updateMetricsAndFit
単純ベイズ インクリメンタル学習分類モデルの新しいデータに基づくパフォーマンス メトリクスの更新とモデルの学習
説明
ストリーミング データが与えられると、updateMetricsAndFit は、最初に、入力データの updateMetrics を呼び出して、インクリメンタル学習用の構成済みの単純ベイズ分類モデル (incrementalClassificationNaiveBayes オブジェクト) のパフォーマンスを評価します。次に、updateMetricsAndFit は、fit を呼び出して、モデルをそのデータに当てはめます。言い換えると、updateMetricsAndFit は "逐次予測評価" を実行します。データの各入力チャンクをテスト セットとして扱い、累積的に測定されたパフォーマンス メトリクスと指定したウィンドウにおけるパフォーマンス メトリクスを追跡します[1]。
updateMetricsAndFit は、モデルのパフォーマンス メトリクスを更新し、データの各チャンクでモデルに学習させる簡単な方法を提供します。また、updateMetrics を呼び出してから fit を呼び出して、個別に操作を実行することもできます。これにより柔軟性を高めることができます (たとえば、データのチャンクでのパフォーマンスに基づいて、モデルに学習させる必要があるかどうかを決定できます)。
Mdl = updateMetricsAndFit(Mdl,X,Y)Mdl を返します。これは、インクリメンタル学習用の入力単純ベイズ分類モデル Mdl であり、次の変更が行われます。
updateMetricsAndFitは、入力予測子と応答データ (それぞれXとY) のモデル パフォーマンスを測定します。入力モデルが "ウォーム" (Mdl.IsWarmがtrue) の場合、updateMetricsAndFitは以前に計算されたメトリクスを上書きし、Metricsプロパティに新しい値を保存します。それ以外の場合、updateMetricsAndFitは代わりにMetricsにNaN値を保存します。updateMetricsAndFitは、変更されたモデルを入力データに当てはめます。与えられたクラスに応じて各予測子変数の条件付き事後平均と標準偏差を更新し、新しい推定値を他の構成と共に出力モデルMdlに保存します。
例
incrementalClassificationNaiveBayes を呼び出してインクリメンタル学習用の単純ベイズ分類モデルを作成し、データ内の予測される最大クラス数を 5 と指定します。
Mdl = incrementalClassificationNaiveBayes('MaxNumClasses',5)Mdl =
incrementalClassificationNaiveBayes
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'none'
DistributionNames: 'normal'
DistributionParameters: {}
Properties, Methods
Mdl は incrementalClassificationNaiveBayes モデル オブジェクトです。そのプロパティはすべて読み取り専用です。
Mdl は、他の演算の実行に使用する前に、データに当てはめなければなりません。
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
各反復で次のアクションを実行してインクリメンタル学習を実装します。
50 個の観測値のチャンクを処理して、データ ストリームをシミュレートします。
前のインクリメンタル モデルを、入力観測値に当てはめた新しいモデルで上書きします。
1 番目のクラス内の 1 番目の予測子の条件付き平均 、累積メトリクス、およびウィンドウ メトリクスを保存し、インクリメンタル学習中にそれらがどのように進化するかを確認。
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); mc = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); mu11 = zeros(nchunk,1); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetricsAndFit(Mdl,X(idx,:),Y(idx)); mc{j,:} = Mdl.Metrics{"MinimalCost",:}; mu11(j + 1) = Mdl.DistributionParameters{1,1}(1); end
Mdl は、ストリーム内のすべてのデータで学習させた incrementalClassificationNaiveBayes モデル オブジェクトになります。インクリメンタル学習中およびモデルがウォームアップされた後、updateMetricsAndFit は入力観測値でモデルの性能をチェックし、モデルをその観測値に当てはめます。
パフォーマンス メトリクスと が学習中にどのように進化するかを確認するには、それらを別々のタイルにプロットします。
t = tiledlayout(2,1); nexttile plot(mu11) ylabel('\mu_{11}') xlim([0 nchunk]) nexttile h = plot(mc.Variables); xlim([0 nchunk]) ylabel('Minimal Cost') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'r-.') legend(h,mc.Properties.VariableNames) xlabel(t,'Iteration')
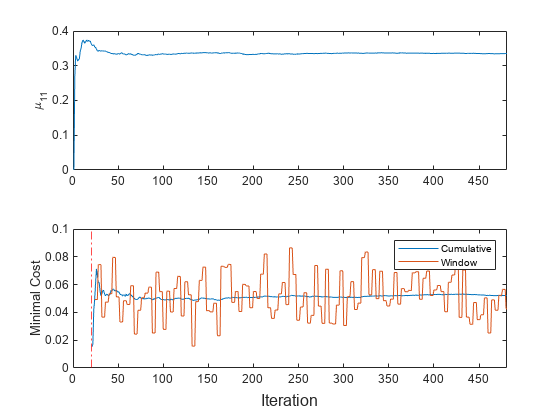
このプロットは、updateMetricsAndFit が次のアクションを実行することを示しています。
をインクリメンタル学習のすべての反復で当てはめます。
パフォーマンス メトリクスをメトリクスのウォームアップ期間後にのみ計算します。
累積メトリクスを各反復中に計算します。
ウィンドウ メトリクスを 200 個の観測値 (4 回の反復) の処理後に計算します。
fitcnb を使用して単純ベイズ分類モデルに学習させ、それをインクリメンタル学習器に変換し、その性能をストリーミング データで追跡してデータに当てはめる操作を 1 回の呼び出しで行います。観測値の重みを指定します。
データの読み込みと前処理
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。
load humanactivity rng(1) % For reproducibility n = numel(actid); idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
静止している被験者 (Y <= 2) のデータが、移動している被験者のデータの倍の品質であると仮定します。静止している被験者の観測値に重み 2 を割り当て、移動している被験者の観測値に重み 1 を割り当てる重み変数を作成します。
W = ones(n,1) + (Y <= 2);
単純ベイズ分類モデルの学習
単純ベイズ分類モデルをデータの半分の無作為標本に当てはめます。
idxtt = randsample([true false],n,true);
TTMdl = fitcnb(X(idxtt,:),Y(idxtt),'Weights',W(idxtt))TTMdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [1 2 3 4 5]
ScoreTransform: 'none'
NumObservations: 12053
DistributionNames: {1×60 cell}
DistributionParameters: {5×60 cell}
Properties, Methods
TTMdl は従来式の学習済み単純ベイズ分類モデルを表す ClassificationNaiveBayes モデル オブジェクトです。
学習済みモデルの変換
従来式の学習済み分類モデルをインクリメンタル学習用の単純ベイズ分類モデルに変換します。インクリメンタル学習中に誤分類誤差率を追跡するように指定します。
IncrementalMdl = incrementalLearner(TTMdl,'Metrics',"classiferror")
IncrementalMdl =
incrementalClassificationNaiveBayes
IsWarm: 1
Metrics: [2×2 table]
ClassNames: [1 2 3 4 5]
ScoreTransform: 'none'
DistributionNames: {1×60 cell}
DistributionParameters: {5×60 cell}
Properties, Methods
IncrementalMdl は incrementalClassificationNaiveBayes モデルです。クラス名が IncrementalMdl.ClassNames で指定されているため、インクリメンタル学習で見つかるラベルは IncrementalMdl.ClassNames のいずれかでなければなりません。
パフォーマンス メトリクスの追跡とモデルの当てはめ
関数 updateMetricsAndFit を使用して、残りのデータに対してインクリメンタル学習を実行します。各反復で次を行います。
50 個の観測値を一度に処理して、データ ストリームをシミュレートします。
updateMetricsAndFitを呼び出し、観測値の入力チャンクを所与として、モデルのパフォーマンス メトリクスの累積とウィンドウを更新し、モデルをデータに当てはめます。前のインクリメンタル モデルを新しいモデルで上書きします。観測値の重みを指定します。誤分類誤差率を保存します。
% Preallocation idxil = ~idxtt; nil = sum(idxil); numObsPerChunk = 50; nchunk = floor(nil/numObsPerChunk); mc = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); Xil = X(idxil,:); Yil = Y(idxil); Wil = W(idxil); % Incremental fitting for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = updateMetricsAndFit(IncrementalMdl,Xil(idx,:),Yil(idx),... 'Weights',Wil(idx)); mc{j,:} = IncrementalMdl.Metrics{"ClassificationError",:}; end
IncrementalMdl は、ストリーム内のすべてのデータで学習させた incrementalClassificationNaiveBayes モデル オブジェクトになります。
誤分類誤差率のトレース プロットを作成します。
h = plot(mc.Variables); xlim([0 nchunk]) ylabel('Classification Error') legend(h,mc.Properties.VariableNames) xlabel('Iteration')

累積の損失は最初に変動した後に 0.05 近辺で安定しますが、ウィンドウの損失には学習全体を通じて急な変動があります。