margin
マルチクラス誤り訂正出力符号 (ECOC) モデルの分類マージン
構文
説明
m = margin(___,Name,Value)
例
SVM バイナリ学習器による ECOC モデルのテスト標本の分類マージンを計算します。
フィッシャーのアヤメのデータ セットを読み込みます。予測子データ X、応答データ Y、および Y 内のクラスの順序を指定します。
load fisheriris X = meas; Y = categorical(species); classOrder = unique(Y); % Class order rng(1) % For reproducibility
SVM バイナリ分類器を使用して ECOC モデルを学習させます。30% のホールドアウト標本を指定し、SVM テンプレートを使用して予測子を標準化し、クラスの順序を指定します。
t = templateSVM('Standardize',true); PMdl = fitcecoc(X,Y,'Holdout',0.30,'Learners',t,'ClassNames',classOrder); Mdl = PMdl.Trained{1}; % Extract trained, compact classifier
PMdl は ClassificationPartitionedECOC モデルです。これには Trained プロパティが含まれています。これは、学習セットを使用して学習をさせた CompactClassificationECOC モデルが格納されている、1 行 1 列の cell 配列です。
テスト標本の分類マージンを計算します。箱ひげ図を使用してマージンの分布を表示します。
testInds = test(PMdl.Partition); % Extract the test indices XTest = X(testInds,:); YTest = Y(testInds,:); m = margin(Mdl,XTest,YTest); boxplot(m) title('Test-Sample Margins')
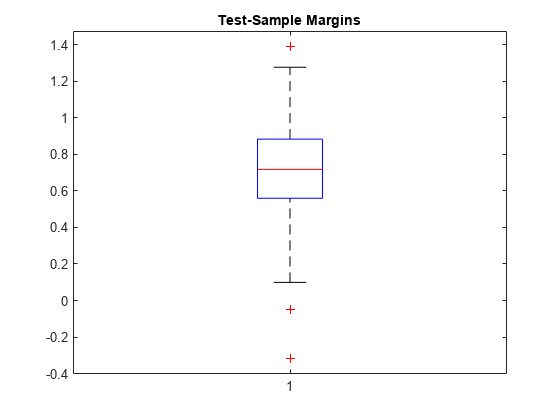
観測値の分類マージンは、符号を反転した陽性クラスの損失から符号を反転した陰性クラスの最大損失を減算した値です。マージンが比較的大きくなる分類器を選択します。
複数のモデルによるテスト標本マージンを比較することにより、特徴選択を実行します。この比較のみに基づくと、マージンが最大である分類器が最適な分類器です。
フィッシャーのアヤメのデータ セットを読み込みます。予測子データ X、応答データ Y、および Y 内のクラスの順序を指定します。
load fisheriris X = meas; Y = categorical(species); classOrder = unique(Y); % Class order rng(1); % For reproducibility
データ セットを学習セットとテスト セットに分割します。テスト用の 30% のホールドアウト標本を指定します。
Partition = cvpartition(Y,'Holdout',0.30); testInds = test(Partition); % Indices for the test set XTest = X(testInds,:); YTest = Y(testInds,:);
Partition によりデータ セットの分割が定義されます。
次の 2 つのデータ セットを定義します。
fullXには 4 つすべての予測子が含まれます。partXにはがく片の測定値のみが含まれます。
fullX = X; partX = X(:,1:2);
各予測子セットについて SVM バイナリ分類器を使用する ECOC モデルに学習をさせます。分割定義を指定し、SVM テンプレートを使用して予測子を標準化し、クラスの順序を定義します。
t = templateSVM('Standardize',true); fullPMdl = fitcecoc(fullX,Y,'CVPartition',Partition,'Learners',t,... 'ClassNames',classOrder); partPMdl = fitcecoc(partX,Y,'CVPartition',Partition,'Learners',t,... 'ClassNames',classOrder); fullMdl = fullPMdl.Trained{1}; partMdl = partPMdl.Trained{1};
fullPMdl および partPMdl は ClassificationPartitionedECOC モデルです。各モデルには Trained プロパティが含まれています。これは、対応する学習セットを使用して学習をさせた CompactClassificationECOC モデルが格納されている、1 行 1 列の cell 配列です。
各分類器のテスト標本マージンを計算します。モデルごとに箱ひげ図を使用してマージンの分布を表示します。
fullMargins = margin(fullMdl,XTest,YTest); partMargins = margin(partMdl,XTest(:,1:2),YTest); boxplot([fullMargins partMargins],'Labels',{'All Predictors','Two Predictors'}) title('Boxplots of Test-Sample Margins')
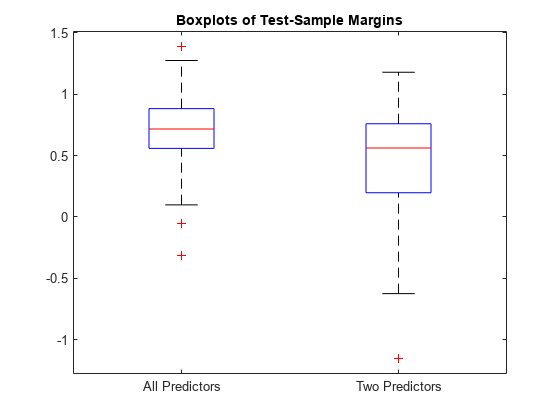
fullMdl のマージンの分布は、partMdl のマージンの分布よりも高い位置にあり、変動性がより少なくなっています。
入力引数
名前と値の引数
出力引数
詳細
ヒント
複数の ECOC 分類器のマージンまたはエッジを比較するには、テンプレート オブジェクトを使用して分類器間で共通するスコア変換関数を学習時に指定します。
参照
拡張機能
バージョン履歴
R2014b で導入
参考
ClassificationECOC | CompactClassificationECOC | edge | resubMargin | predict | fitcecoc | loss