loss
データのバッチでの単純ベイズ インクリメンタル学習分類モデルの損失
説明
loss は、構成されたインクリメンタル学習用の単純ベイズ分類モデル (incrementalClassificationNaiveBayes オブジェクト) の分類損失を返します。
データ ストリームでのモデルの性能を測定し、結果を出力モデルに保存するには、updateMetrics または updateMetricsAndFit を呼び出します。
例
ストリーミング データでインクリメンタル モデルの性能を測定する方法は 3 通りあります。
累積メトリクスで、インクリメンタル学習の開始以降の性能を測定します。
ウィンドウ メトリクスで、指定した観測値ウィンドウでの性能を測定します。指定したウィンドウをモデルが処理するたびにメトリクスが更新されます。
関数
lossで、指定したデータのバッチについてのみ性能を測定します。
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
インクリメンタル学習用の単純ベイズ分類モデルを作成します。クラス名を指定し、メトリクス ウィンドウ サイズを観測値 1000 個に指定します。モデルを最初の 10 個の観測値に当てはめて loss 用に構成します。
Mdl = incrementalClassificationNaiveBayes('ClassNames',unique(Y),'MetricsWindowSize',1000); initobs = 10; Mdl = fit(Mdl,X(1:initobs,:),Y(1:initobs)); canComputeLoss = (size(Mdl.DistributionParameters,2) == Mdl.NumPredictors) + ... (size(Mdl.DistributionParameters,1) > 1) > 1
canComputeLoss = logical
1
Mdl は incrementalClassificationNaiveBayes モデルです。そのプロパティはすべて読み取り専用です。
データ ストリームをシミュレートし、500 個の観測値の入力チャンクごとに次のアクションを実行します。
updateMetricsを呼び出して、累積性能および観測値ウィンドウ内での性能を測定します。前のインクリメンタル モデルを新しいモデルで上書きして、パフォーマンス メトリクスを追跡します。lossを呼び出して、入力チャンクでのモデルの性能を測定します。fitを呼び出して、モデルを入力チャンクに当てはめます。前のインクリメンタル モデルを、入力観測値に当てはめた新しいモデルで上書きします。すべてのパフォーマンス メトリクスを保存して、インクリメンタル学習中にそれらがどのように進化するかを確認します。
% Preallocation numObsPerChunk = 500; nchunk = floor((n - initobs)/numObsPerChunk); mc = array2table(zeros(nchunk,3),'VariableNames',["Cumulative" "Window" "Chunk"]); % Incremental learning for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1 + initobs); iend = min(n,numObsPerChunk*j + initobs); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(idx,:),Y(idx)); mc{j,["Cumulative" "Window"]} = Mdl.Metrics{"MinimalCost",:}; mc{j,"Chunk"} = loss(Mdl,X(idx,:),Y(idx)); Mdl = fit(Mdl,X(idx,:),Y(idx)); end
Mdl は、ストリーム内のすべてのデータで学習させた incrementalClassificationNaiveBayes モデル オブジェクトになります。インクリメンタル学習中およびモデルがウォームアップされた後、updateMetrics は入力観測値でのモデルの性能をチェックし、関数 fit はモデルをそれらの観測値に当てはめます。loss はメトリクスのウォームアップ期間に依存しないため、すべてのチャンクについて最小コストを測定します。
パフォーマンス メトリクスが学習中にどのように進化するかを確認するには、それらをプロットします。
figure plot(mc.Variables) xlim([0 nchunk]) ylim([0 0.1]) ylabel('Minimal Cost') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk + 1,'r-.') legend(mc.Properties.VariableNames) xlabel('Iteration')

黄色の線は、入力データの各チャンクの最小コストを表します。メトリクスのウォームアップ期間後、Mdl は累積およびウィンドウ メトリクスを追跡します。
インクリメンタル学習用の単純ベイズ分類モデルをストリーミング データに当てはめ、データの入力チャンクでマルチクラス クロス エントロピー損失を計算します。
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。
load humanactivity n = numel(actid); rng(1); % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
インクリメンタル学習用の単純ベイズ分類モデルを作成します。次のようにモデルを構成します。
クラス名を指定します。
メトリクスのウォームアップ期間を観測値 1000 個に指定します。
メトリクス ウィンドウ サイズを観測値 2000 個に指定します。
マルチクラス クロス エントロピー損失を追跡してモデルの性能を測定します。新しい各観測値のマルチクラス クロス エントロピー損失を測定する無名関数を作成し、数値安定性を得るために許容誤差を含めます。名前
CrossEntropyとそれに対応する関数ハンドルを含む構造体配列を作成します。モデルを最初の 10 個の観測値に当てはめて分類損失を計算します。
tolerance = 1e-10; crossentropy = @(z,zfit,w,cost)-log(max(zfit(z),tolerance)); ce = struct("CrossEntropy",crossentropy); Mdl = incrementalClassificationNaiveBayes('ClassNames',unique(Y),'MetricsWarmupPeriod',1000, ... 'MetricsWindowSize',2000,'Metrics',ce); initobs = 10; Mdl = fit(Mdl,X(1:initobs,:),Y(1:initobs));
Mdl はインクリメンタル学習用に構成された incrementalClassificationNaiveBayes モデル オブジェクトです。
インクリメンタル学習を実行します。各反復で次を行います。
100 個の観測値のチャンクを処理して、データ ストリームをシミュレートします。
updateMetricsを呼び出して、データの入力チャンクの累積メトリクスとウィンドウ メトリクスを計算します。前のインクリメンタル モデルを、前のメトリクスを上書きするように当てはめた新しいモデルで上書きします。lossを呼び出して、データの入力チャンクのクロス エントロピーを計算します。累積メトリクスおよびウィンドウ メトリクスでは、カスタム損失が各観測値の損失を返す必要がありますが、lossではチャンク全体での損失が必要です。チャンク内の損失の平均を計算します。fitを呼び出して、データの入力チャンクにインクリメンタル モデルを当てはめます。累積、ウィンドウ、およびチャンクのメトリクスを保存して、インクリメンタル学習中にそれらがどのように進化するかを確認します。
% Preallocation numObsPerChunk = 100; nchunk = floor((n - initobs)/numObsPerChunk); tanloss = array2table(zeros(nchunk,3),'VariableNames',["Cumulative" "Window" "Chunk"]); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1 + initobs); iend = min(n,numObsPerChunk*j + initobs); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(idx,:),Y(idx)); tanloss{j,1:2} = Mdl.Metrics{"CrossEntropy",:}; tanloss{j,3} = loss(Mdl,X(idx,:),Y(idx),'LossFun',@(z,zfit,w,cost)mean(crossentropy(z,zfit,w,cost))); Mdl = fit(Mdl,X(idx,:),Y(idx)); end
Mdl は、ストリーム内のすべてのデータで学習させた incrementalClassificationNaiveBayes モデル オブジェクトです。インクリメンタル学習中およびモデルがウォームアップされた後、updateMetrics は入力観測値でのモデルの性能をチェックし、関数 fit はモデルをその観測値に当てはめます。
パフォーマンス メトリクスをプロットして、インクリメンタル学習中にそれらがどのように進化するかを確認します。
figure h = plot(tanloss.Variables); xlim([0 nchunk]) ylabel('Cross Entropy') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'r-.') xlabel('Iteration') legend(h,tanloss.Properties.VariableNames)

プロットは次のことを示しています。
updateMetricsは、パフォーマンス メトリクスをメトリクスのウォームアップ期間後にのみ計算します。updateMetricsは、累積メトリクスを各反復中に計算します。updateMetricsは、ウィンドウ メトリクスを 2000 個の観測値 (20 回の反復) の処理後に計算します。Mdlがインクリメンタル学習の初めから観測値を予測するように構成されているため、lossはデータの入力チャンクごとにクロス エントロピーを計算可能です。
入力引数
名前と値の引数
出力引数
詳細
"分類損失" 関数は分類モデルの予測誤差を評価します。複数のモデルで同じタイプの損失を比較した場合、損失が低い方が予測モデルとして優れていることになります。
以下のシナリオを考えます。
L は加重平均分類損失です。
n は標本サイズです。
バイナリ分類は以下です。
yj は観測されたクラス ラベルです。陰性クラスを示す -1 または陽性クラスを示す 1 (あるいは、
ClassNamesプロパティの最初のクラスを示す -1 または 2 番目のクラスを示す 1) を使用して符号化されます。f(Xj) は予測子データ X の観測値 (行) j に対する陽性クラスの分類スコアです。
mj = yjf(Xj) は、yj に対応するクラスに観測値 j を分類する分類スコアです。正の値の mj は正しい分類を示しており、平均損失に対する寄与は大きくありません。負の値の mj は正しくない分類を示しており、平均損失に大きく寄与します。
マルチクラス分類 (つまり、K ≥ 3) をサポートするアルゴリズムの場合、次のようになります。
yj* は、K - 1 個の 0 と、観測された真のクラス yj に対応する位置の 1 から構成されるベクトルです。たとえば、2 番目の観測値の真のクラスが 3 番目のクラスであり K = 4 の場合、y2* = [
0 0 1 0]′ になります。クラスの順序は入力モデルのClassNamesプロパティ内の順序に対応します。f(Xj) は予測子データ X の観測値 j に対するクラス スコアのベクトルで、長さは K です。スコアの順序は入力モデルの
ClassNamesプロパティ内のクラスの順序に対応します。mj = yj*′f(Xj).したがって mj は、観測された真のクラスについてモデルが予測するスカラー分類スコアです。
観測値 j の重みは wj です。観測値の重みは、その合計が
Priorプロパティに格納された対応するクラスの事前確率になるように正規化されます。そのため、次のようになります。
この状況では、名前と値の引数 LossFun を使用して指定できる、サポートされる損失関数は次の表のようになります。
| 損失関数 | LossFun の値 | 式 |
|---|---|---|
| 二項分布からの逸脱度 | "binodeviance" | |
| 観測誤分類コスト | "classifcost" | ここで、 はスコアが最大のクラスに対応するクラス ラベル、 は真のクラスが yj である場合に観測値をクラス に分類するユーザー指定のコストです。 |
| 10 進数の誤分類率 | "classiferror" | ここで、I{·} はインジケーター関数です。 |
| クロスエントロピー損失 | "crossentropy" |
加重クロスエントロピー損失は次となります。 ここで重み は、合計が 1 ではなく n になるように正規化されます。 |
| 指数損失 | "exponential" | |
| ヒンジ損失 | "hinge" | |
| ロジスティック損失 | "logit" | |
| 最小予測誤分類コスト | "mincost" |
重み付きの最小予測分類コストは、次の手順を観測値 j = 1、...、n について使用することにより計算されます。
最小予測誤分類コスト損失の加重平均は次となります。 |
| 二次損失 | "quadratic" |
既定のコスト行列 (正しい分類の場合の要素値は 0、誤った分類の場合の要素値は 1) を使用する場合、"classifcost"、"classiferror"、および "mincost" の損失の値は同じです。既定以外のコスト行列をもつモデルでは、ほとんどの場合は "classifcost" の損失と "mincost" の損失が等価になります。これらの損失が異なる値になる可能性があるのは、最大の事後確率をもつクラスへの予測と最小の予測コストをもつクラスへの予測が異なる場合です。"mincost" は分類スコアが事後確率の場合にしか適さないことに注意してください。
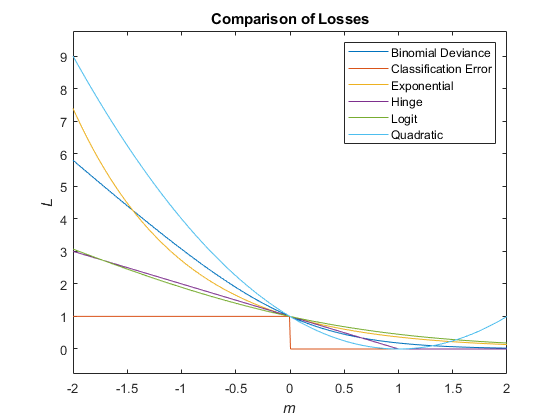
次の図では、1 つの観測値のスコア m に対する損失関数 ("classifcost"、"crossentropy"、および "mincost" を除く) を比較しています。いくつかの関数は、点 (0,1) を通過するように正規化されています。
アルゴリズム
バージョン履歴
R2021a で導入