このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fitcdiscr
判別分析分類器の当てはめ
構文
説明
Mdl = fitcdiscr(Tbl,ResponseVarName)Tbl に含まれている入力変数 (予測子、特徴量または属性とも呼ばれます) と ResponseVarName に含まれている出力 (応答またはラベル) に基づいて当てはめた判別分析モデルを返します。
Mdl = fitcdiscr(___,Name=Value)
[ は、名前と値の引数 Mdl,AggregateOptimizationResults] = fitcdiscr(___)OptimizeHyperparameters と HyperparameterOptimizationOptions が指定されている場合に、ハイパーパラメーターの最適化の結果が格納された AggregateOptimizationResults も返します。HyperparameterOptimizationOptions の ConstraintType オプションと ConstraintBounds オプションも指定する必要があります。この構文を使用すると、交差検証損失ではなくコンパクトなモデル サイズに基づいて最適化したり、オプションは同じでも制約範囲は異なる複数の一連の最適化問題を実行したりできます。
メモ
入力変数が tall 配列の場合のサポートされている構文のリストについては、tall 配列を参照してください。
例
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheririsデータ セット全体を使用して、判別分析モデルに学習をさせます。
Mdl = fitcdiscr(meas,species)
Mdl =
ClassificationDiscriminant
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
DiscrimType: 'linear'
Mu: [3×4 double]
Coeffs: [3×3 struct]
Properties, Methods
Mdl は ClassificationDiscriminant モデルです。プロパティにアクセスするには、ドット表記を使用します。たとえば、各予測子のグループ平均を表示します。
Mdl.Mu
ans = 3×4
5.0060 3.4280 1.4620 0.2460
5.9360 2.7700 4.2600 1.3260
6.5880 2.9740 5.5520 2.0260
新しい観測値のラベルを予測するには、Mdl と予測子データを predict に渡します。
この例では、fitcdiscr を使用して自動的にハイパーパラメーターを最適化する方法を示します。この例では、フィッシャーのアヤメのデータを使用します。
データを読み込みます。
load fisheriris自動的なハイパーパラメーター最適化を使用して、5 分割交差検証損失を最小化するハイパーパラメーターを求めます。
再現性を得るために、乱数シードを設定し、'expected-improvement-plus' の獲得関数を使用します。
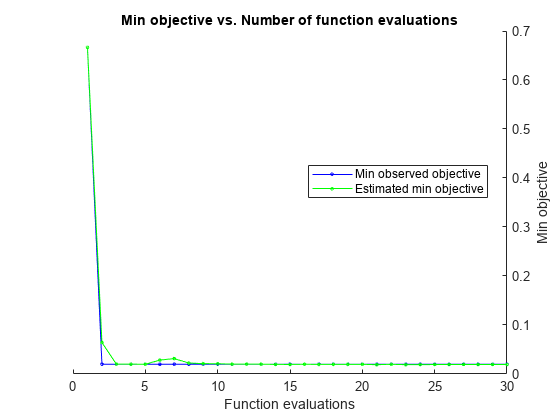
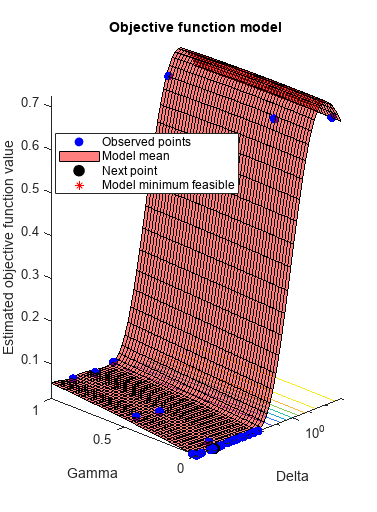
rng(1) Mdl = fitcdiscr(meas,species,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',... struct('AcquisitionFunctionName','expected-improvement-plus'))
|=====================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Delta | Gamma |
| | result | | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 1 | Best | 0.66667 | 0.46105 | 0.66667 | 0.66667 | 13.261 | 0.25218 |
| 2 | Best | 0.02 | 0.21257 | 0.02 | 0.064227 | 2.7404e-05 | 0.073264 |
| 3 | Accept | 0.04 | 0.14377 | 0.02 | 0.020084 | 3.2455e-06 | 0.46974 |
| 4 | Accept | 0.66667 | 0.069856 | 0.02 | 0.020118 | 14.879 | 0.98622 |
| 5 | Accept | 0.046667 | 0.073962 | 0.02 | 0.019907 | 0.00031449 | 0.97362 |
| 6 | Accept | 0.04 | 0.044825 | 0.02 | 0.028438 | 4.5092e-05 | 0.43616 |
| 7 | Accept | 0.046667 | 0.092683 | 0.02 | 0.031424 | 2.0973e-05 | 0.9942 |
| 8 | Accept | 0.02 | 0.063527 | 0.02 | 0.022424 | 1.0554e-06 | 0.0024286 |
| 9 | Accept | 0.02 | 0.041456 | 0.02 | 0.021105 | 1.1232e-06 | 0.00014039 |
| 10 | Accept | 0.02 | 0.057914 | 0.02 | 0.020948 | 0.00011837 | 0.0032994 |
| 11 | Accept | 0.02 | 0.058217 | 0.02 | 0.020172 | 1.0292e-06 | 0.027725 |
| 12 | Accept | 0.02 | 0.041674 | 0.02 | 0.020105 | 9.7792e-05 | 0.0022817 |
| 13 | Accept | 0.02 | 0.038937 | 0.02 | 0.020038 | 0.00036014 | 0.0015136 |
| 14 | Accept | 0.02 | 0.042295 | 0.02 | 0.019597 | 0.00021059 | 0.0044789 |
| 15 | Accept | 0.02 | 0.0524 | 0.02 | 0.019461 | 1.1911e-05 | 0.0010135 |
| 16 | Accept | 0.02 | 0.070734 | 0.02 | 0.01993 | 0.0017896 | 0.00071115 |
| 17 | Accept | 0.02 | 0.10436 | 0.02 | 0.019551 | 0.00073745 | 0.0066899 |
| 18 | Accept | 0.02 | 0.069354 | 0.02 | 0.019776 | 0.00079304 | 0.00011509 |
| 19 | Accept | 0.02 | 0.058545 | 0.02 | 0.019678 | 0.007292 | 0.0007911 |
| 20 | Accept | 0.046667 | 0.073117 | 0.02 | 0.019785 | 0.0074408 | 0.99945 |
|=====================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Delta | Gamma |
| | result | | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 21 | Accept | 0.02 | 0.044721 | 0.02 | 0.019043 | 0.0036004 | 0.0024547 |
| 22 | Accept | 0.02 | 0.076834 | 0.02 | 0.019755 | 2.5238e-05 | 0.0015542 |
| 23 | Accept | 0.02 | 0.051838 | 0.02 | 0.0191 | 1.5478e-05 | 0.0026899 |
| 24 | Accept | 0.02 | 0.051115 | 0.02 | 0.019081 | 0.0040557 | 0.00046815 |
| 25 | Accept | 0.02 | 0.043246 | 0.02 | 0.019333 | 2.959e-05 | 0.0011358 |
| 26 | Accept | 0.02 | 0.056265 | 0.02 | 0.019369 | 2.3111e-06 | 0.0029205 |
| 27 | Accept | 0.02 | 0.066812 | 0.02 | 0.019455 | 3.8898e-05 | 0.0011665 |
| 28 | Accept | 0.02 | 0.035096 | 0.02 | 0.019449 | 0.0035925 | 0.0020278 |
| 29 | Accept | 0.66667 | 0.048139 | 0.02 | 0.019479 | 998.93 | 0.064276 |
| 30 | Accept | 0.02 | 0.075214 | 0.02 | 0.01947 | 8.1557e-06 | 0.0008004 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 21.5343 seconds
Total objective function evaluation time: 2.4205
Best observed feasible point:
Delta Gamma
__________ ________
2.7404e-05 0.073264
Observed objective function value = 0.02
Estimated objective function value = 0.022693
Function evaluation time = 0.21257
Best estimated feasible point (according to models):
Delta Gamma
__________ _________
2.5238e-05 0.0015542
Estimated objective function value = 0.01947
Estimated function evaluation time = 0.055284
Mdl =
ClassificationDiscriminant
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
DiscrimType: 'linear'
Mu: [3×4 double]
Coeffs: [3×3 struct]
Properties, Methods
この当てはめでは、既定の 5 分割交差検証について損失が約 2% になりました。
この例では、tall 配列を使用する判別分析モデルのハイパーパラメーターを自動的に最適化する方法を示します。標本データ セット airlinesmall.csv は、飛行機のフライト データについての表形式ファイルが含まれている大規模なデータ セットです。この例では、データが含まれている tall table を作成して、最適化手順を実行するために使用します。
tall 配列に対する計算を実行する場合、MATLAB® は並列プール (Parallel Computing Toolbox™ がある場合は既定) またはローカルの MATLAB セッションを使用します。Parallel Computing Toolbox がある場合でもローカルの MATLAB セッションを使用して例を実行するには、関数mapreducerを使用してグローバルな実行環境を変更できます。
データがあるフォルダーの場所を参照するデータストアを作成します。処理する変数のサブセットを選択します。datastore で NaN 値に置き換えるため、NA 値を欠損データとして扱います。データストア内のデータを含む tall table を作成します。
ds = datastore("airlinesmall.csv"); ds.SelectedVariableNames = ["Month","DayofMonth","DayOfWeek", ... "DepTime","ArrDelay","Distance","DepDelay"]; ds.TreatAsMissing = "NA"; tt = tall(ds) % Tall table
Starting parallel pool (parpool) using the 'Processes' profile ...
07-Dec-2023 09:05:49: Job Queued. Waiting for parallel pool job with ID 1 to start ...
07-Dec-2023 09:06:50: Job Queued. Waiting for parallel pool job with ID 1 to start ...
Connected to parallel pool with 6 workers.
tt =
M×7 tall table
Month DayofMonth DayOfWeek DepTime ArrDelay Distance DepDelay
_____ __________ _________ _______ ________ ________ ________
10 21 3 642 8 308 12
10 26 1 1021 8 296 1
10 23 5 2055 21 480 20
10 23 5 1332 13 296 12
10 22 4 629 4 373 -1
10 28 3 1446 59 308 63
10 8 4 928 3 447 -2
10 10 6 859 11 954 -1
: : : : : : :
: : : : : : :
フライトが遅れた場合に真になる論理変数を定義することにより、10 分以上遅れたフライトを判別します。この変数にクラス ラベルを含めます。この変数のプレビューには、はじめの数行が含まれています。
Y = tt.DepDelay > 10 % Class labelsY = M×1 tall logical array 1 0 1 1 0 1 0 0 : :
予測子データの tall 配列を作成します。
X = tt{:,1:end-1} % Predictor dataX =
M×6 tall double matrix
10 21 3 642 8 308
10 26 1 1021 8 296
10 23 5 2055 21 480
10 23 5 1332 13 296
10 22 4 629 4 373
10 28 3 1446 59 308
10 8 4 928 3 447
10 10 6 859 11 954
: : : : : :
: : : : : :
欠損データが含まれている X および Y の行を削除します。
R = rmmissing([X Y]); % Data with missing entries removed
X = R(:,1:end-1);
Y = R(:,end); 予測子変数を標準化します。
Z = zscore(X);
名前と値の引数 OptimizeHyperparameters を使用して、自動的にハイパーパラメーターを最適化します。tall 配列を使用するときは、"auto" または "all" を指定しても、最適化できるハイパーパラメーターは DiscrimType のみになることに注意してください。ホールドアウト交差検証損失が最小になる最適な DiscrimType の値を求めます。再現性を得るため、"expected-improvement-plus" の獲得関数を使用し、rng と tallrng により乱数発生器のシードを設定します。tall 配列の場合、ワーカーの個数と実行環境によって結果が異なる可能性があります。詳細については、コードの実行場所の制御を参照してください。
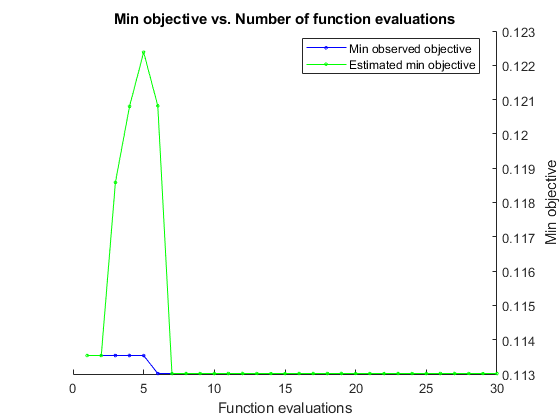
rng("default") tallrng("default") [Mdl,FitInfo,HyperparameterOptimizationResults] = fitcdiscr(Z,Y, ... "OptimizeHyperparameters","auto", ... "HyperparameterOptimizationOptions",struct("Holdout",0.3, ... "AcquisitionFunctionName","expected-improvement-plus"))
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 2: Completed in 7.3 sec
- Pass 2 of 2: Completed in 3.8 sec
Evaluation completed in 19 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 4 sec
Evaluation completed in 4.3 sec
|======================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | DiscrimType |
| | result | | runtime | (observed) | (estim.) | |
|======================================================================================|
| 1 | Best | 0.11354 | 27.449 | 0.11354 | 0.11354 | quadratic |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.3 sec
Evaluation completed in 2.5 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1 sec
Evaluation completed in 1.2 sec
| 2 | Accept | 0.11354 | 5.4566 | 0.11354 | 0.11354 | pseudoQuadra |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.96 sec
Evaluation completed in 2.2 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.89 sec
Evaluation completed in 1.1 sec
| 3 | Accept | 0.12869 | 4.8549 | 0.11354 | 0.11859 | pseudoLinear |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.99 sec
Evaluation completed in 1.9 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.89 sec
Evaluation completed in 1.1 sec
| 4 | Accept | 0.12745 | 4.2867 | 0.11354 | 0.1208 | diagLinear |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.98 sec
Evaluation completed in 2 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.84 sec
Evaluation completed in 1 sec
| 5 | Accept | 0.12869 | 4.6497 | 0.11354 | 0.12238 | linear |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1 sec
Evaluation completed in 1.7 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.89 sec
Evaluation completed in 1.1 sec
| 6 | Best | 0.11301 | 4.0594 | 0.11301 | 0.12082 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.96 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.82 sec
Evaluation completed in 1 sec
| 7 | Accept | 0.11301 | 4.0419 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.85 sec
Evaluation completed in 1 sec
| 8 | Accept | 0.11301 | 4.0382 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.97 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.81 sec
Evaluation completed in 1 sec
| 9 | Accept | 0.11301 | 3.9186 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1 sec
Evaluation completed in 1.9 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.84 sec
Evaluation completed in 1 sec
| 10 | Accept | 0.11301 | 4.0947 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1 sec
Evaluation completed in 1.9 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.88 sec
Evaluation completed in 1.1 sec
| 11 | Accept | 0.11301 | 4.3088 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.94 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.8 sec
Evaluation completed in 1 sec
| 12 | Accept | 0.11301 | 3.9644 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.86 sec
Evaluation completed in 1.1 sec
| 13 | Accept | 0.11301 | 4.0673 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.93 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.94 sec
Evaluation completed in 1.2 sec
| 14 | Accept | 0.11301 | 4.1285 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.2 sec
Evaluation completed in 2 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.93 sec
Evaluation completed in 1.1 sec
| 15 | Accept | 0.11301 | 4.4217 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.98 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.89 sec
Evaluation completed in 1.1 sec
| 16 | Accept | 0.11301 | 4.0631 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.99 sec
Evaluation completed in 1.7 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.86 sec
Evaluation completed in 1.1 sec
| 17 | Accept | 0.11301 | 4.0227 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1 sec
Evaluation completed in 1.9 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.88 sec
Evaluation completed in 1.1 sec
| 18 | Accept | 0.11354 | 4.3391 | 0.11301 | 0.11301 | pseudoQuadra |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.98 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.85 sec
Evaluation completed in 1 sec
| 19 | Accept | 0.11301 | 4.139 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.97 sec
Evaluation completed in 1.9 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.91 sec
Evaluation completed in 1.1 sec
| 20 | Accept | 0.11301 | 4.2078 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1 sec
Evaluation completed in 1.9 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.86 sec
Evaluation completed in 1.1 sec
|======================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | DiscrimType |
| | result | | runtime | (observed) | (estim.) | |
|======================================================================================|
| 21 | Accept | 0.11301 | 4.1129 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.1 sec
Evaluation completed in 1.9 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.86 sec
Evaluation completed in 1.1 sec
| 22 | Accept | 0.11354 | 4.2473 | 0.11301 | 0.11301 | quadratic |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.98 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.87 sec
Evaluation completed in 1.1 sec
| 23 | Accept | 0.11301 | 4.0342 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.1 sec
Evaluation completed in 1.9 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.88 sec
Evaluation completed in 1.1 sec
| 24 | Accept | 0.11354 | 4.173 | 0.11301 | 0.11301 | pseudoQuadra |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.99 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.82 sec
Evaluation completed in 1.1 sec
| 25 | Accept | 0.11301 | 3.9707 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1 sec
Evaluation completed in 1.7 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.98 sec
Evaluation completed in 1.2 sec
| 26 | Accept | 0.11354 | 4.1135 | 0.11301 | 0.11301 | quadratic |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.1 sec
Evaluation completed in 2 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.92 sec
Evaluation completed in 1.1 sec
| 27 | Accept | 0.11301 | 4.2567 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.94 sec
Evaluation completed in 1.5 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.88 sec
Evaluation completed in 1.1 sec
| 28 | Accept | 0.11301 | 3.7988 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.97 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.88 sec
Evaluation completed in 1.1 sec
| 29 | Accept | 0.11301 | 3.9926 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.95 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.85 sec
Evaluation completed in 1 sec
| 30 | Accept | 0.11301 | 3.9793 | 0.11301 | 0.11301 | diagQuadrati |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 180.1662 seconds
Total objective function evaluation time: 149.1907
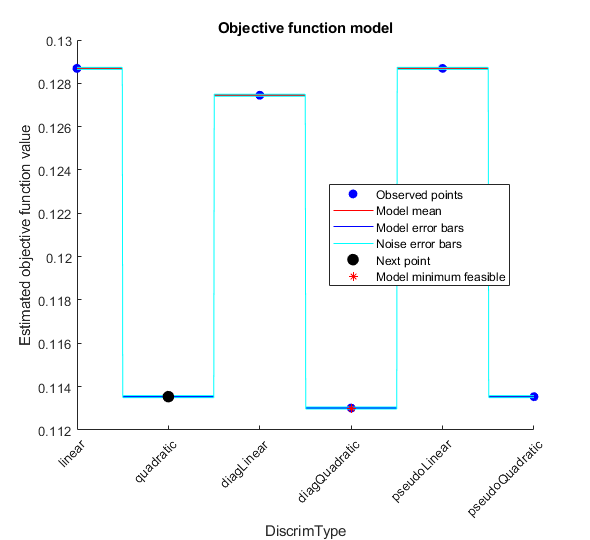
Best observed feasible point:
DiscrimType
_____________
diagQuadratic
Observed objective function value = 0.11301
Estimated objective function value = 0.11301
Function evaluation time = 4.0594
Best estimated feasible point (according to models):
DiscrimType
_____________
diagQuadratic
Estimated objective function value = 0.11301
Estimated function evaluation time = 4.1702
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.8 sec
Evaluation completed in 1.6 sec
Mdl =
CompactClassificationDiscriminant
PredictorNames: {'x1' 'x2' 'x3' 'x4' 'x5' 'x6'}
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [0 1]
ScoreTransform: 'none'
DiscrimType: 'diagQuadratic'
Mu: [2×6 double]
Coeffs: [2×2 struct]
Properties, Methods
FitInfo = struct with no fields.
HyperparameterOptimizationResults =
BayesianOptimization with properties:
ObjectiveFcn: @createObjFcn/tallObjFcn
VariableDescriptions: [1×1 optimizableVariable]
Options: [1×1 struct]
MinObjective: 0.1130
XAtMinObjective: [1×1 table]
MinEstimatedObjective: 0.1130
XAtMinEstimatedObjective: [1×1 table]
NumObjectiveEvaluations: 30
TotalElapsedTime: 180.1662
NextPoint: [1×1 table]
XTrace: [30×1 table]
ObjectiveTrace: [30×1 double]
ConstraintsTrace: []
UserDataTrace: {30×1 cell}
ObjectiveEvaluationTimeTrace: [30×1 double]
IterationTimeTrace: [30×1 double]
ErrorTrace: [30×1 double]
FeasibilityTrace: [30×1 logical]
FeasibilityProbabilityTrace: [30×1 double]
IndexOfMinimumTrace: [30×1 double]
ObjectiveMinimumTrace: [30×1 double]
EstimatedObjectiveMinimumTrace: [30×1 double]
入力引数
名前と値の引数
出力引数
詳細
ヒント
モデルに学習をさせた後で、新しいデータについてラベルを予測する C/C++ コードを生成できます。C/C++ コードの生成には MATLAB Coder™ が必要です。詳細については、統計と機械学習の関数のコード生成の紹介を参照してください。
アルゴリズム
名前と値の引数
Cost、Prior、およびWeightsを指定すると、出力モデル オブジェクトにCost、Prior、およびWの各プロパティの指定値がそれぞれ格納されます。Costプロパティには、ユーザー指定のコスト行列がそのまま格納されます。PriorプロパティとWプロパティには、正規化後の事前確率と観測値の重みがそれぞれ格納されます。詳細については、誤分類コスト行列、事前確率、および観測値の重みを参照してください。Costプロパティは予測に使用されますが、学習には使用されません。したがって、Costは読み取り専用ではなく、学習済みモデルの作成後にドット表記を使用してプロパティの値を変更できます。
代替機能
関数
関数 classify も判別分析を実行します。通常、classify のほうが、以下の点で使い方が複雑な関数です。
classifyでは、新しい予測を実行するたびに、分類器を当てはめる必要があります。classifyは、交差検証もハイパーパラメーターの最適化も実行しません。classifyでは、事前確率を変更するときに、分類器を当てはめる必要があります。