このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fitcnb
マルチクラス単純ベイズ モデルの学習
構文
説明
Mdl = fitcnb(Tbl,ResponseVarName)Tbl 内の予測子と変数 Tbl.ResponseVarName のクラス ラベルによって学習させたマルチクラスの単純ベイズ モデル (Mdl) を返します。
Mdl = fitcnb(___,Name,Value)Name,Value ペア引数で指定されたオプションを追加して、単純ベイズ分類器を返します。たとえば、クラスの事前確率やカーネル平滑化ウィンドウ帯域幅など、データをモデル化するための分布を指定できます。
[ は、名前と値の引数 Mdl,AggregateOptimizationResults] = fitcnb(___)OptimizeHyperparameters と HyperparameterOptimizationOptions が指定されている場合に、ハイパーパラメーターの最適化の結果が格納された AggregateOptimizationResults も返します。HyperparameterOptimizationOptions の ConstraintType オプションと ConstraintBounds オプションも指定する必要があります。この構文を使用すると、交差検証損失ではなくコンパクトなモデル サイズに基づいて最適化したり、オプションは同じでも制約範囲は異なる複数の一連の最適化問題を実行したりできます。
メモ
入力変数が tall 配列の場合のサポートされている構文のリストについては、tall 配列を参照してください。
例
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris
X = meas(:,3:4);
Y = species;
tabulate(Y) Value Count Percent
setosa 50 33.33%
versicolor 50 33.33%
virginica 50 33.33%
単純ベイズ メソッドを使用して、3 つ以上のクラスがあるデータを分類することができます。
単純ベイズ分類器を学習させます。クラスの順序を指定することをお勧めします。
Mdl = fitcnb(X,Y,'ClassNames',{'setosa','versicolor','virginica'})
Mdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
DistributionNames: {'normal' 'normal'}
DistributionParameters: {3×2 cell}
Properties, Methods
Mdl は学習させた ClassificationNaiveBayes 分類器です。
既定の設定では、いくつかの平均と標準偏差をもつガウス分布を使用して、各クラス内で予測子分布がモデル化されます。ドット表記を使用して特定のガウス近似のパラメーターを表示します。たとえば、setosa 内にある最初の特徴の近似を表示します。
setosaIndex = strcmp(Mdl.ClassNames,'setosa');
estimates = Mdl.DistributionParameters{setosaIndex,1}estimates = 2×1
1.4620
0.1737
平均値は 1.4620 で、標準偏差は 0.1737 です。
ガウス等高線をプロットします。
figure gscatter(X(:,1),X(:,2),Y); h = gca; cxlim = h.XLim; cylim = h.YLim; hold on Params = cell2mat(Mdl.DistributionParameters); Mu = Params(2*(1:3)-1,1:2); % Extract the means Sigma = zeros(2,2,3); for j = 1:3 Sigma(:,:,j) = diag(Params(2*j,:)).^2; % Create diagonal covariance matrix xlim = Mu(j,1) + 4*[-1 1]*sqrt(Sigma(1,1,j)); ylim = Mu(j,2) + 4*[-1 1]*sqrt(Sigma(2,2,j)); f = @(x,y) arrayfun(@(x0,y0) mvnpdf([x0 y0],Mu(j,:),Sigma(:,:,j)),x,y); fcontour(f,[xlim ylim]) % Draw contours for the multivariate normal distributions end h.XLim = cxlim; h.YLim = cylim; title('Naive Bayes Classifier -- Fisher''s Iris Data') xlabel('Petal Length (cm)') ylabel('Petal Width (cm)') legend('setosa','versicolor','virginica') hold off

名前と値のペアの引数 'DistributionNames' を使用すると、既定の分布を変更できます。たとえば、一部の予測子がカテゴリカルである場合、'DistributionNames','mvmn' を使用して、これらの予測子が多変量多項確率変数となるよう指定することができます。
フィッシャーのアヤメのデータ セット用に単純ベイズ分類器を構築します。また、学習中の事前確率を指定します。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris X = meas; Y = species; classNames = {'setosa','versicolor','virginica'}; % Class order
X は、150 本のアヤメについて 4 つの測定値が含まれている数値行列です。Y は、対応するアヤメの種類が含まれている文字ベクトルの cell 配列です。
既定では、前のクラス確率分布はデータ セット内のクラスの相対頻度の分布です。この場合、事前確率は各種類に対して 33% です。ただし、母集団の 50% は setosa、20% は versicolor、30% は virginica であることはわかっているとします。学習中にこの分布を事前確率として指定すると、この情報を組み込むことができます。
単純ベイズ分類器を学習させます。クラスの順序と前のクラスの確率分布を指定します。
prior = [0.5 0.2 0.3]; Mdl = fitcnb(X,Y,'ClassNames',classNames,'Prior',prior)
Mdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
DistributionNames: {'normal' 'normal' 'normal' 'normal'}
DistributionParameters: {3×4 cell}
Properties, Methods
Mdl は学習させた ClassificationNaiveBayes 分類器であり、一部のプロパティはコマンド ウィンドウに表示されます。クラスが与えられている場合、予測子は独立しているとして扱われ、また既定では、正規分布を使用して当てはめが行われます。
単純ベイズ アルゴリズムは前のクラスの確率を学習中に使用しません。したがって、前のクラス確率を学習後にドット表記を使用して指定できます。たとえば、既定のクラスの事前確率を使用するモデルと異なる prior を使用するモデルの間でパフォーマンスの違いを比較するとします。
Mdl に基づいて新しい単純ベイズモデルを作成し、前のクラスの確率分布に経験的クラス分布を指定します。
defaultPriorMdl = Mdl;
FreqDist = cell2table(tabulate(Y));
defaultPriorMdl.Prior = FreqDist{:,3};前のクラスの確率は合計が 1 になるように正規化されます。
10 分割交差検証を使用して、両方のモデルの交差検証誤差を推定します。
rng(1); % For reproducibility
defaultCVMdl = crossval(defaultPriorMdl);
defaultLoss = kfoldLoss(defaultCVMdl)defaultLoss = 0.0533
CVMdl = crossval(Mdl); Loss = kfoldLoss(CVMdl)
Loss = 0.0340
Mdl の方が defaultPriorMdl よりパフォーマンスが優れています。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris
X = meas;
Y = species;すべての予測子を使用して単純ベイズ分類器を学習させます。クラスの順序を指定することをお勧めします。
Mdl1 = fitcnb(X,Y,... 'ClassNames',{'setosa','versicolor','virginica'})
Mdl1 =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
DistributionNames: {'normal' 'normal' 'normal' 'normal'}
DistributionParameters: {3×4 cell}
Properties, Methods
Mdl1.DistributionParameters
ans=3×4 cell array
{2×1 double} {2×1 double} {2×1 double} {2×1 double}
{2×1 double} {2×1 double} {2×1 double} {2×1 double}
{2×1 double} {2×1 double} {2×1 double} {2×1 double}
Mdl1.DistributionParameters{1,2}ans = 2×1
3.4280
0.3791
既定の設定では、各クラス内の予測子分布が、いくつかの平均と標準偏差をもつガウス分布としてモデル化されます。予測子は 4 つあり、クラス レベルは 3 つあります。Mdl1.DistributionParameters の各セルは、各分布の平均と標準偏差が格納された数値ベクトルに対応します。たとえば、setosa のがく片の幅の平均と標準偏差はそれぞれ 3.4280 と 0.3791 です。
Mdl1 の混同行列を推定します。
isLabels1 = resubPredict(Mdl1); ConfusionMat1 = confusionchart(Y,isLabels1);
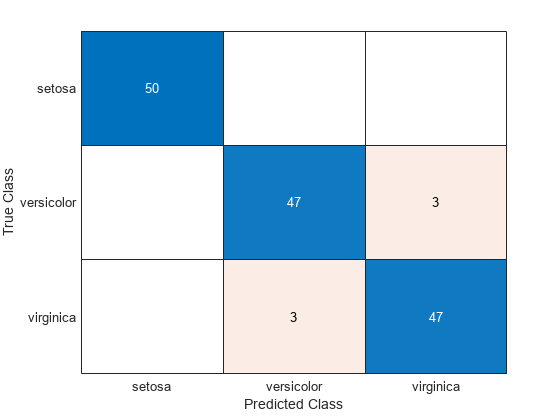
混同行列チャートの要素 (j, k) は、k として分類されているが、データに従うと実際にはクラス j に属している観測値の個数を表します。
予測子 1 および 2 (がく片の長さと幅) のガウス分布および予測子 3 と 4 (花弁の長さと幅) の既定の正規カーネル密度を使用して、分類器を再度学習させます。
Mdl2 = fitcnb(X,Y,... 'DistributionNames',{'normal','normal','kernel','kernel'},... 'ClassNames',{'setosa','versicolor','virginica'}); Mdl2.DistributionParameters{1,2}
ans = 2×1
3.4280
0.3791
カーネル密度のパラメーターの学習は実行されません。その代わりに、最適な幅が自動的に選択されます。ただし、'Width' 名前と値のペアの引数を使用して幅を指定することができます。
Mdl2 の混同行列を推定します。
isLabels2 = resubPredict(Mdl2); ConfusionMat2 = confusionchart(Y,isLabels2);

混同行列に基づいて、2 つの分類器は学習標本内で同様に動作します。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris X = meas; Y = species; rng(1); % For reproducibility
既定のオプションと k 分割交差検証を使用して、単純ベイズ分類器の学習と交差検証を行います。クラスの順序を指定することをお勧めします。
CVMdl1 = fitcnb(X,Y,... 'ClassNames',{'setosa','versicolor','virginica'},... 'CrossVal','on');
既定の設定では、何らかの平均と標準偏差をもつガウス分布として各クラス内の予測子分布がモデル化されます。CVMdl1 は ClassificationPartitionedModel モデルです。
既定の単純ベイズ バイナリ分類器テンプレートを作成し、誤り訂正出力符号のマルチクラス モデルを学習させます。
t = templateNaiveBayes(); CVMdl2 = fitcecoc(X,Y,'CrossVal','on','Learners',t);
CVMdl2 は ClassificationPartitionedECOC モデルです。単純ベイズ バイナリ学習器のオプションを fitcnb と同じ名前と値のペアの引数を使用して指定できます。
標本外の k 分割分類誤差 (誤分類された観測値の比率) を比較します。
classErr1 = kfoldLoss(CVMdl1,'LossFun','ClassifErr')
classErr1 = 0.0533
classErr2 = kfoldLoss(CVMdl2,'LossFun','ClassifErr')
classErr2 = 0.0467
Mdl2 の方が汎化誤差が小さくなります。
スパム フィルターによっては、電子メール内の単語や句読点 (トークン) の使用頻度を基準にして、受信した電子メールをスパムとして分類します。予測子は電子メールに含まれる特定の単語または句読点が使用される頻度です。したがって、予測子は多項確率変数を作成します。
この例では、単純ベイズ予測子と多項予測子を使用した分類を説明します。
学習データの作成
1,000 件の電子メールを観測し、スパムまたはスパム以外に分類したとします。この処理を行うには、各電子メールに対応する y に -1 または 1 を無作為に割り当てます。
n = 1000; % Sample size rng(1); % For reproducibility Y = randsample([-1 1],n,true); % Random labels
予測子データを構築するため、語彙集に 5 つのトークンが存在し、電子メールごとに 20 のトークンが観測されたと仮定します。多項偏差を無作為に抽出して 5 つのトークンから予測子データを生成します。スパム電子メールに対応するトークンの相対的頻度は、スパム以外の電子メールとは異なっていなければなりません。
tokenProbs = [0.2 0.3 0.1 0.15 0.25;... 0.4 0.1 0.3 0.05 0.15]; % Token relative frequencies tokensPerEmail = 20; % Fixed for convenience X = zeros(n,5); X(Y == 1,:) = mnrnd(tokensPerEmail,tokenProbs(1,:),sum(Y == 1)); X(Y == -1,:) = mnrnd(tokensPerEmail,tokenProbs(2,:),sum(Y == -1));
分類器の学習
単純ベイズ分類器を学習させます。予測子が多項予測子となるよう指定します。
Mdl = fitcnb(X,Y,'DistributionNames','mn');
Mdl は学習させた ClassificationNaiveBayes 分類器です。
誤分類誤差を推定して、Mdl の標本内パフォーマンスを評価します。
isGenRate = resubLoss(Mdl,'LossFun','ClassifErr')
isGenRate = 0.0320
標本内の誤分類率は 2% です。
新しいデータの作成
電子メールの新しいバッチを表す偏差を無作為に生成します。
newN = 500; newY = randsample([-1 1],newN,true); newX = zeros(newN,5); newX(newY == 1,:) = mnrnd(tokensPerEmail,tokenProbs(1,:),... sum(newY == 1)); newX(newY == -1,:) = mnrnd(tokensPerEmail,tokenProbs(2,:),... sum(newY == -1));
分類器のパフォーマンス評価
学習させた単純ベイズ分類器 Mdl を使用して新しい電子メールを分類し、アルゴリズムが一般化するかどうかを判別します。
oosGenRate = loss(Mdl,newX,newY)
oosGenRate = 0.0160
標本外の誤分類率が 2.6% であるため、分類器が良好に一般化されていることを示しています。
この例では、fitcnb で名前と値のペア OptimizeHyperparameters を使用して単純ベイズ分類器の交差検証損失を最小化する方法を示します。この例では、フィッシャーのアヤメのデータを使用します。
フィッシャーのアヤメのデータを読み込みます。
load fisheriris X = meas; Y = species; classNames = {'setosa','versicolor','virginica'};
'auto' パラメーターを使用して分類を最適化します。
再現性を得るために、乱数シードを設定し、'expected-improvement-plus' の獲得関数を使用します。
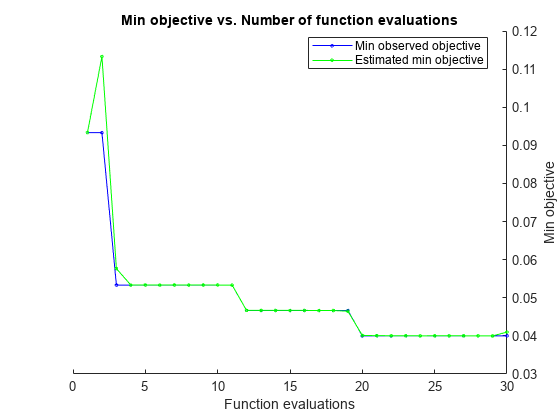
rng default Mdl = fitcnb(X,Y,'ClassNames',classNames,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName',... 'expected-improvement-plus'))
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Distribution-| Width | Standardize |
| | result | | runtime | (observed) | (estim.) | Names | | |
|====================================================================================================================|
| 1 | Best | 0.093333 | 0.63009 | 0.093333 | 0.093333 | kernel | 5.6939 | false |
| 2 | Accept | 0.13333 | 0.17381 | 0.093333 | 0.11333 | kernel | 94.849 | true |
| 3 | Best | 0.053333 | 0.11507 | 0.053333 | 0.05765 | normal | - | - |
| 4 | Accept | 0.053333 | 0.063932 | 0.053333 | 0.053336 | normal | - | - |
| 5 | Accept | 0.26667 | 0.14426 | 0.053333 | 0.053338 | kernel | 0.001001 | true |
| 6 | Accept | 0.093333 | 0.13298 | 0.053333 | 0.053337 | kernel | 10.043 | false |
| 7 | Accept | 0.26667 | 0.13179 | 0.053333 | 0.05334 | kernel | 0.0010132 | false |
| 8 | Accept | 0.093333 | 0.13444 | 0.053333 | 0.053338 | kernel | 985.05 | false |
| 9 | Accept | 0.13333 | 0.12713 | 0.053333 | 0.053338 | kernel | 993.63 | true |
| 10 | Accept | 0.053333 | 0.053321 | 0.053333 | 0.053336 | normal | - | - |
| 11 | Accept | 0.053333 | 0.044385 | 0.053333 | 0.053336 | normal | - | - |
| 12 | Best | 0.046667 | 0.14863 | 0.046667 | 0.046679 | kernel | 0.30205 | true |
| 13 | Accept | 0.11333 | 0.12714 | 0.046667 | 0.046685 | kernel | 1.3021 | true |
| 14 | Accept | 0.053333 | 0.13106 | 0.046667 | 0.046695 | kernel | 0.10521 | true |
| 15 | Accept | 0.046667 | 0.14308 | 0.046667 | 0.046677 | kernel | 0.25016 | false |
| 16 | Accept | 0.06 | 0.12311 | 0.046667 | 0.046686 | kernel | 0.58328 | false |
| 17 | Accept | 0.046667 | 0.14466 | 0.046667 | 0.046656 | kernel | 0.07969 | false |
| 18 | Accept | 0.093333 | 0.12182 | 0.046667 | 0.046654 | kernel | 131.33 | false |
| 19 | Accept | 0.046667 | 0.12394 | 0.046667 | 0.04648 | kernel | 0.13384 | false |
| 20 | Best | 0.04 | 0.12122 | 0.04 | 0.040132 | kernel | 0.19525 | true |
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Distribution-| Width | Standardize |
| | result | | runtime | (observed) | (estim.) | Names | | |
|====================================================================================================================|
| 21 | Accept | 0.04 | 0.12331 | 0.04 | 0.040066 | kernel | 0.19458 | true |
| 22 | Accept | 0.04 | 0.15832 | 0.04 | 0.040043 | kernel | 0.19601 | true |
| 23 | Accept | 0.04 | 0.13994 | 0.04 | 0.040031 | kernel | 0.19412 | true |
| 24 | Accept | 0.10667 | 0.12335 | 0.04 | 0.040018 | kernel | 0.0084391 | true |
| 25 | Accept | 0.073333 | 0.12343 | 0.04 | 0.040022 | kernel | 0.02769 | false |
| 26 | Accept | 0.04 | 0.12232 | 0.04 | 0.04002 | kernel | 0.2037 | true |
| 27 | Accept | 0.13333 | 0.12301 | 0.04 | 0.040021 | kernel | 12.501 | true |
| 28 | Accept | 0.11333 | 0.13749 | 0.04 | 0.040006 | kernel | 0.0048728 | false |
| 29 | Accept | 0.1 | 0.12412 | 0.04 | 0.039993 | kernel | 0.028653 | true |
| 30 | Accept | 0.046667 | 0.14424 | 0.04 | 0.041008 | kernel | 0.18725 | true |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 11.9404 seconds
Total objective function evaluation time: 4.2554
Best observed feasible point:
DistributionNames Width Standardize
_________________ _______ ___________
kernel 0.19525 true
Observed objective function value = 0.04
Estimated objective function value = 0.041117
Function evaluation time = 0.12122
Best estimated feasible point (according to models):
DistributionNames Width Standardize
_________________ ______ ___________
kernel 0.2037 true
Estimated objective function value = 0.041008
Estimated function evaluation time = 0.1332
Mdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
DistributionNames: {'kernel' 'kernel' 'kernel' 'kernel'}
DistributionParameters: {3×4 cell}
Kernel: {'normal' 'normal' 'normal' 'normal'}
Support: {'unbounded' 'unbounded' 'unbounded' 'unbounded'}
Width: [3×4 double]
Mu: [5.8433 3.0573 3.7580 1.1993]
Sigma: [0.8281 0.4359 1.7653 0.7622]
Properties, Methods
入力引数
名前と値の引数
出力引数
詳細
ヒント
bag-of-tokens モデルなどのカウントベース データを分類するには、多項分布を使用します (たとえば、
'DistributionNames','mn'を設定するなど)。モデルに学習をさせた後で、新しいデータについてラベルを予測する C/C++ コードを生成できます。C/C++ コードの生成には MATLAB Coder™ が必要です。詳細については、統計と機械学習の関数のコード生成の紹介を参照してください。
アルゴリズム
予測子変数
jが条件付き正規分布をもつ場合 (名前と値の引数DistributionNamesを参照)、クラス固有の加重平均、および加重標準偏差の不偏推定を計算することにより、この分布がデータに当てはめられます。各クラス k に対して以下を実行します。予測子 j の加重平均は次のようになります。
ここで wi は観測値 i の重みです。クラス内の重みは、その合計がクラスの事前確率になるように正規化されます。
予測子 j の加重標準偏差の不偏推定器は次のようになります。
ここで z1|k はクラス k 内の重みの合計、z2|k はクラス k 内の重みの 2 乗の合計です。
すべての予測子変数が条件付き多項分布 (
'DistributionNames','mn'を指定) を構成する場合、bag-of-tokens モデルを使用して、この分布が当てはめられます。トークンjがプロパティDistributionParameters{のクラスk,j}kに出現する確率が保存されます。加法平滑化[2]を使用すると、推定確率は次のようになります。ここで
はクラス k におけるトークン j の重み付き発生数です。
nk はクラス k 内の観測数です。
は観測値 i の重みです。クラス内の重みは、その合計がクラスの事前確率になるように正規化されます。
は、クラス k に含まれているすべてのトークンの重み付き発生数の合計です。
予測子変数
jが条件付き多変量多項分布を持つ場合、次のようになります。一意のレベルのリストが収集され、並べ替えられたリストは
CategoricalLevelsに保存され、各レベルはビンと見なされます。予測子とクラスの各組み合わせは、個別の独立した多項確率変数です。各クラス
kに対して、CategoricalLevels{に保存されたリストを使用して、カテゴリカル レベルごとのインスタンスがカウントされます。j}クラス
kの予測子jが、プロパティDistributionParameters{においてレベル L をもつ場合、すべてのレベルの確率はk,j}CategoricalLevels{に保存されます。加法平滑化[2]を使用すると、推定確率は次のようになります。j}ここで
は、クラス k 内の予測子 j が L に等しい観測値の重み付き個数です。
nk はクラス k 内の観測数です。
xij = L の場合は 、それ以外の場合は 0 です。
は観測値 i の重みです。クラス内の重みは、その合計がクラスの事前確率になるように正規化されます。
mj は予測子 j の異なるレベルの数です。
mk はクラス k 内の重み付けされた観測値の数です。
名前と値の引数
Cost、Prior、およびWeightsを指定すると、出力モデル オブジェクトにCost、Prior、およびWの各プロパティの指定値がそれぞれ格納されます。Costプロパティには、ユーザー指定のコスト行列がそのまま格納されます。PriorプロパティとWプロパティには、正規化後の事前確率と観測値の重みがそれぞれ格納されます。詳細については、誤分類コスト行列、事前確率、および観測値の重みを参照してください。Costプロパティは予測に使用されますが、学習には使用されません。したがって、Costは読み取り専用ではなく、学習済みモデルの作成後にドット表記を使用してプロパティの値を変更できます。
参照
[1] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning, Second Edition. NY: Springer, 2008.