predict
判別分析分類器の使用によるラベルの予測
説明
例
フィッシャーのアヤメのデータ セットを読み込みます。標本サイズを調べます。
load fisheriris
N = size(meas,1);データを学習セットとテスト セットに分割します。データの 10% をテスト用にホールドアウトします。
rng(1); % For reproducibility cvp = cvpartition(N,'Holdout',0.1); idxTrn = training(cvp); % Training set indices idxTest = test(cvp); % Test set indices
学習データを table に格納します。
tblTrn = array2table(meas(idxTrn,:)); tblTrn.Y = species(idxTrn);
学習セットと既定のオプションを使用して、判別分析モデルに学習をさせます。
Mdl = fitcdiscr(tblTrn,'Y');テスト セットについてラベルを予測します。Mdl の学習にはデータの table を使用しましたが、ラベルの予測には行列を使用できます。
labels = predict(Mdl,meas(idxTest,:));
テスト セットの混同行列を作成します。
confusionchart(species(idxTest),labels)
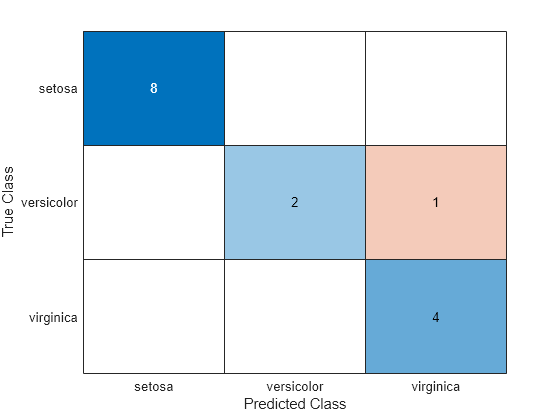
Mdl は、テスト セット内の 1 つの versicolor 種のアヤメを virginica として誤分類します。
フィッシャーのアヤメのデータ セットを読み込みます。花弁の長さと幅のみによる学習を考えます。
load fisheriris
X = meas(:,3:4);データ セット全体を使用して、2 次判別分析モデルに学習をさせます。
Mdl = fitcdiscr(X,species,'DiscrimType','quadratic');
観測された予測子領域の値のグリッドを定義します。グリッド内の各インスタンスの事後確率を予測します。
xMax = max(X); xMin = min(X); d = 0.01; [x1Grid,x2Grid] = meshgrid(xMin(1):d:xMax(1),xMin(2):d:xMax(2)); [~,score] = predict(Mdl,[x1Grid(:),x2Grid(:)]); Mdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
score はクラス事後確率の行列です。各列は Mdl.ClassNames 内のクラスに対応します。たとえば、観測値 j が setosa 種のアヤメである事後確率は score(j,1) です。
各観測値を versicolor 種として分類する事後確率をグリッドにプロットし、学習データをプロットします。
figure; contourf(x1Grid,x2Grid,reshape(score(:,2),size(x1Grid,1),size(x1Grid,2))); h = colorbar; clim([0 1]); colormap jet; hold on gscatter(X(:,1),X(:,2),species,'mcy','.x+'); axis tight title('Posterior Probability of versicolor'); hold off

事後確率領域により決定境界の一部が明らかになります。
入力引数
出力引数
詳細
代替機能
Simulink ブロック
Simulink® に判別分析分類モデルの予測を統合するには、Statistics and Machine Learning Toolbox™ ライブラリにある ClassificationDiscriminant Predict ブロックを使用するか、MATLAB® Function ブロックを関数 predict と共に使用します。例については、ClassificationDiscriminant Predict ブロックの使用によるクラス ラベルの予測とMATLAB Function ブロックの使用によるクラス ラベルの予測を参照してください。
使用するアプローチを判断する際は、以下を考慮してください。
Statistics and Machine Learning Toolbox ライブラリ ブロックを使用する場合、固定小数点ツール (Fixed-Point Designer)を使用して浮動小数点モデルを固定小数点に変換できます。
MATLAB Function ブロックを関数
predictと共に使用する場合は、可変サイズの配列に対するサポートを有効にしなければなりません。MATLAB Function ブロックを使用する場合、予測の前処理や後処理のために、同じ MATLAB Function ブロック内で MATLAB 関数を使用することができます。
拡張機能
バージョン履歴
R2011b で導入