単純ベイズと異種混合データでのインクリメンタル学習
この例では、実数値とカテゴリカルの測定値を含む異種混合の予測子データについて、単純ベイズ分類器を使用するインクリメンタル学習用に準備する方法を示します。
インクリメンタル学習用の単純ベイズ分類器は、数値予測子データ セットのみをサポートしますが、学習中に未観測のカテゴリカル レベルに適応できます。データが異種混合で table に格納されている場合は、インクリメンタル学習を実行する前に次の一般的な手順に従って前処理する必要があります。
各カテゴリカル変数に対して、
container.MapMATLAB® オブジェクトを使用してランニング ハッシュ マップを作成します。ハッシュ マップで一意の数値に文字列を割り当てることで、新しいレベルに簡単に適応できます。コールド ハッシュ マップを作成できますが、この例では、ハッシュ マップの作成とモデルのウォームアップに最初の 50 個の観測値をデータから使用できるものとします。すべての実数値の測定値を一貫した方法で数値カテゴリカル レベルと連結します。
データの読み込みと前処理
1994 年の米国国勢調査データ セットを読み込みます。学習の目的は、米国国民の給与 (salary が <=50K か >50K か) を国民に関するいくつかの異種混合の測定値から予測することです。
load census1994.mat学習データは table adultdata にあります。データ セットの詳細については、Description を入力してください。
欠損値が少なくとも 1 つ含まれている観測値をデータからすべて削除します。
adultdata = adultdata(~any(ismissing(adultdata),2),:);
[n,p] = size(adultdata);
p = p - 1; % Number of predictor variables 現在使用できるのは最初の 50 個の観測値のみであると仮定します。
n0 = 50; sample0 = adultdata(1:n0,:);
初期ハッシュ マップの作成
データ内のすべてのカテゴリカル変数を特定し、それらのレベルを調べます。
catpredidx = table2array(varfun(@iscategorical,adultdata(:,1:(end-1))));
numcatpreds = sum(catpredidx);
lvlstmp = varfun(@unique,adultdata(:,catpredidx),OutputFormat="cell");
lvls0 = cell(1,p);
lvls0(catpredidx) = lvlstmp;各カテゴリカル変数に対して、各レベルに 1 から対応するレベルの数までの整数を割り当てる初期ハッシュ マップを作成します。すべてのハッシュ マップを cell ベクトルに格納します。
catmaps = cell(1,p); J = find(catpredidx); for j = J numlvls = numel(lvls0{j}); catmaps{j} = containers.Map(cellstr(lvls0{j}),1:numlvls); end example1 = catmaps{find(catpredidx,1)}
example1 =
Map with properties:
Count: 7
KeyType: char
ValueType: double
val = example1('Private')val = 3
catmaps は、それぞれが対応するカテゴリカル変数のハッシュ マップを表す containers.Map オブジェクトの numcatpreds 行 1 列の cell ベクトルです。たとえば、1 番目のハッシュ マップはレベル 'Private' に 3 を割り当てます。
カテゴリカル変数の数値での表現
サポートのローカル関数 processPredictorData には次の特性があります。
カテゴリカル変数と数値変数を含む table、および各カテゴリカル変数に対する現在のハッシュ マップの cell ベクトルを受け入れます。
カテゴリカル変数を数値変数に置き換えた同種の数値予測子データの行列を返します。文字列ベースのレベルが関数によって正の整数に置き換えられます。
現在のハッシュ マップでレベルを特定できない変数が入力データに含まれている場合、更新されたハッシュ マップの cell ベクトルを返します。
processPredictorData を使用して、初期標本に含まれるカテゴリカル データを数値として表現します。
[X0,catmaps] = processPredictorData(sample0(:,1:(end-1)),catmaps); y0 = adultdata.salary(1:n0);
初期標本への単純ベイズ モデルの当てはめ
単純ベイズ モデルを初期標本に当てはめます。カテゴリカル変数を特定します。
Mdl = fitcnb(X0,y0,CategoricalPredictors=catpredidx);
Mdl は ClassificationNaiveBayes モデルです。
インクリメンタル学習用の単純ベイズ モデルの準備
従来式の学習済み単純ベイズ モデルをインクリメンタル学習器に変換します。インクリメンタル モデルのウィンドウ メトリクスを 2000 個の観測値に基づくように指定します。
IncrementalMdl = incrementalLearner(Mdl,MetricsWindowSize=2000);
IncrementalMdl は、インクリメンタル学習用に準備されたウォームアップ済みの incrementalClassificationNaiveBayes オブジェクトです。incrementalLearner は、初期標本から学習した値を使用して、予測子変数の条件付き分布のパラメーターを初期化します。
インクリメンタル学習の実行
モデルの性能を測定し、関数 updateMetricsAndFit を使用して、インクリメンタル モデルを学習データに当てはめます。100 個の観測値のチャンクを一度に処理して、データ ストリームをシミュレートします。各反復で次を行います。
processPredictorDataを使用して、100 個の入力観測値の予測子データを処理してハッシュ マップを更新。処理したデータに単純ベイズ モデルを当てはめ。
前のインクリメンタル モデルを、入力観測値に当てはめた新しいモデルで上書きします。
現在の最小コストと学習した条件付き確率 (米国女性が各給与水準で選択される確率) を保存。
numObsPerChunk = 100; nchunks = floor(n/numObsPerChunk); mc = array2table(zeros(nchunks,2),'VariableNames',["Cumulative" "Window"]); catdistms = zeros(nchunks,2); sexidx = string(adultdata.Properties.VariableNames) == "sex"; fidx = string(keys(catmaps{sexidx(1:end-1)})) == "Female"; for j = 1:nchunks ibegin = min(n,numObsPerChunk*(j-1) + 1 + n0); iend = min(n,numObsPerChunk*j + n0); idx = ibegin:iend; [XChunk,catmaps] = processPredictorData(adultdata(idx,1:(end-1)),catmaps); IncrementalMdl = updateMetricsAndFit(IncrementalMdl,XChunk,adultdata.salary(idx)); mc{j,:} = IncrementalMdl.Metrics{"MinimalCost",:}; catdistms(j,1) = IncrementalMdl.DistributionParameters{1,sexidx}(fidx); catdistms(j,2) = IncrementalMdl.DistributionParameters{2,sexidx}(fidx); end
IncrementalMdl は、ストリーム全体にインクリメンタルに適合する incrementalClassificationNaiveBayes オブジェクトです。インクリメンタル学習中、updateMetricsAndFit は観測値の入力チャンクでモデルの性能をチェックし、モデルをその観測値に当てはめます。
インクリメンタル学習で計算された累積とウィンドウの最小コストをプロットします。
figure plot(mc.Variables) ylabel('Minimal Cost') legend(mc.Properties.VariableNames) xlabel('Iteration')
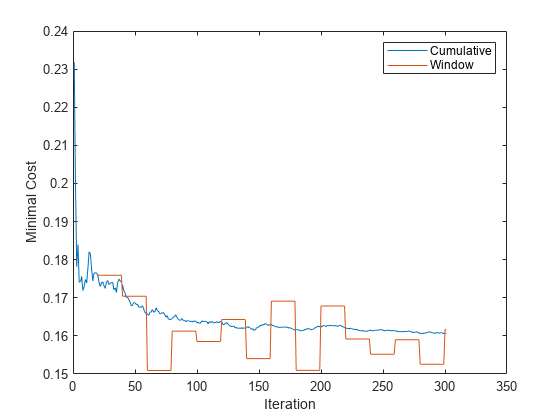
累積の損失は反復 (100 個の観測値のチャンク) ごとに徐々に変化しますが、ウィンドウの損失には急な変動があります。メトリクス ウィンドウは 2000 なので、updateMetricsAndFit は 20 回の反復ごとに性能を測定します。
女性が各給与水準で選択されるランニング確率をプロットします。
figure plot(catdistms) ylabel('P(Female|Salary=y)') legend(sprintf("y=%s",IncrementalMdl.ClassNames(1)),sprintf("y=%s",IncrementalMdl.ClassNames(2))) xlabel('Iteration')
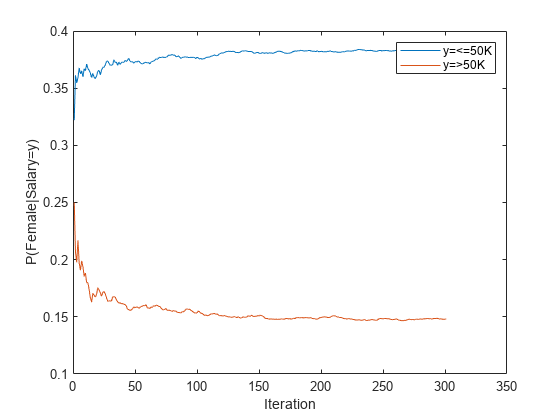
当てはめられる確率がインクリメンタル学習中に徐々に安定します。
テスト データでの性能の比較
単純ベイズ分類器を学習データ セット全体に当てはめます。
MdlTT = fitcnb(adultdata,"salary");MdlTT は、従来式の学習済み ClassificationNaiveBayes オブジェクトです。
テスト データ adulttest で従来式の学習済みモデルの最小コストを計算します。
adulttest = adulttest(~any(ismissing(adulttest),2),:); % Remove missing values
mctt = loss(MdlTT,adulttest)mctt = 0.1773
processPredictorData を使用してテスト データの予測子を処理してから、テスト データでインクリメンタル学習モデルの最小コストを計算します。
XTest = processPredictorData(adulttest(:,1:(end-1)),catmaps); ilmc = loss(IncrementalMdl,XTest,adulttest.salary)
ilmc = 0.1657
インクリメンタル モデルと従来式の学習済みモデルで、最小コストはほぼ同じです。
サポート関数
function [Pred,maps] = processPredictorData(tbl,maps) % PROCESSPREDICTORDATA Process heterogeneous data to homogeneous numeric % data % % Input arguments: % tbl: A table of raw input data % maps: A cell vector of container.Map hash maps. Cells correspond to % categorical variables in tbl. % % Output arguments: % Pred: A numeric matrix of data with the same dimensions as tbl. Numeric % variables in tbl are assigned to the corresponding column of Pred, % categorical variables in tbl are processed and placed in the % corresponding column of Pred. catidx = varfun(@iscategorical,tbl,OutputFormat="uniform"); numidx = ~catidx; numcats = sum(catidx); p = numcats + sum(numidx); currlvlstmp = varfun(@unique,tbl(:,catidx),OutputFormat="cell"); currlvls0 = cell(1,p); currlvls0(catidx) = currlvlstmp; currlvlstmp = cellfun(@categories,currlvls0(catidx),UniformOutput=false); currlvls = cell(1,p); currlvls(catidx) = currlvlstmp; Pred = zeros(size(tbl)); Pred(:,numidx) = tbl{:,numidx}; J = find(catidx); for j = J hasNewlvl = ~isKey(maps{j},currlvls{j}); if any(hasNewlvl) newcats = currlvls{j}(hasNewlvl); numnewcats = sum(hasNewlvl); g = numel(maps{j}.Count); for h = 1:numnewcats g = g + 1; maps{j}(newcats{h}) = g; end end conv2cell = cellstr(tbl{:,j}); Pred(:,j) = cell2mat(values(maps{j},conv2cell)); end end
参考
オブジェクト
関数
loss|fit|updateMetrics