせることを示します。0は、対応するクラスの観測値を SVM が使用しないことを示します。
たとえば、1 番目の SVM で fitcecoc はすべての観測値を 'setosa' または 'versicolor' に割り当てていますが、'virginica' には割り当てていません。
セルの添字とドット表記を使用して、SVM のプロパティにアクセスします。各 SVM の標準化されたサポート ベクターを保存します。サポート ベクターを非標準化します。
L = size(Mdl.CodingMatrix,2); % Number of SVMs sv = cell(L,1); % Preallocate for support vector indices for j = 1:L SVM = Mdl.BinaryLearners{j}; sv{j} = SVM.SupportVectors; sv{j} = sv{j}.*SVM.Sigma + SVM.Mu; end
sv は、SVM の非標準化されたサポート ベクターを含む行列の cell 配列です。
データをプロットし、サポート ベクターを特定します。
figure gscatter(X(:,1),X(:,2),Y); hold on markers = {'ko','ro','bo'}; % Should be of length L for j = 1:L svs = sv{j}; plot(svs(:,1),svs(:,2),markers{j},... 'MarkerSize',10 + (j - 1)*3); end title('Fisher''s Iris -- ECOC Support Vectors') xlabel(predictorNames{1}) ylabel(predictorNames{2}) legend([classNames,{'Support vectors - SVM 1',... 'Support vectors - SVM 2','Support vectors - SVM 3'}],... 'Location','Best') hold off
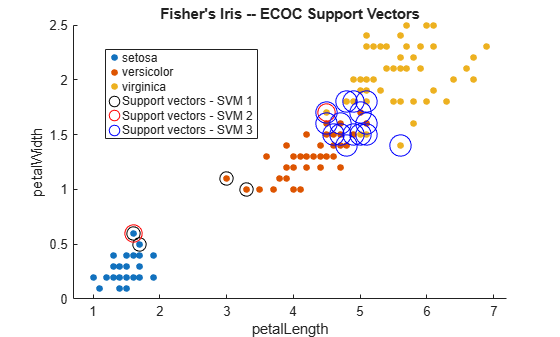
次の関数に Mdl を渡すことができます。
predict。新しい観測値を分類します。resubLoss。学習データに対する分類誤差を推定します。crossval。10 分割交差検証を実行します。
SVM バイナリ学習器による ECOC 分類器を交差検証し、一般化分類誤差を推定します。
フィッシャーのアヤメのデータ セットを読み込みます。予測子データ X と応答データ Y を指定します。
load fisheriris X = meas; Y = species; rng(1); % For reproducibility
SVM テンプレートを作成し、予測子を標準化します。
t = templateSVM('Standardize',true)t =
Fit template for SVM.
Standardize: 1
t は SVM テンプレートです。テンプレート オブジェクトのプロパティは、ほとんとが空です。ECOC 分類器に学習をさせると、該当するプロパティが既定値に設定されます。
ECOC 分類器に学習をさせ、クラスの順序を指定します。
Mdl = fitcecoc(X,Y,'Learners',t,... 'ClassNames',{'setosa','versicolor','virginica'});
Mdl は ClassificationECOC 分類器です。ドット表記を使用してプロパティにアクセスできます。
10 分割交差検証を使用して Mdl を交差検証します。
CVMdl = crossval(Mdl);
CVMdl は ClassificationPartitionedECOC 交差検証 ECOC 分類器です。
一般化分類誤差を推定します。
genError = kfoldLoss(CVMdl)
genError = 0.0400
一般化分類誤差が 4% なので、ECOC 分類器がかなり良好に一般化を行うことがわかります。
詳細
"符号化設計" は、各バイナリ学習器がどのクラスを学習したのかを要素が指示する行列です。つまり、マルチクラス問題がどのように一連のバイナリ問題にされたのかを示します。
符号化設計の各行は各クラスに対応し、各列はバイナリ学習器に対応します。三項符号化設計では、特定の列 (バイナリ学習器) に対して以下が実行されます。
1 が含まれている行の場合、対応するクラスの観測値をすべて陽性クラスにグループ化するようバイナリ学習器に指示します。
–1 が含まれている行の場合、対応するクラスの観測値をすべて陰性クラスにグループ化するようバイナリ学習器に指示します。
0 が含まれている行の場合、対応するクラスの観測値をすべて無視するようバイナリ学習器に指示します。
ハミング尺度に基づく行の最小ペアワイズ距離が大きい符号化設計行列が最適です。行のペアワイズ距離の詳細については、ランダム符号化設計行列および[2]を参照してください。
次の表は一般的な符号化設計について説明しています。
| 符号化設計 | 説明 | 学習器の数 | 行の最小ペアワイズ距離 |
|---|---|---|---|
| OVA (1 対他) | 各バイナリ学習器では、1 つのクラスは陽性で残りは陰性です。この計画は陽性クラス割り当てのすべての組み合わせを使用します。 | K | 2 |
| OVO (1 対 1) | 各バイナリ学習器では、1 つのクラスが陽性で、1 つのクラスが陰性です。残りは無視されます。この計画はすべてのクラス ペアの割り当ての組み合わせを使用します。 | K(K – 1)/2 | 1 |
| 完全二項 | この計画はクラスをすべて 2 つの組み合わせに分割します。いずれのクラスも無視されません。つまり、すべてのクラス割り当てが | 2K – 1 – 1 | 2K – 2 |
| 完全三項 | この計画はクラスをすべて 3 つの組み合わせに分割します。つまり、すべてのクラス割り当てが | (3K – 2K + 1 + 1)/2 | 3K – 2 |
| 順序 | 1 番目のバイナリ学習器では、1 番目のクラスが陰性であり、残りは陽性です。2 番目のバイナリ学習器では、最初の 2 つのクラスが陰性であり、残りは陽性です。他についても同様です。 | K – 1 | 1 |
| 密なランダム | 各バイナリ学習器には、陽性または陰性クラス (少なくとも各 1 つ) が無作為に割り当てられます。詳細については、ランダム符号化設計行列を参照してください。 | ランダム。ただし、約 10 log2K | 変数 |
| スパース ランダム | 各バイナリ学習器では、各クラスに確率 0.25 で陽性または陰性が無作為に割り当てられ、確率が 0.5 の場合にクラスが無視されます。詳細については、ランダム符号化設計行列を参照してください。 | ランダム。ただし、約 15 log2K | 変数 |
このプロットは符号化設計のバイナリ学習器の数を増加するクラス数 (K) と比較します。

アルゴリズム
代替機能
これらの代替アルゴリズムを使用してマルチクラス モデルに学習させることができます。
アンサンブル分類 —
fitcensembleおよびClassificationEnsembleを参照分類木 —
fitctreeおよびClassificationTreeを参照判別分析分類器 —
fitcdiscrおよびClassificationDiscriminantを参照k 最近傍分類器 —
fitcknnおよびClassificationKNNを参照単純ベイズ分類器 —
fitcnbおよびClassificationNaiveBayesを参照