compareHoldout
新しいデータを使用して 2 つの分類モデルの精度を比較
構文
説明
compareHoldout は、2 つの分類モデルの精度を統計的に評価します。この関数では、予測したラベルを真のラベルに対して比較してから、誤分類率の違いが統計的に有意であるかどうかを調べます。
複数の分類モデルの精度が異なるかどうかや、あるモデルの性能が別のモデルより優れているかどうかを判断できます。compareHoldout では、漸近検定、厳密条件検定、mid-p 値検定など、いくつかのマクネマー検定のバリエーションを実行できます。コストを考慮する評価については、カイ二乗検定 (Optimization Toolbox™ が必要) や尤度比検定などの検定を行うことができます。
h = compareHoldout(C1,C2,T1,T2,ResponseVarName)C1 および C2 は変数 ResponseVarName に含まれている真のクラス ラベルを予測する精度が等しい」という帰無仮説の検定の判定を返します。対立仮説は「ラベルの精度は等しくない」です。
1 番目の分類モデル C1 では T1 に含まれている予測子データを、2 番目の分類モデル C2 では T2 に含まれている予測子データを使用します。table T1 および T2 には、同じ応答変数を含めなければなりませんが、予測子については異なるセットを含めることができます。既定では、mid-p 値マクネマー検定が精度の比較に使用されます。
h = 1 の場合、帰無仮説は 5% の有意水準で棄却されます。h = 0 の場合、帰無仮説は 5% の水準では棄却されません。
以下のような検定を行うことができます。
同じ予測子データのセットを渡して (
T1=T2)、単純な分類モデルとより複雑なモデルの精度を比較する。異なる可能性がある 2 種類の予測子データのセットを使用して、異なる可能性がある 2 つのモデルの精度を比較する。
さまざまな特徴選択を実行する。たとえば、ある予測子のセットを使用して学習させたモデルの精度と、同じ予測子のサブセットまたは別の予測子のセットを使用して学習させたモデルの精度を比較できます。予測子のセットは自由に選択できます。また、PCA (
pca参照) や逐次特徴選択 (sequentialfs参照) などの特徴選択手法を使用することもできます。
例
2 つの k 最近傍分類器に学習をさせます。一方の分類器では、もう一方で使用した予測子のサブセットを使用します。テスト セットで 2 つのモデルの精度を比較する統計検定を実行します。
carsmall データ セットを読み込みます。
load carsmall2 つの入力データの table を作成します。2 番目の table では予測子 Acceleration を除外します。応答変数として Model_Year を指定します。
T1 = table(Acceleration,Displacement,Horsepower,MPG,Model_Year); T2 = T1(:,2:end);
データを学習セットとテスト セットに分割します。データの 30% をテスト用に確保します。
rng(1) % For reproducibility CVP = cvpartition(Model_Year,'holdout',0.3); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP は、学習セットとテスト セットを指定する交差検証分割オブジェクトです。
T1 と T2 のデータを使用して ClassificationKNN モデルに学習をさせます。
C1 = fitcknn(T1(idxTrain,:),'Model_Year'); C2 = fitcknn(T2(idxTrain,:),'Model_Year');
C1 と C2 は学習済みの ClassificationKNN モデルです。
テスト セットで 2 つのモデルの予測精度が等しいかどうかをテストします。
h = compareHoldout(C1,C2,T1(idxTest,:),T2(idxTest,:),'Model_Year')h = logical
0
h = 0 なので、2 つのモデルの予測精度が等しいという帰無仮説は棄却できません。
異なるアルゴリズムを使用して 2 つの分類モデルを学習させます。テスト セットで 2 つのモデルの誤分類率を比較する統計検定を実行します。
ionosphere データ セットを読み込みます。
load ionosphereデータを学習セットとテスト セットに均等に分割します。
rng(1) % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP は、学習セットとテスト セットを指定する交差検証分割オブジェクトです。
SVM モデルと、バギング分類木が 100 本あるアンサンブルを学習させます。SVM モデルについては、放射基底関数カーネルとヒューリスティック手法を使用してカーネル スケールを決定するように指定します。
C1 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true, ... 'KernelFunction','RBF','KernelScale','auto'); t = templateTree('Reproducible',true); % For reproducibility of random predictor selections C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','Bag', ... 'Learners',t);
C1 は学習済みの ClassificationSVM モデルです。C2 は学習済みの ClassificationBaggedEnsemble モデルです。
2 つのモデルの予測精度が同じであるかどうかを検定します。各モデルについて同じテスト セット予測子データを使用します。
h = compareHoldout(C1,C2,X(idxTest,:),X(idxTest,:),Y(idxTest))
h = logical
0
h = 0 なので、2 つのモデルの予測精度が等しいという帰無仮説は棄却できません。
同じアルゴリズムを使用して 2 つの分類モデルを学習させます。ただし、ハイパーパラメーターを調整してアルゴリズムをより複雑にします。複雑なモデルより単純なモデルの方がテスト データに対する精度が優れているかどうかを評価する統計検定を実行します。
ionosphere データ セットを読み込みます。
load ionosphere;データを学習セットとテスト セットに均等に分割します。
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP は、学習セットとテスト セットを指定する交差検証分割オブジェクトです。
線形カーネル (バイナリ分類の既定) を使用する SVM モデルと放射基底関数カーネルを使用する SVM モデルを学習させます。カーネル スケールには、既定値の 1 を使用します。
C1 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true); C2 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true,... 'KernelFunction','RBF');
C1 と C2 は学習済みの ClassificationSVM モデルです。
単純なモデル (C1) の精度は複雑なモデル (C2) の精度と同程度であるという帰無仮説を検定します。テスト セットのサイズが大きいので、漸近マクネマー検定を実行し、mid-p 値検定 (コストを考慮しない検定の既定) で結果を比較します。p 値と誤分類率を返すように指定します。
Asymp = zeros(4,1); % Preallocation MidP = zeros(4,1); [Asymp(1),Asymp(2),Asymp(3),Asymp(4)] = compareHoldout(C1,C2,... X(idxTest,:),X(idxTest,:),Y(idxTest),'Alternative','greater',... 'Test','asymptotic'); [MidP(1),MidP(2),MidP(3),MidP(4)] = compareHoldout(C1,C2,... X(idxTest,:),X(idxTest,:),Y(idxTest),'Alternative','greater'); table(Asymp,MidP,'RowNames',{'h' 'p' 'e1' 'e2'})
ans=4×2 table
Asymp MidP
__________ __________
h 1 1
p 7.2801e-09 2.7649e-10
e1 0.13714 0.13714
e2 0.33143 0.33143
両方の検定で p 値がゼロに近いので、単純なモデルの精度が複雑なモデルの精度より低いという帰無仮説を棄却するだけの十分な証拠が得られました。どの検定を指定しても、compareHoldout は両方のモデルについて同じタイプの誤分類尺度を返します。
データ セットのクラスの表現が不均衡である場合、または偽陽性のコストと偽陰性のコストが不均衡である場合、コスト行列を分析に含めることにより、2 つの分類モデルの予測性能を統計的に比較できます。
arrhythmia データ セットを読み込みます。データのクラス表現を判別します。
load arrhythmia;
Y = categorical(Y);
tabulate(Y); Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
16 個のクラスがありますが、一部はデータ セットで表現されていません (たとえば、クラス 13)。ほとんどの観測値は不整脈がないものとして分類されています (クラス 1)。このデータ セットは非常に離散的であり、クラスが不均衡です。
不整脈があるすべての観測値 (クラス 2 ~ 15) を 1 つのクラスに結合します。不整脈の状況 (クラス 16) が不明である観測値をデータ セットから削除します。
idx = (Y ~= '16'); Y = Y(idx); X = X(idx,:); Y(Y ~= '1') = 'WithArrhythmia'; Y(Y == '1') = 'NoArrhythmia'; Y = removecats(Y);
データを学習セットとテスト セットに均等に分割します。
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP は、学習セットとテスト セットを指定する交差検証分割オブジェクトです。
コスト行列を作成します。不整脈がある患者を不整脈なしのクラスに誤分類した場合はコストを高くし、不整脈がない患者を不整脈ありのクラスに誤分類した場合の 5 倍にします。正しく分類した場合、コストは発生しません。行は真のクラスを、列は予測したクラスを表します。コストを考慮する分析を実行するときは、クラスの順序を指定することをお勧めします。
cost = [0 1;5 0];
ClassNames = {'NoArrhythmia','WithArrhythmia'};50 本の分類木がある 2 つのブースティング アンサンブルに学習をさせます。一方では AdaBoostM1 を、もう一方では LogitBoost を使用します。欠損値がデータ セットに含まれているので、代理分岐を使用するように指定します。コスト行列を使用してモデルを学習させます。
t = templateTree('Surrogate','on'); numTrees = 50; C1 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','AdaBoostM1', ... 'NumLearningCycles',numTrees,'Learners',t, ... 'Cost',cost,'ClassNames',ClassNames); C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','LogitBoost', ... 'NumLearningCycles',numTrees,'Learners',t, ... 'Cost',cost,'ClassNames',ClassNames);
C1 と C2 は学習済みの ClassificationEnsemble モデルです。
関数 loss を使用してテスト データの分類損失を計算します。LossFun を 'classifcost' と指定して誤分類コストを計算します。
L1 = loss(C1,X(idxTest,:),Y(idxTest),'LossFun','classifcost')
L1 = 0.6642
L2 = loss(C2,X(idxTest,:),Y(idxTest),'LossFun','classifcost')
L2 = 0.8018
AdaBoostM1 アンサンブル (C1) の誤分類コストの方が LogitBoost アンサンブル (C2) のコストよりも小さくなっています。
この違いが統計的に有意であるかどうかを検定します。コストを考慮する漸近的な尤度比検定 (コスト行列を渡す場合の既定) を実行します。コスト行列を与えて、"p" 値と誤分類コストを返します。
[h,p,e1,e2] = compareHoldout(C1,C2,X(idxTest,:),X(idxTest,:),Y(idxTest),... 'Cost',cost,'ClassNames',ClassNames)
h = logical
0
p = 0.1180
e1 = 0.6698
e2 = 0.8093
h = 0 なので、2 つのモデルの予測精度が等しいという帰無仮説は棄却できません。
関数 loss は事前確率 (学習済みモデルの Prior プロパティに格納) で正規化された観測値の重みを使用しますが、関数 compareHoldout は観測値の重みと事前確率を使用しません。そのため、関数 loss で計算される誤分類コストの値 (L1 および L2) は、関数 compareHoldout で計算される値 (e1 および e2) と異なる場合があります。
予測子変数 (特徴量) のサブセットをより大きいセットから選択して、分類モデルの複雑さを減らします。そして、2 つのモデルの標本外精度を統計的に比較します。
ionosphere データ セットを読み込みます。
load ionosphere;データを学習セットとテスト セットに均等に分割します。
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP は、学習セットとテスト セットを指定する交差検証分割オブジェクトです。
AdaBoostM1 とすべての予測子セットを使用して、100 個のブースティング分類木があるアンサンブルを学習させます。各予測子について重要度を調べます。
t = templateTree('MaxNumSplits',1); % Weak-learner template tree object C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','AdaBoostM1',... 'Learners',t); predImp = predictorImportance(C2); figure; bar(predImp); h = gca; h.XTick = 1:2:h.XLim(2)
h =
Axes with properties:
XLim: [-0.2000 35.2000]
YLim: [0 0.0090]
XScale: 'linear'
YScale: 'linear'
GridLineStyle: '-'
Position: [0.1300 0.1100 0.7750 0.8150]
Units: 'normalized'
Show all properties
title('Predictor Importance'); xlabel('Predictor'); ylabel('Importance measure');
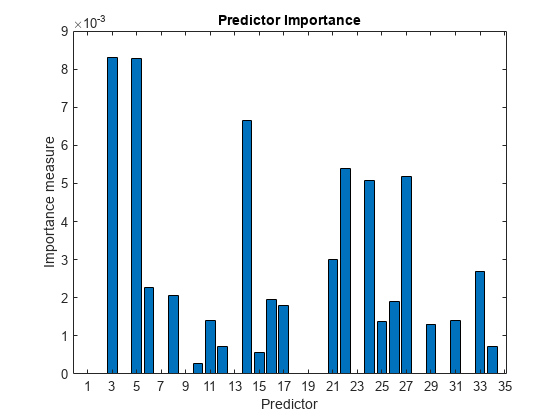
重要度が上位 5 番目までの予測子を識別します。
[~,idxSort] = sort(predImp,'descend');
idx5 = idxSort(1:5);AdaBoostM1 と上位 5 番目までの重要度をもつ予測子を使用して、100 本のブースティング分類木がある別のアンサンブルに学習をさせます。
C1 = fitcensemble(X(idxTrain,idx5),Y(idxTrain),'Method','AdaBoostM1',... 'Learners',t);
2 つのモデルの予測精度が同じであるかどうかを検定します。C1 には縮小したテスト セット予測子データを、C2 には完全なテスト セット予測子データを指定します。
[h,p,e1,e2] = compareHoldout(C1,C2,X(idxTest,idx5),X(idxTest,:),Y(idxTest))
h = logical
0
p = 0.7744
e1 = 0.0914
e2 = 0.0857
h = 0 なので、2 つのモデルの予測精度が等しいという帰無仮説は棄却できません。この結果から、単純なアンサンブル C1 の方が有利であることがわかります。
入力引数
名前と値の引数
出力引数
制限
compareHoldoutは、線形分類モデルまたはカーネル分類モデル (つまりClassificationLinearまたはClassificationKernelモデル オブジェクト) から構成される ECOC モデルを比較しません。線形分類モデルまたはカーネル分類モデルから構成されるClassificationECOCモデルを比較するには、代わりにtestcholdoutを使用します。同様に、
compareHoldoutはClassificationLinearまたはClassificationKernelモデル オブジェクトを比較しません。これらのモデルを比較するには、代わりにtestcholdoutを使用します。
詳細
"マクネマー検定" は、標本のペアに依存関係があることによって生じる問題に対処して 2 つの母集団比率を比較する仮説検定です。
2 つの分類モデルの予測精度を比較する方法の 1 つは、次のとおりです。
データを学習セットとテスト セットに分割します。
学習セットを使用して両方の分類モデルを学習させます。
テスト セットを使用してクラス ラベルを予測します。
次の図のような 2 x 2 の表に結果を要約します。
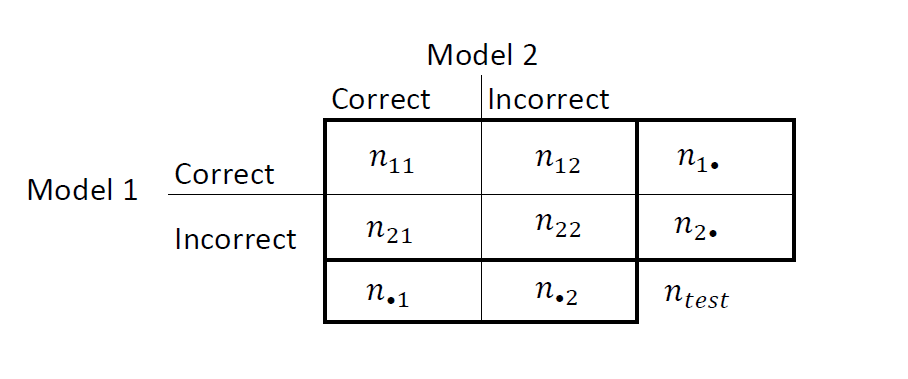
nii は、一致するペアの数、つまり両方のモデルで同じように (正しくまたは誤って) 分類される観測の数です。i ≠ j の場合の nij は、一致しないペアの数、つまりモデルでさまざまに (正しくまたは誤って) 分類される観測の数です。
モデル 1 および 2 の誤分類率は、それぞれ および です。2 つのモデルの精度を比較する両側検定は、次のようになります。
この帰無仮説は母集団の周辺確率が同等であることを示しているので、帰無仮説は に縮小されます。また、この帰無仮説では、N12 が (n12 + n21,0.5) の二項分布になります。[1]
以上は、マクネマー検定のバリエーションとして利用できる "漸近"、"厳密条件" および "mid-p 値" マクネマー検定の基礎となります。以下の定義は、利用可能なバリアントの概要です。
漸近 ― 漸近マクネマー検定の統計量と (有意水準 α に対する) 棄却域は、次のようになります。
片側検定の場合、検定統計量は次のようになります。
である場合 (Φ は標準ガウス累積分布関数)、H0 は棄却されます。
両側検定の場合、検定統計量は次のようになります。
である場合 ( は x で評価した χm2 累積分布関数)、H0 は棄却されます。
漸近検定では、大標本理論、具体的には二項分布に対するガウス近似が必要です。
厳密条件 — 厳密条件マクネマー検定の統計量と (有意水準 α に対する) 棄却域は、次のようになります ([4]、[5])。
片側検定の場合、検定統計量は次のようになります。
である場合 ( は x で評価した、標本サイズが n、成功確率が p の二項累積分布関数)、H0 は棄却されます。
両側検定の場合、検定統計量は次のようになります。
である場合、H0 は棄却されます。
厳密条件検定では、常にノミナル カバレッジが達成されます。シミュレーション研究[2]によると、この検定は保守的であり、他のバリアントに比べて統計的検出力が不足しています。検定標本が小規模な場合や非常に離散的な場合は、mid-p 値検定の使用を検討してください ([1], Ch. 3.6.3)。
mid-p 値検定 — mid-p 値マクネマー検定の統計量と (有意水準 α に対する) 棄却域は、次のようになります ([3])。
片側検定の場合、検定統計量は次のようになります。
である場合 ( と はそれぞれ x で評価した、標本サイズが n、成功確率が p の二項累積分布関数および二項確率密度関数)、H0 は棄却されます。
両側検定の場合、検定統計量は次のようになります。
である場合、H0 は棄却されます。
mid-p 値検定は、厳密条件検定の過度に保守的な挙動に対処します。シミュレーション研究[2]によると、この検定はノミナルの被覆が達成され、統計的検出力が優れています。
ヒント
コストを考慮しない特徴選択を実行する方法の 1 つとして、次のようなものがあります。
あるいは、2 つのモデルの精度に有意な差があるかどうかを評価することもできます。この評価を実行するには、手順 4 から
'Alternative','less'の指定を削除します。compareHoldoutの実行により両側検定が実行され、h = 0は、2 つのモデル間の精度の差を示す十分な証拠がないことを示します。コストを考慮する検定では数値を最適化しますが、これには追加の計算リソースが必要です。尤度比検定では、ある区間におけるラグランジュ乗数の根を求めるため間接的に数値を最適化します。データ セットによっては、根が区間の境界付近にある場合、メソッドが失敗する可能性があります。このため、Optimization Toolbox のライセンスがある場合は、コストを考慮するカイ二乗検定を代わりに実行することを検討してください。詳細については、
CostTestおよびコストを考慮する検定を参照してください。
代替機能
真のクラス ラベルのセットを予測するときに 2 つのクラス ラベルのセットについて精度を直接比較するには、testcholdout を使用します。